PhD Comp. Science (Texas A&M University), R&D expertise and experience in advanced large-scale big data (graph) analytics, machine (deep) learning, and robotics
#SC20 starts today! It is exciting to have our work on AI/HPC-enabled drug design for CoVID19 in the prestigious Gordon Bell Special Prize Finalist. Congratulations to our team, “sleepless” night in a chaotic Summer not in vain!
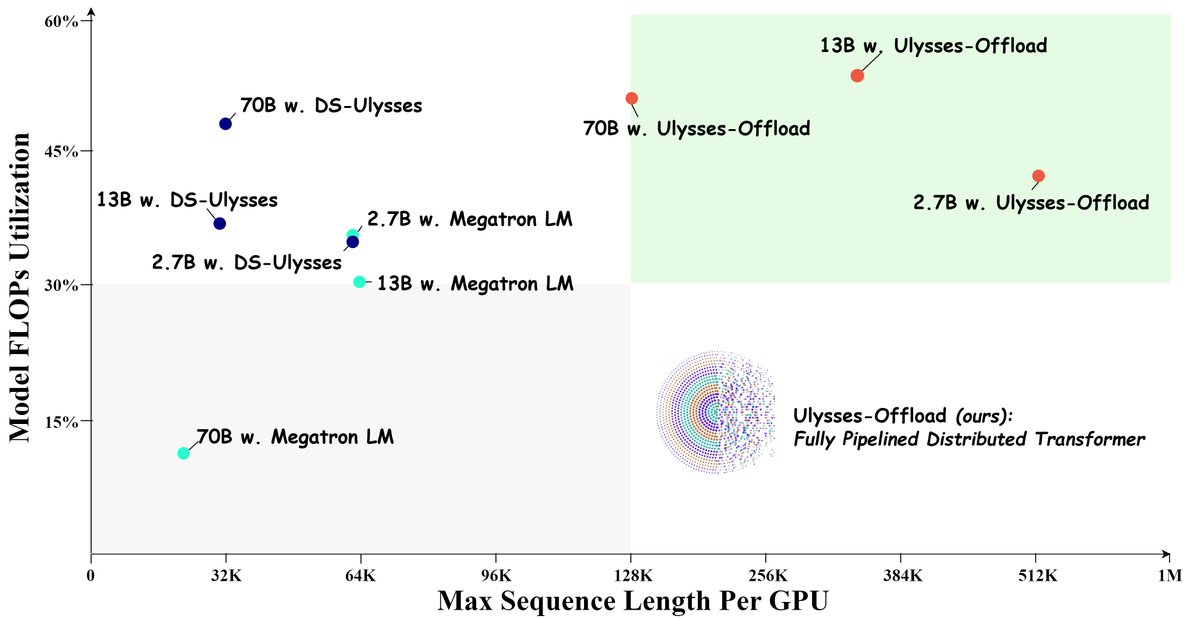
🚀Introducing Ulysses-Offload🚀
- Unlock the power of long context LLM training and finetuning with our latest system optimizations
- Train LLaMA3-8B on 2M tokens context using 4xA100-80GB
- Achieve over 55% MFU
Blog: https://t.co/AoGSqyKb1E
Tutorial: https://t.co/6YHSA5iOop
Announcing that DeepSpeed now runs natively on Windows. This exciting combination unlocks DeepSpeed optimizations to Windows users and empowers more people and organizations with AI innovations.
- HF Inference & Finetuning
- LoRA
- CPU Offload
Blog: https://t.co/LeNHlDZH3C
Introducing Universal Checkpointing for boosting training efficiency.
- Change parallelism (PP, SP, TP, ZeRO-DP) or GPU count mid-stream
- Improve resilience by scaling down to healthy nodes💪
- Increase throughput by scaling up to elastic nodes🚀
Blog: https://t.co/qL32e5i1D2
If you were holding off to try @MSFTDeepSpeed ZeRO++ it looks like deepspeed@master should work well now:
https://t.co/SOlRIRqOB6
ZeRO++'s main feature is allowing you to use a hybrid approach if you can fit a model on a single node of 8 gpus. So it takes benefit of the super fast NVLink within the node and only needs to reduce grads across nodes over the slow link.
So if in your workflow the slow inter-node network was impacting your tflops, enabling ZeRO++ should give you a sizeable boost. The number would very depend on your situation but in my experiments I saw 5%+ boost with a 7b llama.
This is similar to Hybrid FSDP.
To try see: https://t.co/WdU8U5tjuX
I was talking about the hybrid solution - I'm yet to try the quantized weights/grads also offered by ZeRO++ which should speed up things even further as there will be even less stress on the network with those.
Just remember until the next release is made you want deepspeed@master
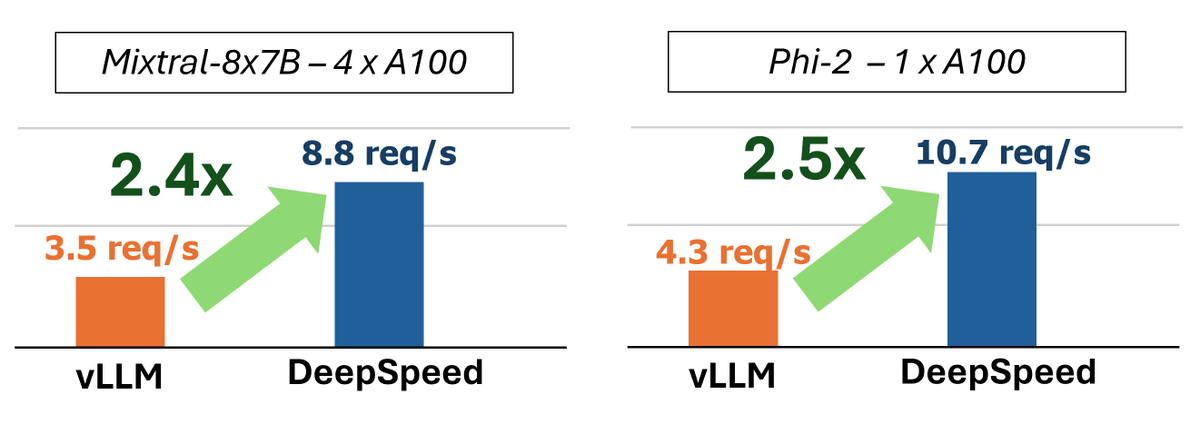
Introducing Mixtral, Phi2, Falcon, and Qwen support in #DeepSpeed-FastGen!
- Up to 2.5x faster LLM inference
- Optimized SplitFuse and token sampling
- Exciting new features like RESTful API and more!
For more details: https://t.co/386OvJtQLk
#DeepSpeeed#AI
🚀 Excited to announce our paper "ZeRO++: Extremely Efficient Collective Communication for Large Model Training" has been accepted at #ICLR2024!
🔍 ZeRO++ significantly reduces communication volume by 4x, achieving up to 3.3x speedup.
https://t.co/a9OS4rD0rN
#DeepSpeed#AI
We're rolling out new features and improvements that developers have been asking for:
1. Our new model GPT-4 Turbo supports 128K context and has fresher knowledge than GPT-4. Its input and output tokens are respectively 3× and 2× less expensive than GPT-4. It’s available now to all developers in preview.
2. Assistants API and new tools (Retrieval, Code Interpreter) will help developers build world-class AI assistants within their own apps.
3. The platform is becoming multimodal. GPT-4 Turbo with Vision, DALL·E 3, and text-to-speech are all now available to developers.
Oh… and we’re doubling GPT-4 rate limits. https://t.co/BMnsBAHorI
Introducing DeepSpeed-FastGen 🚀
Serve LLMs and generative AI models with
- 2.3x higher throughput
- 2x lower average latency
- 4x lower tail latency
w. Dynamic SplitFuse batching
Auto TP, load balancing w. perfect linear scaling, plus easy-to-use API
https://t.co/iizM71bjqj
🚀Exciting new updates on #DeepSpeed ZeRO-Inference with 20X faster generation!
- 4x lesser memory usage through 4-bit weight quantization with no code change needed.
- 4x larger batch sizes through KV cache offloading.
Available in DeepSpeed v0.10.3: https://t.co/v24qV42rWC
Want to train 1 million token context lengths (all 7 of the Harry Potter books!📚) on a GPT-like model w. 64 GPUs?
Announcing DeepSpeed-Ulysses🚀
This release enables highly efficient and scalable LLM training with extremely long sequence lengths🤯
https://t.co/byWeQeeTed
We trained an AI using process supervision — rewarding the thought process rather than the outcome — to achieve new state-of-art in mathematical reasoning. Encouraging sign for alignment of advanced AIs: …https://t.co/ryaODghohn
@Livermore_Lab@bkspears9 Sorry I missed this, Nigerian presidential election polluted my Twitter feed! Good job @bkspears9 and the NIF team, hope you win!