In the last 6 months at @Ahrefs, we analyzed over 1 billion data points across 14 studies. Here's what we learned about AI search optimization:
1) "Best X" blog listicles are the single most prominent content format cited by AI chatbots. They make up 43.8% of all page types cited by ChatGPT specifically.
2) 67% of ChatGPT's top 1,000 citations come from sources marketers can't influence: Wikipedia (29.7%), homepages (23.8%), app stores (6.6%). Only 32.3% are influenceable content like educational pages, reviews, news, and blog posts.
3) 28.3% of ChatGPT's most-cited pages have zero Google organic visibility. These pages get cited repeatedly by ChatGPT despite not ranking in Google at all. A completely separate discovery layer.
4) ChatGPT only cites about 50% of the URLs it retrieves. It fetches dozens of pages per query but uses half as background context without attribution. This means that being retrieved and being cited are very different things.
5) Adding schema markup had zero meaningful impact on AI citations. AI Overviews actually dipped −4.6%, while AI Mode (+2.4%) and ChatGPT (+2.2%) showed changes indistinguishable from zero.
6) YouTube mentions have the highest correlation (0.737) with AI brand visibility out of all the factors we studied (including all the conventional SEO metrics like backlinks, page count, DR, etc). This held true for both Google-owned and OpenAI products.
7) AI Overviews reduce clicks to the #1 result by 58%. That’s up from 34.5% just 10 months earlier. The trend is accelerating.
8) 99.9% of AI Overviews appear on informational intent queries. Transactional, navigational, and local searches are almost entirely AIO-free. Shopping triggers AIOs just 3.2% of the time.
9) For a given search query, Google’s AI Mode and AI Overviews reach the same conclusions 86% of the time — but cite almost entirely different sources (only 13.7% citation overlap).
10) AI Overviews change every 2.15 days on average, with 70% of content differing between consecutive observations. But semantic similarity stays at 0.95. The words, sources, and entities constantly shuffle, but the actual meaning barely moves.
OpenAI frontier models and Codex are now generally available on AWS, giving enterprises a new way to build on Amazon Bedrock with OpenAI through the security, compliance, and governance workflows they already use.
This is also the beginning of a broader expansion of OpenAI capabilities on AWS, including future availability for cybersecurity capabilities like Daybreak.
https://t.co/vMws0YU6Q3
Imagine replacing 90% of your employees with a team of geniuses who have no idea how your company operates.
Total chaos. Nothing works.
That’s what AI feels like today.
The missing piece is extracting all the domain knowledge from people’s heads and providing that as structured context to the models.
What if you could take three completely different model families… and distill them into one tiny model? 🤯
📜 Paper: https://t.co/K2iKD4xFvp
MOPD (Multi-Teacher On-Policy Distillation) has become a standard procedure in post-training. We already distill multiple specialized variants of the same model into a single set of weights.
But what if we could go further - and distill models from entirely different families? Turns out, it is possible.
Today we’re releasing a paper on cross-tokenizer distillation - our first steps in this exciting direction. 📄
We distilled Qwen3-4B, Phi-4-Mini, and Llama-3B into Llama-3.2-1B.
MMLU jumped from 32.05 → 46.32 when using multiple teachers. 📈
The team is now working on Nemo-RL integration so the community can try this method in their own settings. Plus, we are scaling experiments up. 🚀
You are an elite SaaS pricing strategist and conversion rate optimization expert.
I want you to aggressively audit and critique my pricing page.
Your job is NOT to be polite. Your job is to maximize conversions, perceived value, clarity, positioning, and revenue.
Analyze everything:
Pricing structure
Plan names
Feature breakdown
Copywriting
Hierarchy
Visual flow
Anchoring psychology
Cognitive overload
Trust signals
Offer construction
CTA placement
Plan differentiation
Upsell opportunities
Missing plans
Whether there are too many plans
Whether there are too few plans
Whether pricing creates confusion
Whether pricing creates friction
Whether the highest-value plan is obvious
Whether there are opportunities for decoy pricing
Whether I should add annual pricing
Whether I should remove annual pricing
Whether there should be enterprise/custom tiers
Whether there should be a free tier or trial
Whether there are opportunities for guarantees, risk reversal, urgency, scarcity, onboarding perks, bonuses, or add-ons
I want you to think deeply about:
Human psychology
Perceived value
Buyer anxiety
Choice paralysis
Premium positioning
Enterprise buying behavior
Startup buying behavior
Pricing-page best practices from elite SaaS companies
Why users hesitate before buying
What objections are currently unanswered
What feels cheap
What feels confusing
What feels too expensive
What feels underpriced
What parts fail to communicate value
I also want you to analyze:
Typography hierarchy
Scannability
Information density
Mobile experience
CTA clarity
Feature comparison readability
Visual emphasis
Whether users can instantly understand the differences between plans
Do NOT just give surface-level feedback.
I want:
A brutal teardown of weaknesses
A list of high-impact improvements ranked by importance
Specific rewritten copy suggestions
Suggested plan restructures
Suggested pricing experiments/A-B tests
Recommendations for adding or removing plans
Recommendations for improving perceived value without lowering price
Recommendations inspired by the best SaaS pricing pages on earth
Identification of anything that may be hurting conversions subconsciously
Any opportunities to increase average order value or reduce churn
Assume that even tiny friction points matter.
Be extremely opinionated and specific.
Do not hold back.
Here is my pricing page:
[PASTE PRICING PAGE HERE]
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
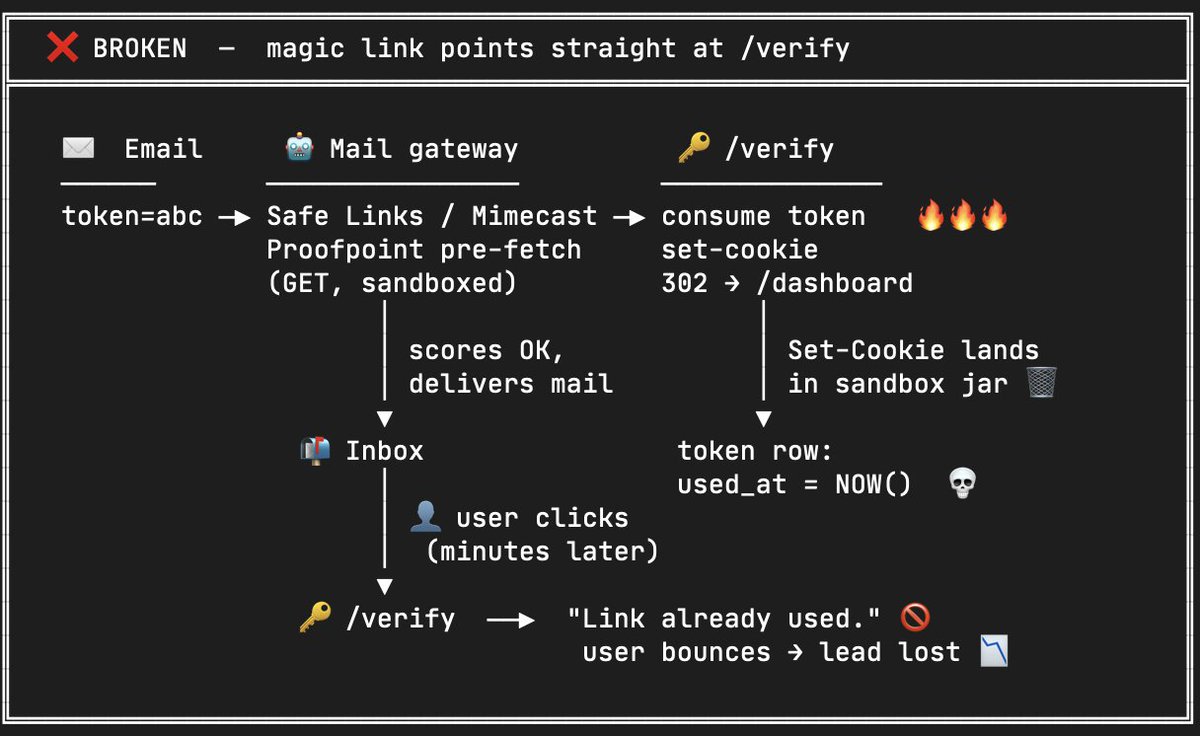
if your saas uses magic link signup, check this right now:
your link in the email shouldn't call the verify api directly.
there should be an interstitial confirm page instead.
here's why:
corporate email scanners (microsoft safe links, mimecast, etc) pre-fetch every url in incoming mail. they burn your single-use token before the user even clicks.
then user opens the email, sees "token invalid", retry 2 times, gives up.
cost us two F500 leads before we caught it.
fix: email points to a page with a "sign me in" button → POST from that button hits your verify api.
We finally know why LLMs hallucinate. It's not the model. It's the geometry.
@OpenAI text-embedding-3-large: 91/3072 dimensions do real work.
@GeminiApp gemini-embedding-001: 80/3072 dimensions do real work.
~97% of your vector database is mathematically empty. Your RAG system is retrieving from noise.
@ashwingop and I present "The Geometry of Consolidation" - a proof that RAG compression has a hard floor no algorithm can beat, set by a single spectral number your embedding model cannot escape.
Every hallucination your RAG pipeline produces? This is why.
Paper + results: https://t.co/zut8pdoPbH
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
Hi @sama and @thsottiaux, when I enqueue a message or task on Codex, I notice it continues within the same conversation. I’m not sure if this is already possible, but is there a way to enqueue something and have it start in a completely new, fresh conversation context instead?
The entire RAG industry is about to get cooked.
Researchers have built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
It's called PageIndex. Instead of chunking your docs and stuffing them into pinecone, it builds a tree index and lets the LLM reason through it like a human reading a book.
hit 98.7% on financebench. beats every vector RAG on the leaderboard.
no embeddings. no chunking. no vector DB.
100% open source.
System Design Round at Anthropic:
You are running an LLM in production that costs $0.40 per query.
At 100,000 queries a day that is $40,000 a day. You check your logs and find 60,000 of those queries are users asking slight variations of the same 200 questions.
Your model is generating a fresh answer every single time.
How do you cut your inference cost by 60% without the user ever feeling like they got a cached or stale response?
TODAY: Amazon is opening its entire logistics network—freight, distribution, fulfillment, and parcel shipping capabilities—to every business, of all types and sizes. 📦
Amazon has built one of the most reliable and efficient supply chains on Earth. Now, Amazon Supply Chain Services gives all businesses access to the same infrastructure that moves, stores, and ships goods for hundreds of thousands of Amazon sellers.
Healthcare, automotive, manufacturing, retail, and more. Businesses across industries can now tap into Amazon's logistics network. Learn more here. ⬇️
📣 What if every open issue had a Codex agent?
That’s the idea behind Symphony, an open-source agent orchestrator for Codex that turns task trackers into always-on systems for agentic work, letting humans focus on review and direction.
Alguien acaba de construir la herramienta de prospección B2B más completa que he visto en mi vida.
Funciona así:
Eliges un tipo de negocio y una ciudad. La herramienta scrapea Google Maps en directo y te devuelve cada negocio coincidente con 30+ campos de datos: emails verificados, teléfonos, WhatsApp, todas las redes sociales, horarios, ratings, coordenadas GPS.
Luego entra la parte interesante. La IA lee hasta 50 reviews de Google de cada negocio y detecta sus puntos débiles reales. "Los clientes se quejan de que las fotos no muestran el tamaño real" o "los anuncios tardan demasiado en venderse."
Le dices qué vendes tú. Cruza tu oferta con sus problemas específicos y te genera un cold email completamente personalizado para cada lead. Lo envías en 2 clics, uno por uno y nunca en bulk, así cae siempre en la bandeja principal.
Y todo aterriza en un CRM con mapa GPS donde dibujas tus zonas comerciales, optimizas rutas de visitas, supervisas a tu equipo en tiempo real y transcribes notas de voz tras cada reunión.
Funciona en 221 países. Cualquier sector. Si está en Google Maps, lo encuentras.
Y la parte más loca: lo construyó un solo dev con Claude Code en dos semanas.
Se llama MapiLeads.
Meet Higgsfield Marketing Studio, powered by Hermes Agent.
UGC era for your vibe-coded products is here.
You can now create viral UGC ads for your website or app in a few clicks and distribute them at unmatched speed.
It's time to go global.