Don't miss @DeepSpeedAI virtual office hours on May 26 at 12:00 PM America/New_York to ask questions of @toh_tana member of DeepSpeed TSC & get the latest recent key updates, including AutoSP (sequence parallel), AutoEP (expert parallel), and AutoTP (tensor parallel).
Good news! Ulysses Sequence Parallelism from the Snowflake AI Research and the Deepspeed teams has been integrated into @huggingface Trainer, Accelerate and TRL
For extensive details please see this writeup:
https://t.co/2xDWUk8p3V
Thanks a lot to @krasul for helping make it happen. Also the others in the HF team who helped with integration.
New @DeepSpeedAI updates make large-scale multimodal training simpler and more memory-efficient.
Our latest blog introduces a PyTorch-identical backward API that helps code multimodal training loops easy, plus low-precision model states (BF16/FP16) that can reduce peak memory by up to 40% when combined with torch.autocast.
🖇️ Read the full post for details: https://t.co/sSHMGhRixV
#DeepSpeed #PyTorch #MemoryEfficiency #MultimodalTraining #OpenSourceAI
Zhipeng (Jason) Wang, PhD (@PKUWZP) explains how @DeepSpeedAI supports ML training research and why joining PyTorch Foundation benefits researchers and developers working on AI training workloads.
🔗https://t.co/6FfXB98gb2 #PyTorch#DeepSpeed#OpenSourceAI#AIInfrastructure
Step into the future of AI at #PyTorchCon 2025, Oct 22–23 in San Francisco 🔥 Join the DeepSpeed keynote and technical talks. Register: https://t.co/6iogY2eetT
+ Oct 21 co-located events: Measuring Intelligence, Open Agent & AI Infra Summits / Startup Showcase & PyTorch Training
📢 Yesterday at USENIX ATC 2025, Xinyu Lian from UIUC SSAIL Lab presented our paper on Universal Checkpointing (UCP). UCP is a new distributed checkpointing system designed for today's large-scale DNN training, where models often use complex forms of parallelism, including data, tensor, pipeline, and expert parallelism.
Existing checkpointing systems struggle in this setting because they are tightly coupled to specific training strategies (e.g., ZeRO-style data parallelism or 3D model parallelism), which break down when the training configs need to dynamically reconfigure over time. This makes it difficult to have resilient and fault-tolerant training.
UCP solves this by decoupling distributed checkpointing from parallelism strategies. Our design introduces a unified checkpoint abstraction -- atomic checkpoint, and a full pattern matching-based transformation pipeline, which enables scalable and low-overhead checkpointing with reconfigurable parallelism across arbitrary model sharding strategies.
We show that UCP supports state-of-the-art models trained with hybrid 3D/4D parallelism (ZeRO, TP, PP, SP) while incurring less than 0.001% overhead of the total training time.
UCP is fully open-sourced in DeepSpeed. It has been adopted by Microsoft, BigScience, UC Berkeley and others for large-scale model pre-training and fine-tuning, including Phi-3.5-MoE (42B), BLOOM (176B), and many more. It also has been selected for presentation at PyTorch Day 2025 and FMS 2025(the Future of Memory and Storage).
Big thanks to the amazing collaborators from Microsoft and Snowflake: @samadejacobs , @LevKurilenko, @MasahiroTanaka, @StasBekman , and @TunjiRuwase.
🔗 Project: https://t.co/j7VllIQCAS
📄 Paper: https://t.co/23yoXYmcrh
💻 Code: https://t.co/H4qyEyfQ0q
📚 Tutorial: https://t.co/lcxkv5FNxl
#ATC2025 #LLM #Checkpointing #SystemsForML #DeepLearning #DistributedTraining #UIUC #DeepSpeed
📢 Yesterday at USENIX ATC 2025, Xinyu Lian from UIUC SSAIL Lab presented our paper on Universal Checkpointing (UCP). UCP is a new distributed checkpointing system designed for today's large-scale DNN training, where models often use complex forms of parallelism, including data, tensor, pipeline, and expert parallelism.
Existing checkpointing systems struggle in this setting because they are tightly coupled to specific training strategies (e.g., ZeRO-style data parallelism or 3D model parallelism), which break down when the training configs need to dynamically reconfigure over time. This makes it difficult to have resilient and fault-tolerant training.
UCP solves this by decoupling distributed checkpointing from parallelism strategies. Our design introduces a unified checkpoint abstraction -- atomic checkpoint, and a full pattern matching-based transformation pipeline, which enables scalable and low-overhead checkpointing with reconfigurable parallelism across arbitrary model sharding strategies.
We show that UCP supports state-of-the-art models trained with hybrid 3D/4D parallelism (ZeRO, TP, PP, SP) while incurring less than 0.001% overhead of the total training time.
UCP is fully open-sourced in DeepSpeed. It has been adopted by Microsoft, BigScience, UC Berkeley and others for large-scale model pre-training and fine-tuning, including Phi-3.5-MoE (42B), BLOOM (176B), and many more. It also has been selected for presentation at PyTorch Day 2025 and FMS 2025(the Future of Memory and Storage).
Big thanks to the amazing collaborators from Microsoft and Snowflake: @samadejacobs , @LevKurilenko, @MasahiroTanaka, @StasBekman , and @TunjiRuwase.
🔗 Project: https://t.co/j7VllIQCAS
📄 Paper: https://t.co/23yoXYmcrh
💻 Code: https://t.co/H4qyEyfQ0q
📚 Tutorial: https://t.co/lcxkv5FNxl
#ATC2025 #LLM #Checkpointing #SystemsForML #DeepLearning #DistributedTraining #UIUC #DeepSpeed
PyTorch Day France marked the launch of a global PyTorch Day series—and the announcement of a major milestone: PyTorch Foundation is now an umbrella foundation. First new projects: @vllm_project + @DeepSpeedAI.
Next Stop: PyTorch Day China, June 7 🇨🇳 https://t.co/br36cD3mL7
#PyTorch #OpenSourceAI #vLLM #DeepSpeed
PyTorch Foundation has expanded into an umbrella foundation. @vllm_project and @DeepSpeedAI have been accepted as hosted projects, advancing community-driven AI across the full lifecycle.
Supporting quotes provided by the following members: @AMD, @Arm, @AWS, @Google, @Huawei, @huggingface, @IBM, @Intel, @LightningAI, @Meta, @NVIDIA, and @Snowflake.
🔗💡 Read the full announcement: https://t.co/l55YFhlAOx
#PyTorchFoundation #PyTorch #OpenSourceAI #vLLM #DeepSpeed
PyTorch Foundation has expanded into an umbrella foundation. @vllm_project and @DeepSpeedAI have been accepted as hosted projects, advancing community-driven AI across the full lifecycle.
Supporting quotes provided by the following members: @AMD, @Arm, @AWS, @Google, @Huawei, @huggingface, @IBM, @Intel, @LightningAI, @Meta, @NVIDIA, and @Snowflake.
🔗💡 Read the full announcement: https://t.co/l55YFhlAOx
#PyTorchFoundation #PyTorch #OpenSourceAI #vLLM #DeepSpeed
This is pretty neat. They insert into torch.compile and insert some profile-guided optimizations as well as a bunch of other specific optimizations like offloading.
Since torch.compile is all in Python all their compiler passes are fairly accessible too!
https://t.co/gxpcGQlILf
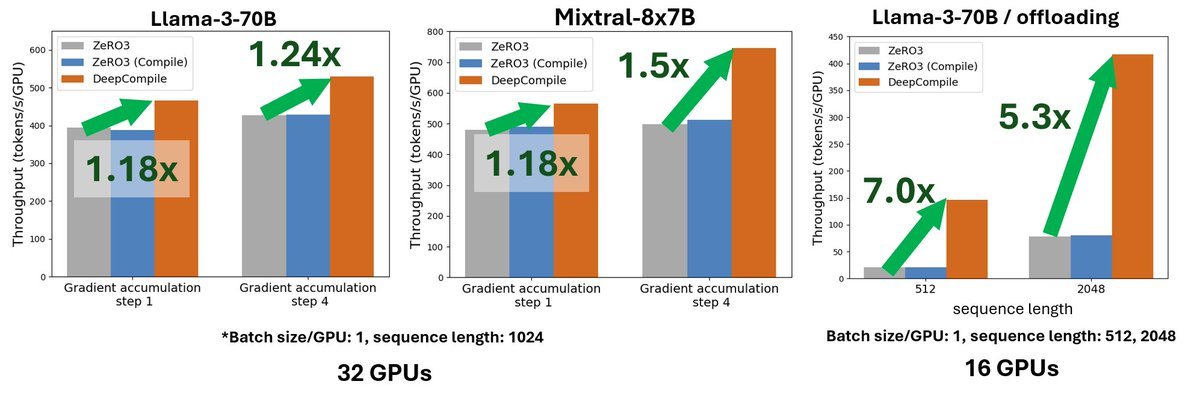
AutoTP + ZeRO Training for HF Models
- Enhance HF post-training with larger models, batches, & contexts
- 4x faster LLAMA3 fine-tuning with TP=2 vs TP=1
- No code changes needed
Blog: https://t.co/ZlCG2Aq5K5
🚀 Excited to introduce DeepSpeed, a deep learning optimization library from @Microsoft! It simplifies distributed training and inference, making AI scaling more efficient and cost-effective.
Learn more 👉 https://t.co/LIFjumeAgb
#DeepSpeed#AI#OpenSource#LFAIData
Microsoft Research congratulates Yasuyuki Matsushita on being named a 2025 IEEE Fellow for his outstanding contributions to photometric 3D modeling and computational photography. https://t.co/HjpHJfZLfs
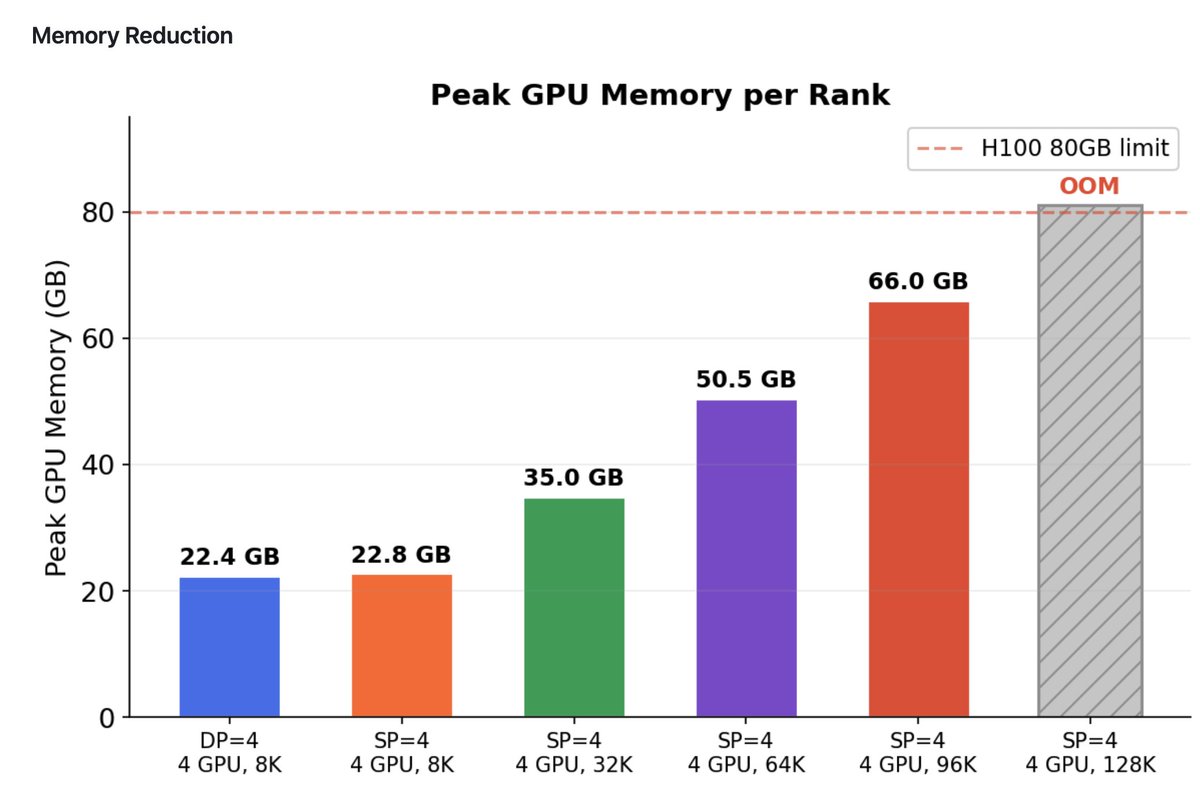
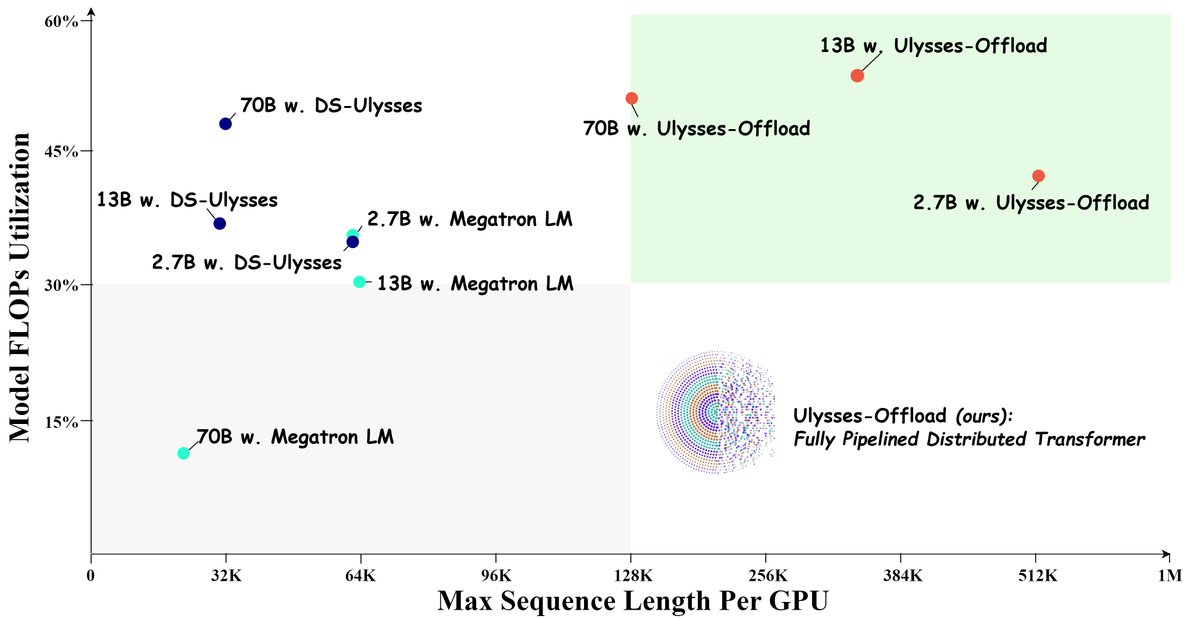
🚀Introducing Ulysses-Offload🚀
- Unlock the power of long context LLM training and finetuning with our latest system optimizations
- Train LLaMA3-8B on 2M tokens context using 4xA100-80GB
- Achieve over 55% MFU
Blog: https://t.co/AoGSqyKb1E
Tutorial: https://t.co/6YHSA5iOop
【 Microsoft Research Asia - Tokyo を設立】
アジア太平洋地域における人工知能研究とイノベーションの推進を強化するため、東京に新たな研究拠点である「Microsoft Research Asia-Tokyo(マイクロソフト リサーチ アジア東京)」を設立したことを発表します。
https://t.co/jqbMFFZyQ7