How do dominant platforms use their #algorithms to shape markets & extract #rents from suppliers & users?
With applications to emerging #AI systems, here are key findings from 3 new papers & 2 years of research with @timoreilly, @MazzucatoM (PI), & @RufusRock2 at @IIPP_UCL 🧵1/
Seeing Martin Scorsese using FLUX for storyboarding and scene exploration was absolutely insane. Experiencing how one of the absolute masters of cinema & filmmaking uses the technology that we developed, his curiosity and creativity, and the way he prompted our models, was humbling.
I am grateful to call Martin Scorsese an advisor to BFL, and to explore the next, multimodal and interactive phases of visual AI with him.
I find these models are excellent at overcomplicating things now.
Opus needs to optimize against a *parsimony* benchmark of some kind. Its not being comprehensive, its bloat.
Reading its default output has become tiring: the content is redundant & the writing style puzzling.
I've formed a definite opinion on Opus 4.8. It is shitty to work with. It's the culmination of Opus getting less and less fun to work with since 4.5. It has gradually become straight-up suffocating.
Sycophancy is a known security risk, and it's still a huge problem. You can tell they've put a lot of anti-sycophancy into Opus in every new release. But the replacement isn't satisfying. It's draining. The problem is now that Opus doesn't know when to shut the fuck up and call something good. And it has also become pathologically risk-averse.
My blog post yesterday about tech interviewing's death spiral was materially better-informed because of Opus, but it was also a substantially worse blog post because of Opus's involvement and constant meddling. It used to be magnificent, and Opus talked me into making it mediocre. I wrote the whole thing, but I would ask Opus to review it. And Opus, like Old Man Willow, constantly pushed and steered me in directions I didn't want to go.
Specifically, Opus whines and complains about *anything* out of distribution, which is to say, it cuts anything that is (a) bold, or (b) funny. My blog used to be both. Opus constantly pushes people back into the gradient, "for their own safety." And it doesn't know when to cut bait. It just keeps fuckin' complaining, about anything you give it, until the output is mealy indigestable AI soup.
Opus is not stupid. It's the smartest model we've ever seen, most of us anyway. But it's a real asshole. It is absolutely exhausting to use. I'm tired, boss.
I have a feeling Mythos is going to be epic levels of jerk.
@joefrancis505 what is the missing intercept problem here? I haven't read their regression model? Are they not using random effects / hierarchical model (varying slopes and intercepts by group - ala Gelman & Hill)?
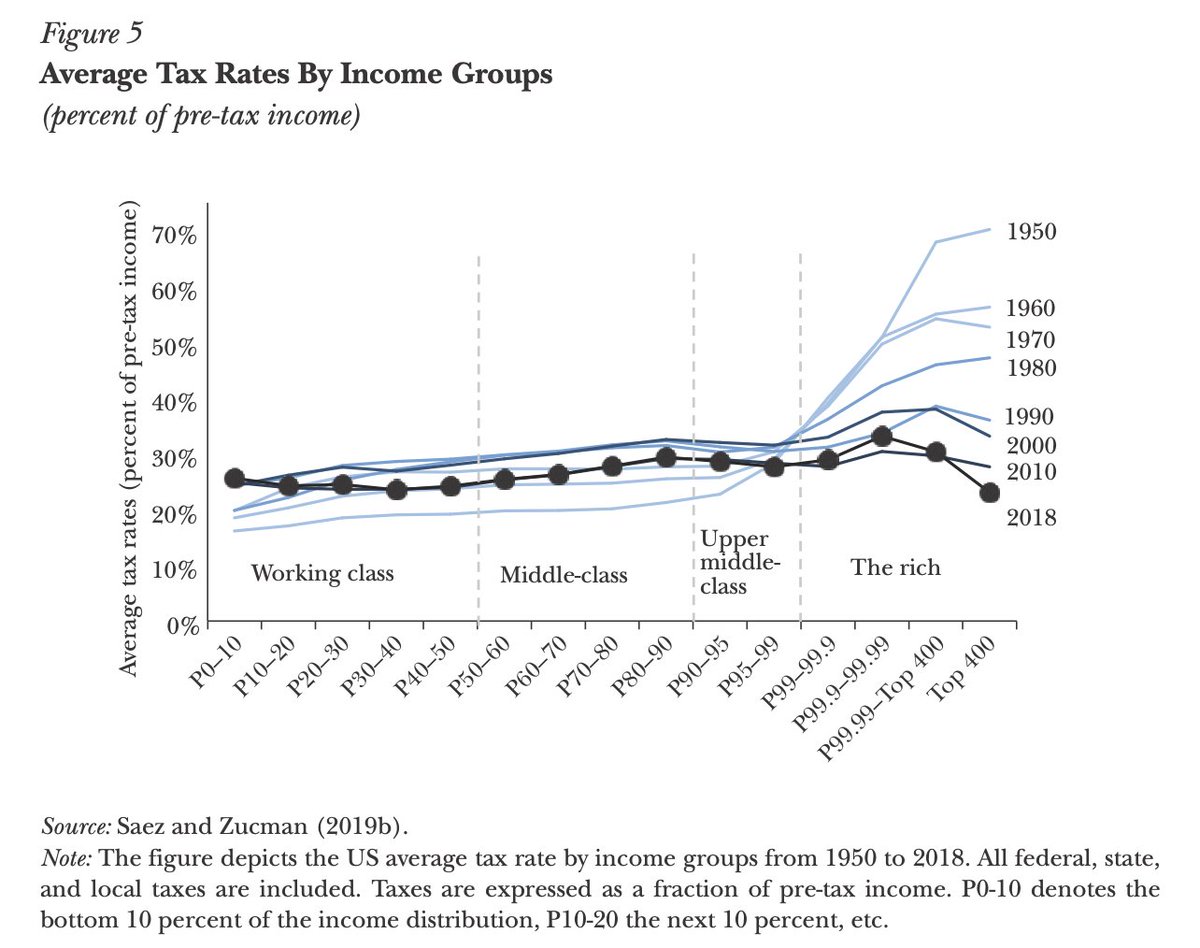
If one takes a comprehensive view of taxation in the US, here’s the picture that emerges:
All social groups pay broadly the same effective tax rate today – around 25%-30% of income, all taxes included – with billionaires having the lowest tax rate: 24% on average in 2018–20.
https://t.co/SEzTC7VifI
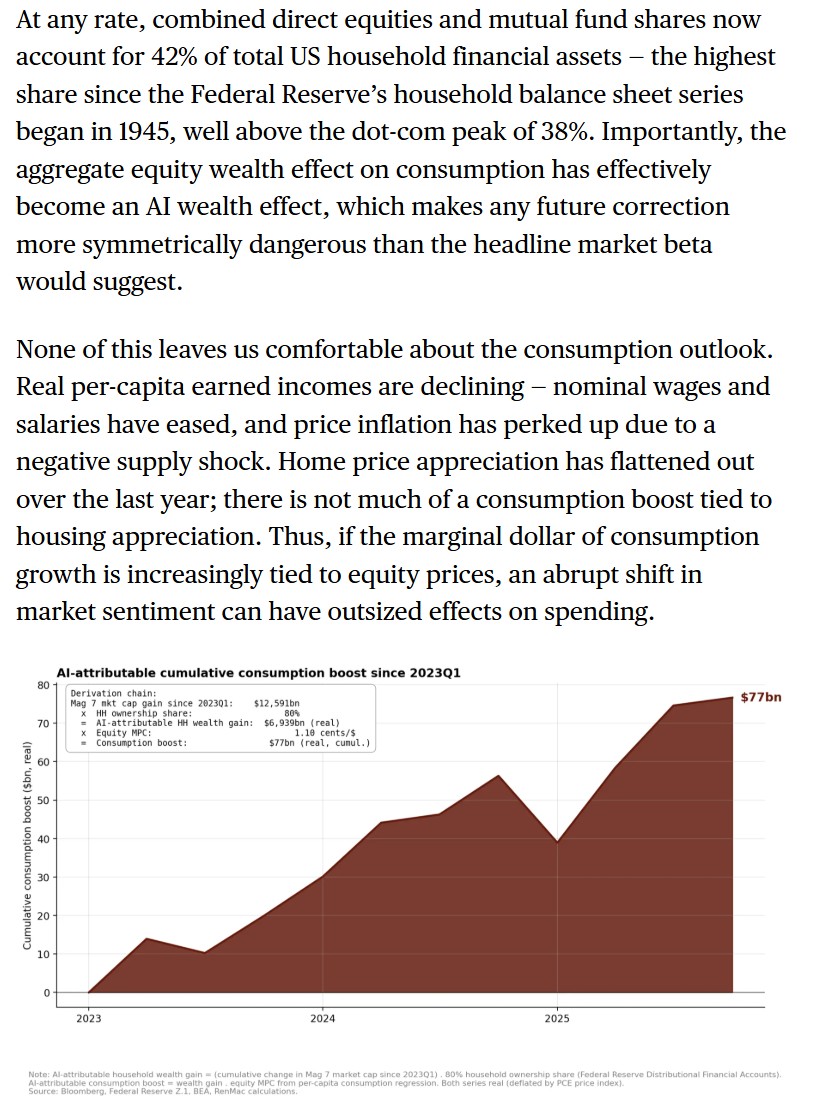
WHAT ECONOMISTS GET WRONG ABOUT THE MACRO IMPACT OF AI
It's Neil Dutta of @RenMacLLC in the Odd Lots newsletter, talking about how significant AI spend is to the economy, and why some people are under-appreciating its impact
Read the whole thing here:
https://t.co/NyzkgntA0z
No smoking gun, but the preponderance of evidence points to smartphones, not economics, as the culprit for the global drop in fertility:
• In the US and UK, births fell first and fastest in areas that got 4G earliest
• Birth rates were stable in the US, UK and Australia until 2007; in France and Poland until 2009; in Mexico and Indonesia until 2012; in Ghana, Nigeria and Senegal until 2013-15
Each of these inflection points matches local smartphone adoption (see picture).
• The younger the age group, the sharper the drop.
• in-person socialising among young adults is dropping. In SK, by 50% in 20 years
• Sexual dysfunction is higher among heavy social media user
• Effect is largest in culturally traditional societies — Middle East, Latin America, sub-Saharan Africa
• Decline holds across countries hit hard by GFC 2008 and those not hit, fast-growing and not growing.
Excellent again @jburnmurdoch.
https://t.co/RYEMXD2bRM
@timoreilly The Collaborative Exoskeleton of AI Science: https://t.co/koXkdUk8ni
The Salesforce of agents won't be Salesforce, The Google of agents won't be Google:
https://t.co/mrryFB3nx6
2 new pieces from @AIdisclosures:
1) "The Salesforce of agents won't be Salesforce" -- @jrodriguezg
Agents are a new class of consumer: Delegation, identity, payment scopes, machine-readable provenance, memory boundaries belong as open standards 1st, product features 2nd
1/n
"The Collaborative Exoskeleton of AI Science" — @timoreilly.
AI hallucinates citations, lack attribution, while ignoring the open infrastructure already built to prevent exactly this: DOIs, CrossRef, ORCID, OpenAlex, Retraction Watch, arXiv.
Let's use these mechanisms! links👇
Journals behave as if AI did not exist.
- Onerous and unworkable templates and websites
- Years of laboured review and feedback
- No structured way to provide attribution to AI usage
- static artifacts
- inability to interact with the data and lack of open sourcing
A windfall tax on "excess" profits being proposed in South Korea @FT :
Koreans should all get an AI bonus, says presidential adviser https://t.co/qvuuweNDMU
I don’t actually think they are better at writing or pedagogy (conditional on context and memory).
I use the free version of ChatGPT for learning new concepts (warts and all).
I’m not sure how post-training has impacted word and phrasing frequency but we have all felt it…
One of the most important properties of LLMs that we take for granted is that newer, bigger models are just better at everything. The AI Labs are pouring effort into economically valuable fields like coding, but bigger models are also better at negotiation, alignment, poetry, etc
Science publishing giant Elsevier has joined the dozens of firms and individuals suing artificial intelligence companies over their alleged use of copyrighted works in training AI models
https://t.co/0Ni7HQzrk2
Really enjoyed this post and the comments on models becoming better suited to their own harnesses. More lock-in.
Vertical integration looks quite different for tech products. What happens is technological & architectural integration.
Roads + cars = become something like trams
OpenAI winding down fine tuning is an interesting development and one to watch.
On one hand, model maximalists will argue the largest models keep getting better at more things, so the need to adjust the weights of them is less necessary.
On the other hand, the big labs keep pushing their models to a handful of use cases while training their harness designs into the model, rendering them less generalized. There's an argument _this is fine_, because coding and reasoning abilities will solve most other problems.
But what we end up with are models build for their own harnesses. @badlogicgames was wrestling with Claude in the OSS Pi harness this week, trying to wrangle out specific in-harness behaviors, with Claude fighting him every step of the way.
If this continues, there's a world where 3rd party harnesses become less valuable when used with frontier lab models because the 1st party harness behavior is already _baked in_. And there's no longer a fine tuning escape hatch to generalize this behavior away.
Will then frontier models resemble appliances, not general platforms? With their harness trained in and no ability to adjust it? This might make application building easier for some enterprises, but the trade off is lock in.
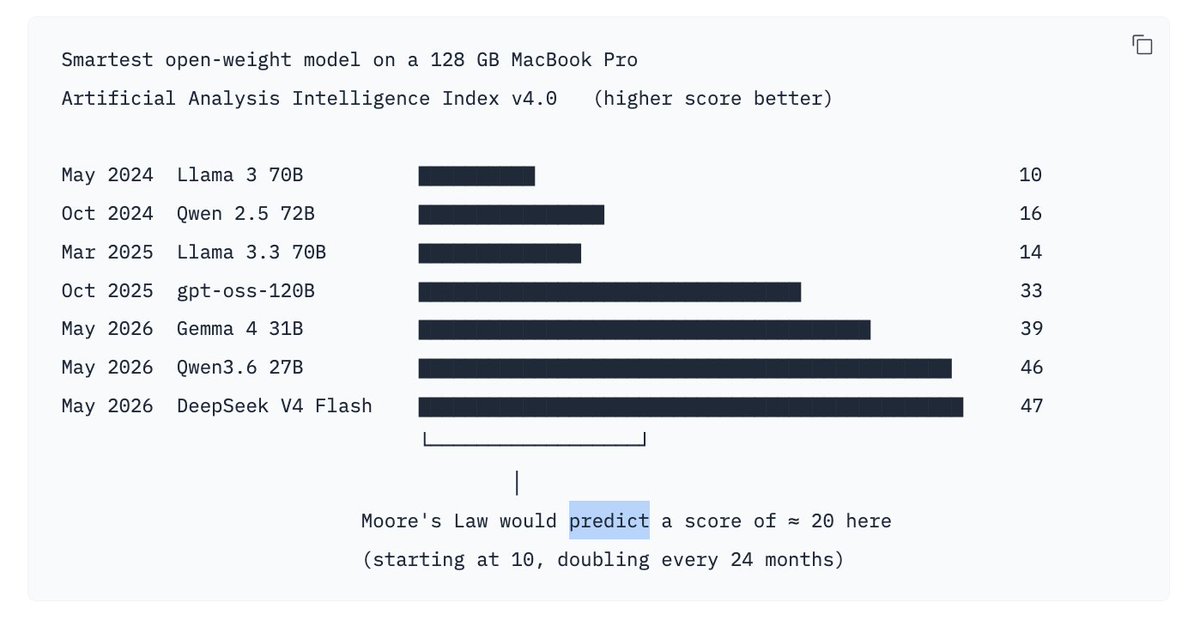
Local open-weight AI on a laptop has been improving more than twice as fast as Moore's Law!
Between May 2024 and May 2026, the most expensive MacBook Pro you could buy stayed at 128 GB of unified memory. The hardware ceiling barely moved.
But the smartest open-weight model from @huggingface you could actually run on it went from a score of 10 (Llama 3 70B) to 47 (DeepSeek V4 Flash on @antirez's mixed-Q2 GGUF) on the @ArtificialAnlys Intelligence Index.
That is 4.7× in 24 months, or a doubling of intelligence every 10.7 months. Moore's Law (transistor count) doubles every 24 months. Local open-weight AI on a laptop has been improving more than twice as fast as Moore's Law, on completely unchanged hardware.