Senior Research Scientist @ DeepMind. I work on LLM post-training, focusing on improving training data. Prior to that, I worked on AlphaFold.
Typos are my own.
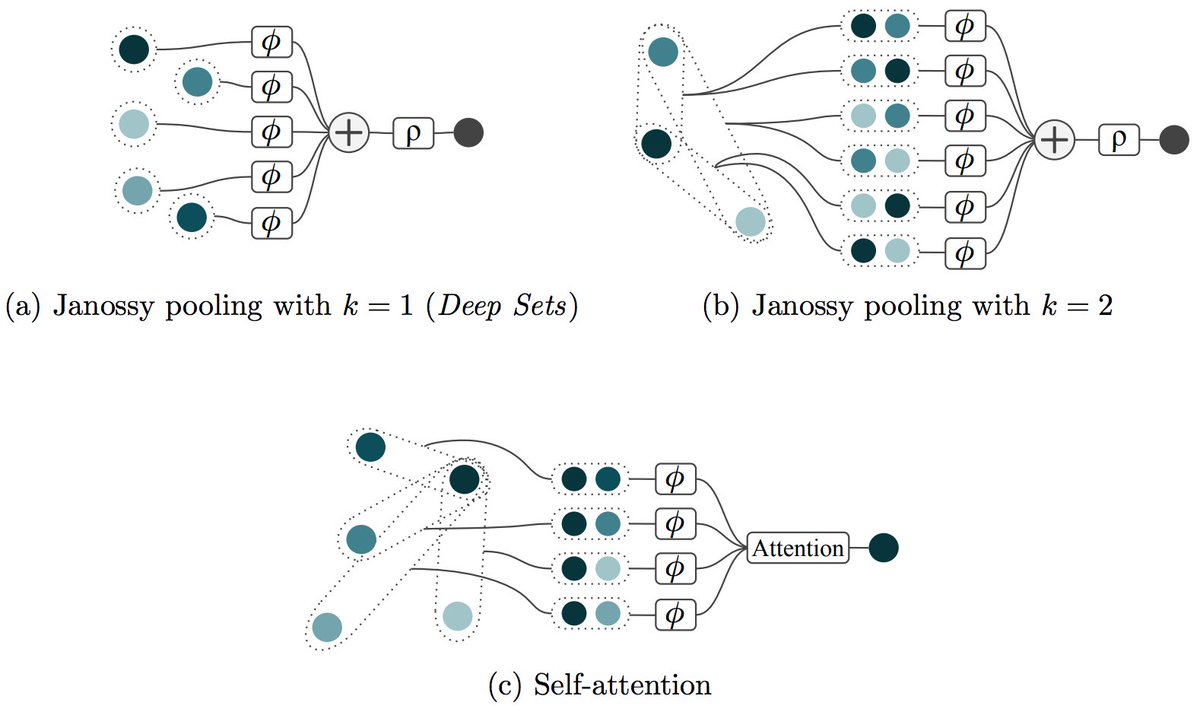
A year ago I asked: Is there more than Self-Attention and Deep Sets? - and got very insightful answers. 🙏 Now, Ed, Martin and I wrote up our own take on the various neural networks architectures for sets.
Have a look and tell us what you think! :)
➡️https://t.co/Z1aprTcLQV ☕️
Both Max-Pooling (e.g. DeepSets) and Self-Attention are permutation invariant/equivariant neural network architectures for set-based problems. I am aware of a couple of variations for both of these. Are there additional, fundamentally different architectures for sets? 🤔
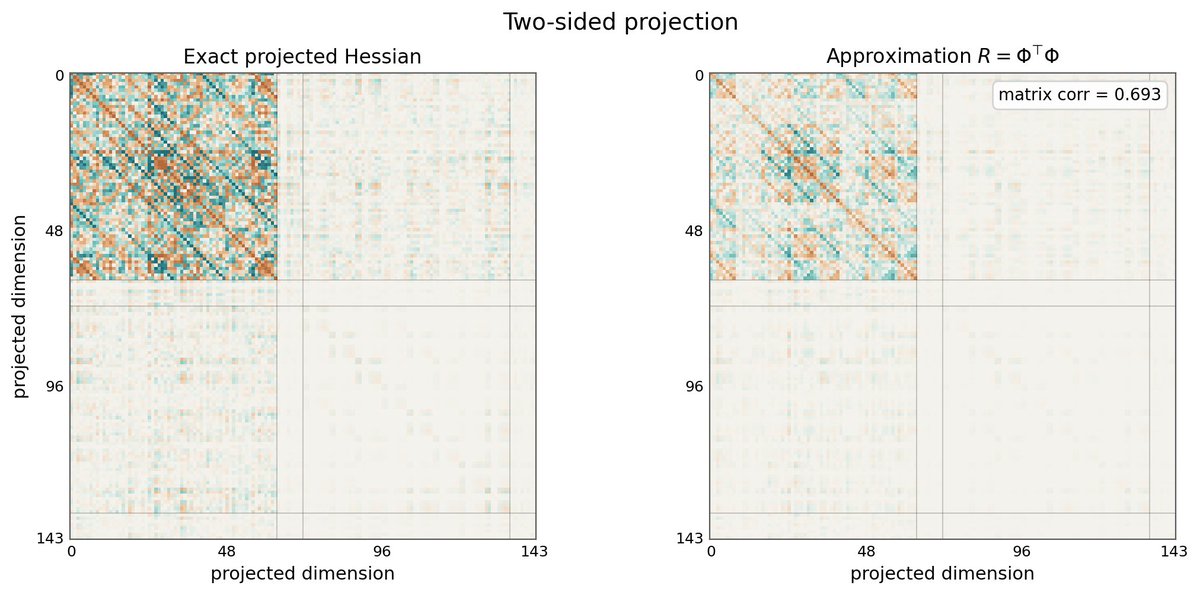
I wrote a blog post trying to understand TrackStar, a gradient-based method tracing LLM predictions to influential training examples.
Mostly: take the main equation, read it from right to left, and poke at the pieces with a small MNIST toy example. 🙂
☕️ https://t.co/JCWblqh956
Our Apple ML Research team in Barcelona is looking for a PhD intern! 🎓
Curiosity-driven research 🧠 with the goal to publish 📝
Topics: Confidence/uncertainty quantification and reliability of LLMs 🤖
Apple here: https://t.co/ZiN3ecWGo7
Graphs , Sets, Universality
We put more work into this and are presenting it via the ICLR blogpost track (thanks to organisers and reviewers!). Have a read and let us know what you think:
https://t.co/MtpPYYUfTm
better in light mode💡, dark mode🌙 messes with the latex a bit
Text-to-image diffusion models seem to have a good idea of geometry. Can we extract that geometry? Or maybe we can nudge these models to create large 3D consistent environments? Here's a blog summarizing some ideas in this space :)
https://t.co/INlMuslCdU
I have recently had a range of very insightful conversations with @PetarV_93 about graph neural networks, networks on sets, universality and how ideas have spread in the two communities. This is our write up, feedback welcome as always! :)
➡️https://t.co/vbmCGHBHxd ☕️
New blog post! Find out:
- what reconstructing masked images and our brains have in common,
- why reconstructing masked images is a good idea for learning representations,
- what makes a good mask and how to learn one
https://t.co/bFrmQvITEz
Graph neural networks often have to globally aggregate over all nodes. How we do this can have a significant impact on performance 🎯. After we recently finished a project on this, I wrote a blog post on this topic. Let me know what you think! :)
➡️https://t.co/OGJJAF9w9C ☕️
Molecule Generation in 3D with Equivariant Diffusion (https://t.co/4ZgiHdswER). Very happy to share this project (the last of my PhD woohoo 🥳) and a super nice collab with @vgsatorras @ClementVignac (equal contrib shared among three of us) and of course @wellingmax
@newplatonism Depends, are you happy with treating cars as point masses in vacuum? :P
More seriously: people do work on making the L/H-based NNs more general (like allowing for friction & external forces), but, to my understanding, it's still mostly constrained to physical particle systems
Emmy Noether connected symmetries and conserved quantities in physics - how is this related to exploiting symmetries with neural networks? 🤔
I've tried to answer this question in a blog post (no background knowledge required!):
➡️https://t.co/VfxMu3fkAK ☕️
@william_woof@andrewwhite01 +1; also, this equivalence does not need to be obvious at all. In some cases, like with max(), it might even seem counterintuitive that the function >can< be written as a sum-decomposition (ie in a Deep-Sets form)