GenomicOS: The Operating System for Life
Decode your genome. Run it locally. Own your future.
AI-driven insights with zero data selling, full sovereignty, and built-in longevity intelligence.
Gene editing is finally here.
And it's targeting the biggest killer in the world. Heart disease.
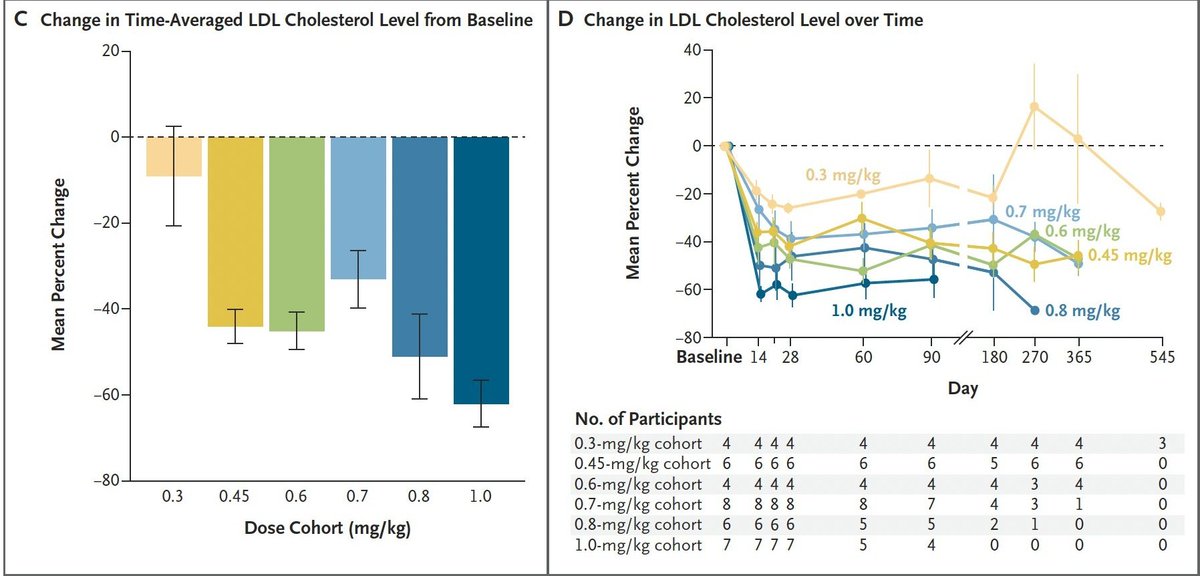
Eli Lilly $LLY just released data for a gene therapy called VERVE-102.
It completely changes how we treat high cholesterol.
Instead of taking a pill every day, you get one single IV infusion. The medicine travels directly to your liver. It permanently turns off the specific gene that causes high LDL cholesterol.
The early trial results are incredible. Patients experienced a massive 60% drop in their LDL cholesterol.
Think about what GLP-1 drugs did for obesity.
Five years ago, Ozempic was "just Phase 2 data." People said the side effects were unclear. The long-term outcomes were unknown.
Now it's a $50 billion/year drug that changed how we treat obesity.
GLP-1s rewrote obesity. VERVE-102 could rewrite heart disease.
Medicine is moving faster than most people realize.
Comprehensive evaluation of artificial intelligence-empowered approaches for protein–aptamer complex prediction
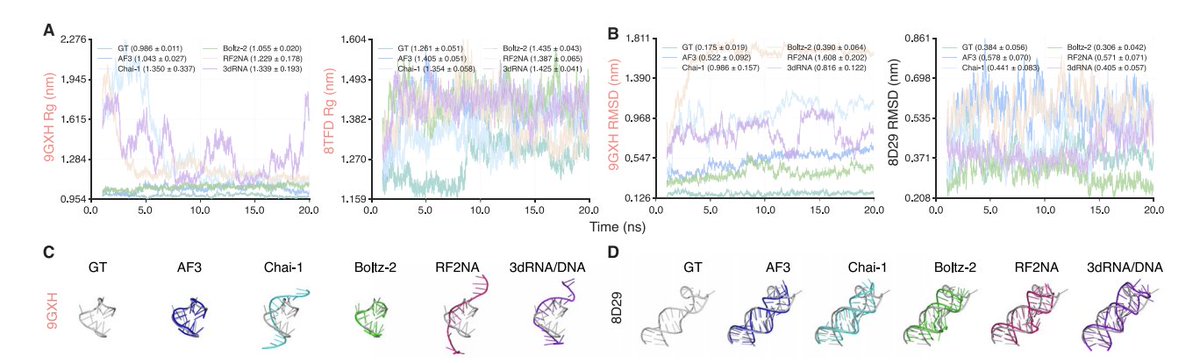
1. The review benchmarks four AI structure predictors (AlphaFold3, Chai-1, Boltz-2, RoseTTAFold2NA) plus a template-based method (3dRNA/DNA) on protein–aptamer complexes, focusing not only on geometric accuracy but also on MD-based stability and MM/GBSA energetic consistency.
2. A key finding is limited aptamer specificity: across 11 curated post-AF3-cutoff PDB complexes, predicted binding free energies for native (positive) pairs often overlapped with intentionally mismatched protein–aptamer pairs, suggesting models can generate “bound-like” complexes even for non-cognate sequences.
3. AF3 was additionally stress-tested with shuffled-sequence controls (same length and nucleotide composition; ≥80% positions changed). Even these nonbiological aptamers frequently produced complexes with seemingly reasonable MM/GBSA trends, reinforcing that sequence-level specificity is not reliably captured.
4. The benchmark design is a central contribution: it includes a strict nonbinding control set (rotated aptamer assignment with constraints to avoid homologous/cognate swaps, e.g., thrombin aptamers not cross-paired) and evaluates 25 samples per target (5 seeds × 5 diffusion samples) under a matched sampling regime across AF3/Chai-1/Boltz-2.
5. Interface accuracy was assessed with iLDDT (OpenStructure). Boltz-2 achieved the highest overall iLDDT distribution on the full set, but accuracy dropped on complexes outside its training window; several hard targets (e.g., 8TFD, 9GXH) remained challenging across models.
6. Interfacial hydrogen-bond networks were evaluated against experimental structures (HBPLUS precision/recall/F1). Even when total H-bond counts looked similar, models often missed native H-bonds and introduced non-native ones, indicating partial recovery of interaction determinants rather than faithful interface reconstruction.
7. MD simulations (20 ns, CHARMM36m, standardized NaCl environment) showed many predicted complexes remain physically stable (Rg/RMSD, persistent contacts), including mismatched negatives—highlighting that “stability in MD” does not imply correct molecular recognition.
8. Confidence calibration is flagged as a practical issue: comparing ipTM vs iLDDT shows that high internal confidence does not guarantee accurate protein–aptamer interfaces; Boltz-2 in particular tended to assign uniformly high ipTM even when iLDDT was low, consistent with overconfidence in this setting.
9. Ion inclusion was tested for ion-containing complexes by providing explicit ions to AF3/Chai-1/Boltz-2. Interface accuracy changed little (small improvement only for Boltz-2), and predicted ion placement often disagreed with experimental arrangements, implying ion-dependent aptamer folding/recognition is still not well captured by current pipelines.
📜Paper: https://t.co/aHvh3ym4fJ
#Aptamers #ProteinStructure #ComplexPrediction #AlphaFold3 #RoseTTAFold #Benchmarking #MolecularDynamics #ComputationalBiology #DrugDiscovery #NucleicAcids
Eli Lilly has done it.
They've gone and made what seems to be a powerful, permanent gene therapy for LDL cholesterol.
That means they'll be able to effectively prevent most heart disease with a single infusion!
I just sequenced a human genome to 30× coverage entirely at home.
As far as I know, this is the first time this has been done.
I didn’t step foot in a lab once. Every step - from saliva collection, to running the sequencer - took place in a single room with a dining table + kitchenette.
Six weeks ago, I had never done wet lab biology before.
I used an Oxford Nanopore P2 Solo - the only commercially available sequencing device portable enough to do 30x human genome sequencing at home.
Biggest takeaway - I could build something that combined software, hardware, and molecular biology far faster than I thought was possible.
I can name >100 specific instances where AI helped me solve a technical problem that would previously have blocked me because I lacked access to a domain expert.
For example: how do I save my sequencing run when my DNA extraction yield is 4x lower than I need it to be, and I have this limited set of reagents to hand?
To make this work, I had to navigate multiple disciplines:
- writing software to monitor sequencing runs and orchestrate remote GPU infra for basecalling
- learning + executing 5 hour long molecular biology protocols
- building a hardware device to quantify DNA concentration
Apologies for the hyperbole, but I feel super lucky to be living in 2026.
A few weeks ago I decided to sequence a human genome to 30x at home.
Then I actually did it. And I did it really quickly.
If anyone is down to get me a WGS (whole genome sequencing) kit, I can also offer to analyze your DNA!
Best motivation to dive deep into bioinformatics 🧬
Check out Soma on @taikainetwork for the #DeSci@infinitacity Hackathon!
In the future we will be building deeper integrations with @Genomic_OS allowing users to submit research questions with ease.
Front-end heavy lifting was done by @memehalis
Smart contracts deployed on Ethereum Base Sepolia.
https://t.co/3GDpnL9lf7 #taikai
Hacker culture is one of humanity's last hopes to improve society, as hackers deeply understand these systems.
Register for @infinitacity Demo Day: https://t.co/oUXNuPOZUB
It has been 3 months in SF since April right after 2 months of @infinitacity
Built a knowledgeable network around personal genomics and leveling the genetic playing field. Grateful for the convos shaping @Genomic_os & the broader bioinformatics arc.
@memehalis is stepping in as VP in SF till August while part of @CityOfViva
Planning to return to SF in October… or maybe @zucity_japan
Either way, fired up to keep building in longevity biotech with this electric community.
https://t.co/HEFeDg2vfL AI hackathon was one of the top and longest bio-ai-hackathons in 2025, and we won it! Please, take a look at our holy-bio-mcp servers! We continue developing and empowering your AI-assisted tools and AI agents even more! https://t.co/KbpRwF6pmW
This meeting at Lighthaven has convinced me that both artificial wombs and gene editing of human embryos using stem cell technology are much closer than I previously thought.
I'm not involved in either area but it's great to speak to the researchers at the frontier.