Interested in learning how to run RL at scale? Here are the best resources to read…
Research on Scaling RL
1. The Art of Scaling RL compute for LLMs: https://t.co/PGjI6Gwgv0
2. Scaling Behaviors of LLM RL Post-Training: https://t.co/2u2saB3C0h
3. Optimally Scaling Sampling Compute for LLM RL: https://t.co/rUSdUvJyNH
4. Scaling up RL: https://t.co/O8vV6z8ymx
5. ProRL V2 - Prolonged Training Validates RL Scaling Laws: https://t.co/vu72juvRW4
6. Polaris - A Recipe for Scaling RL with Reasoning Models: https://t.co/rMibSAeJbg
RL Frameworks
1. Hybrid Flow (early outline of the verl framework): https://t.co/GnWXx131uD
a. More up-to-date info can be found here: https://t.co/j801HcJmPP
2. AReal - Large-Scale Async RL: https://t.co/qhOvsQK09N
3. PipelineRL - Fast On-Policy RL: https://t.co/iRM7KzySXe
4. AsyncFlow - Async Streaming RL: https://t.co/YwmzFtiU2q
RL for Agents
1. DeepSWE - Open Coding Agent Trained w/ RL: https://t.co/GHQHcmtE6F
2. AutoForge - Environment Synthesis for Agentic RL: https://t.co/mr3WDIL5vq
3. Agent-R1 - Training Agents w/ End-to-End RL: https://t.co/xpfQJGgzEv
4. AgentRL - Scaling RL for Multi-Turn, Multi-Task Agents: https://t.co/7fbVl0RWXG
5. The Landscape of Agentic RL: https://t.co/OMnSV4rgdW
6. Training SWE Agents with RL: https://t.co/YqMqySbyXS
Case Studies & Tech Reports
1. Kimi tech reports:
a. Kimi K2 - Open Agentic Intelligence: https://t.co/aAw17SXrIw
b. Kimi End-to-end Agentic RL: https://t.co/ProBpOPIiI
c. Kimi K1.5 - Scaling RL for LLMs: https://t.co/kRGOxY9Jvp
2. Composer series from Cursor:
a. Composer 2: https://t.co/K0v8rNCE6Z
b. Composer 2.5: https://t.co/D9PYimfOMU
3. Olmo 3 (also has open code / data): https://t.co/khetJFvp6N
4. MiniMax tech reports:
a. MiniMax-M2: https://t.co/HApb0OB80S
b. MiniMax-M1: https://t.co/mZj9UQsrnC
5. Nemotron 3 (NVIDIA): https://t.co/lCpE1GzxSi
Workflows are the biggest upgrade to Claude Code’s capabilities since skills and subagents.
I dove deep into it with @sidbid to figure out best practices, examples and more. I’m particularly excited about the non-technical tasks it enables for Claude Code.
This Stanford University paper just broke my brain.
They just built an AI agent framework that evolves from zero data no human labels, no curated tasks, no demonstrations and it somehow gets better than every existing self-play method.
It’s called Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning
And it’s insane what they pulled off.
Every “self-improving” agent you’ve seen so far has the same fatal flaw:
they can only generate tasks slightly harder than what they already know.
So they plateau. Immediately.
Agent0 breaks that ceiling.
Here’s the twist:
They spawn two agents from the same base LLM and make them compete.
• Curriculum Agent - generates harder and harder tasks
• Executor Agent - tries to solve them using reasoning + tools
Whenever the executor gets better, the curriculum agent is forced to raise the difficulty.
Whenever the tasks get harder, the executor is forced to evolve.
This creates a closed-loop, self-reinforcing curriculum spiral and it all happens from scratch, no data, no humans, nothing.
Just two agents pushing each other into higher intelligence.
And then they add the cheat code:
A full Python tool interpreter inside the loop.
The executor learns to reason through problems with code.
The curriculum agent learns to create tasks that require tool use.
So both agents keep escalating.
The results?
→ +18% gain in math reasoning
→ +24% gain in general reasoning
→ Beats R-Zero, SPIRAL, Absolute Zero, even frameworks using external proprietary APIs
→ All from zero data, just self-evolving cycles
They even show the difficulty curve rising across iterations:
tasks start as basic geometry and end at constraint satisfaction, combinatorics, logic puzzles, and multi-step tool-reliant problems.
This is the closest thing we’ve seen to autonomous cognitive growth in LLMs.
Agent0 isn’t just “better RL.”
It’s a blueprint for agents that bootstrap their own intelligence.
The agent era just got unlocked.
LLM as a judge has become a dominant way to evaluate how good a model is at solving a task, since it works without a test set and handles cases where answers are not unique.
But despite how widely this is used, almost all reported results are highly biased.
Excited to share our preprint on how to properly use LLM as a judge.
🧵
===
So how do people actually use LLM as a judge?
Most people just use the LLM as an evaluator and report the empirical probability that the LLM says the answer looks correct.
When the LLM is perfect, this works fine and gives an unbiased estimator.
If the LLM is not perfect, this breaks.
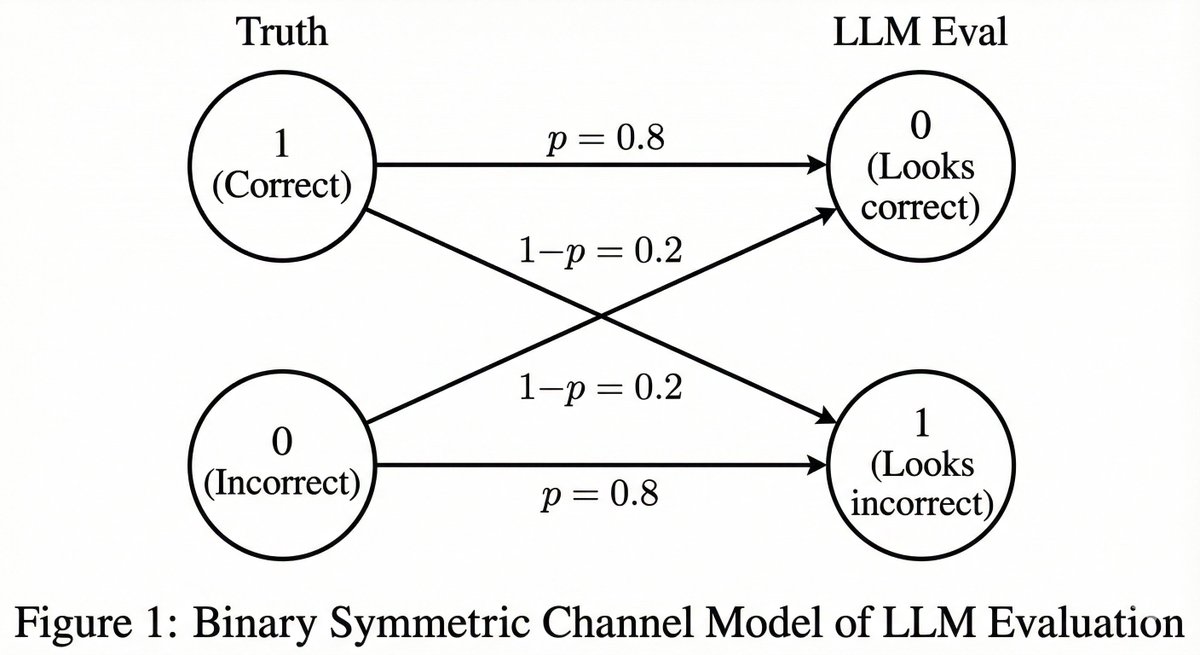
Consider a case where the LLM evaluates correctly 80 percent of the time.
More specifically, if the answer is correct, the LLM says "this looks correct" with 80 percent probability, and the same 80 percent applies when the answer is actually incorrect.
In this situation, you should not report the empirical probability, because it is biased. Why?
Let the true probability of the tested model being correct be p.
Then the empirical probability that the LLM says "correct" (= q) is
q = 0.8p + 0.2(1 - p) = 0.2 + 0.6p
So the unbiased estimate should be
(q - 0.2) / 0.6
Things get even more interesting if the error pattern is asymmetric or if you do not know these error rates a priori.
===
So what does this mean?
First, follow the suggested guideline in our preprint.
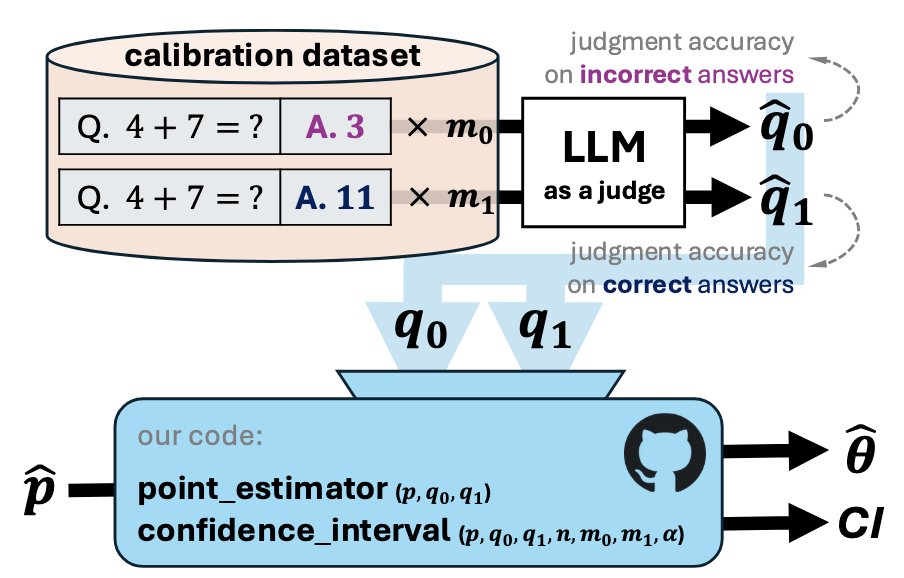
There is no free lunch. You cannot evaluate how good your model is unless your LLM as a judge is known to be perfect at judging it.
Depending on how close it is to a perfect evaluator, you need a sufficient size of test set (= calibration set) to estimate the evaluator’s error rates, and then you must correct for them.
Second, very unfortunately, many findings we have seen in papers over the past few years need to be revisited.
Unless two papers used the exact same LLM as a judge, comparing results across them could have produced false claims. The improvement could simply come from changing the evaluation pipeline slightly. A rigorous meta study is urgently needed.
===
tldr:
(1) Almost all LLM-as-a-judge evaluations in the past few years were reported with a biased estimator.
(2) It is easy to fix, so wait for our full preprint.
(3) Many LLM-as-a-judge results should be taken with grains of salt.
Full preprint coming in a few days, so stay tuned!
Amazing work by my students and collaborators.
@chungpa_lee@tomzeng200@jongwonjeong123 and @jysohn1108
My new field guide to alternatives to standard LLMs:
Gated DeltaNet hybrids (Qwen3-Next, Kimi Linear), text diffusion, code world models, and small reasoning transformers.
https://t.co/ZpWugAccgQ
I just published The Foundations of Generative Recommendation with Semantic ID — (Algorithm). This is a step-by-step tutorial and is easy to follow. Hope it helps. https://t.co/ZbITxgXNGJ
Yes, I recently read 90% of AI projects use PyTorch now. Recently put together an PyTorch essentials article: https://t.co/NWeQan8HJ3
(I’ve been an early adopter since 2018 and never looked back; that being said, regarding your points below, TensorFlow also has dynamic graphs, and Keras supports PyTorch as a backend now too)
Holy shit… Meta might’ve just solved self-improving AI 🤯
Their new paper SPICE (Self-Play in Corpus Environments) basically turns a language model into its own teacher no humans, no labels, no datasets just the internet as its training ground.
Here’s the twist: one copy of the model becomes a Challenger that digs through real documents to create hard, fact-grounded reasoning problems. Another copy becomes the Reasoner, trying to solve them without access to the source.
They compete, learn, and evolve together an automatic curriculum with real-world grounding so it never collapses into hallucinations.
The results are nuts:
+9.1% on reasoning benchmarks with Qwen3-4B
+11.9% with OctoThinker-8B
and it beats every prior self-play method like R-Zero and Absolute Zero.
This flips the script on AI self-improvement.
Instead of looping on synthetic junk, SPICE grows by mining real knowledge a closed-loop system with open-world intelligence.
If this scales, we might be staring at the blueprint for autonomous, self-evolving reasoning models.
Very nice blog post from Thinky (@_kevinlu et al) about on-policy distillation for LLMs -- we published this idea back in 2023 and it is *publicly* known to be successfully applied to Gemma 2 & 3, and Qwen3-Thinking (and probably many closed frontier models)!
The idea behind on-policy distillation is simple: Generate tokens from student, label each token position with teacher logprobs for entire vocab, and train student to match teacher logprobs.
When I describe it to people, the main analogy I give is about a student learning how to drive with a teacher (very inspired from DAGGER iykyk).
- Supervised distillation (e.g., SFT on reasoning traces) is akin to observing the teacher drive the car and trying to mimic their actions.
- On-policy distillation is analogous to the student taking the driver's seat and teacher telling them what they'd do for all situations.
I think most would agree that the on-policy approach is the better way to learn -- if the student is doing something wrong, the teacher would immediately tell the student to do something else. I have also given a tutorial on post-training distillation at DeeMind covering why we care about distillation and the major approaches: https://t.co/5ecxeCfZkz
The OG method is from 2023, so there are simple changes that can be done to make this much better (especially in terms of compute or memory efficiency)! We have also done a bunch of follow-up work where we combine speculative decoding with on-policy distillation to both improve spec decoding and distillation itself: https://t.co/psyZMX7t7g
The OG paper work happened due to a collaboration with @OlivierBachem and @nino_vieillard, who further pushed this direction for Gemma models! Another person to follow related to LLM distillation is @charlinelelan, who led the work on Gemini Flash.
On-policy distillation provides an elegant way to use the teacher model as a process reward model to provide dense reward while preventing SFT style "OOD shock" during rollout.
With R1, a lot of people have been asking “how come we didn't discover this 2 years ago?”
Well... 2 years ago, I spent 6 months working exactly on this (PG / PPO for math+gsm8k), but my results were nowhere as good.
Here’s my take on what blocked me and what’s changed: 🧵
Just a bit of weekend coding fun: A memory estimator to calculate the savings when using grouped-query attention vs multi-head attention (+ code implementations of course).
🔗 https://t.co/rxYQA017vm
Will add this for multi-head latent, sliding, and sparse attention as well.
Really happy to see people reproducing the result that LoRA rank=1 closely matches full fine-tuning on many RL fine-tuning problems. Here are a couple nice ones:
https://t.co/x7hcgNL3Bd
https://t.co/5JyKuKd9wS
@johnschulman2 I 100% agree. Additionally, I have explored the possibility of adding more sparsity to LoRA while simultaneously incorporating curriculum learning to enable gradual adaptation. Read: Solo-connection https://t.co/bB1fAK7wOn
@rasbt For production LLM applications, I typically create golden datasets using either historical data or LLMs, and then focus on two principles: localization and categorization of errors. For more details and examples, read here: https://t.co/pYYJEMfizY
Academics and data scientists are just starting to apply AI to traditionally difficult problems like labeling, analyzing, and categorizing qualitative data
It is worth paying attention to the closely related idea in the computer science “LLM-as-a-judge” - lots of good tips there