@LeRobotHF@allen_ai@UW@cole__ai@amazon When it comes to "zero shot" rewards, it would be much more interesting if the task wasn't the most saturated one imaginable. Could you try it on something harder and less seen in literature like bimanual lego 2x4 stacking?
@VilleKuosmanen "casually training a world model to predict subtask images" is similar to my planning transformer paper's main idea of training autoregressive behaviour policies to predict the long term future first before predicting the next actions. https://t.co/BdoS0C7GRL
@PgChiyo If you've kept the same motors yours arms now have a rated payload of 0g, and a peak payload of 250g. You need to at least replace the first few motors with STS3250.
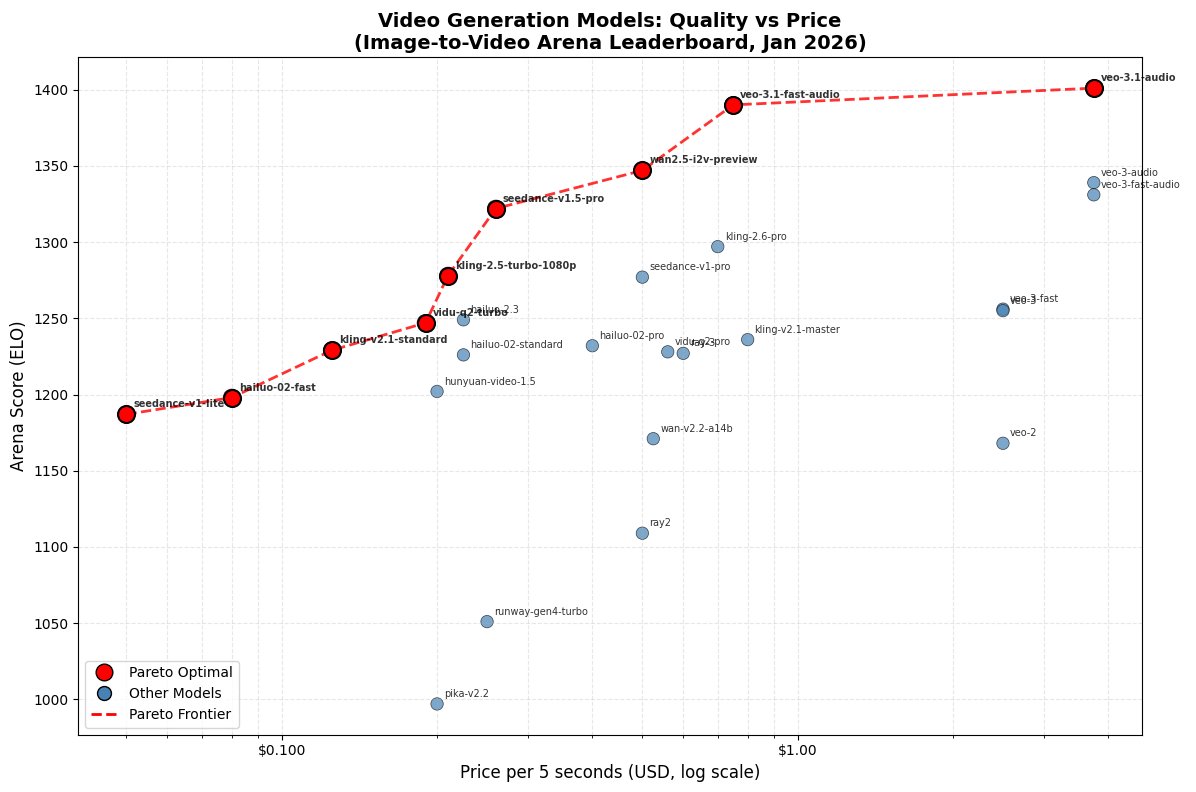
Recently have been working with image-to-video generation models a lot more, so I put together this graph to help determine the best video model for any price point. Seedance-v1.5-pro stands out the most to me as the optimal choice to balance quality and cost.
@thealexbanks This doesn't account for developers moving to untrackable local agents like claude code, codex, cursor and copilot in the same timeframe. Claude Code is far ahead of Codex which is in turn ahead of Gemini.
@Ciszek@chris_j_paxton The vae has a 16x16x4 compression. The model begins with a 480x640 input, so 4 frames is compressed to 600 tokens. The input is 5 context frames + 4 noisy latent frames. The DIT generates this in a single step then passes to the action head. This is not a problem.
@chris_j_paxton VLA's with a video model backbone are my PhD topic. Wholeheartedly believe they are the way forwards and will share some exciting progress on this front later in the year.
@joshuabelofsky Doesn't look accurate enough to be useful unfortunately. I think the data collected would be low quality and it would impact the resulting policy.
@mo_danesh@k7agar You can't guess anything from a such a tiny amount of information. Why even bother trying to help. There's hundreds of possible reasons a VLA model might underperform.
@chrisgpt 45s Christmas ad for mcdonalds with no speaking roles, 18 locations, 45 actors, 90 extras, 3 cgi shots would require a budget of >$1 million. It's likely they spent about 10x less on this ad and even negative attention is still attention.
@lukas_m_ziegler I think this could have been done way cheaper by just waiting for the heated bed to cool down and then repeatedly ramming the part with the flat side of the extruder head until it unsticks and then pushing it off the ledge onto a cushion below.
@liyitengx@RemiCadene Hi, first off this is amazing! Secondly, wanted to ask two questions: 1. why you didn't go for an off the shelf telescopic lift solution? 2. What is the payload of the lekiwi base and do you think it's overloaded?
@vbingliu Could you test models with their preferred agent that they recommend (Claude with Claude Code, GPT-5 with Codex, Gemini with Gemini-Cli, Qwen with Qwen-code)? The right agent pairing should significantly boost performance.