@ColeJacksonFB Look at his pff 2024 though (not 23 my bad) "Simpson had career-high grades across the board, earning a 77.3 overall grade, the 13th highest among guards, and a 79.2 run blocking grade, which also ranked top 10 at the position."
@ColeJacksonFB Oops sorry, meant 2024. According to pff, which is what you posted, "Simpson had career-high grades across the board, earning a 77.3 overall grade, the 13th highest among guards, and a 79.2 run blocking grade, which also ranked top 10 at the position."
ICLR 2025 just gave an Outstanding Paper Award to a method that fixes model editing with one line of code 🤯
here's the problem it solves:
llms store facts in their parameters. sometimes those facts are wrong or outdated. "model editing" lets you surgically update specific facts without retraining the whole model.
the standard approach: find which parameters encode the fact (using causal tracing), then nudge those parameters to store the new fact.
works great for one edit. but do it a hundred times in sequence and the model starts forgetting everything else. do it a thousand times and it degenerates into repetitive gibberish.
every edit that inserts new knowledge corrupts old knowledge. you're playing whack-a-mole with the model's memory.
AlphaEdit reframes the problem.
instead of asking "how do we update knowledge with less damage?" the authors ask "how do we make edits mathematically invisible to preserved knowledge?"
the trick: before applying any parameter change, project it onto the null space of the preserved knowledge matrix.
in plain english: find the directions in parameter space where you can move freely without affecting anything the model already knows. only move in those directions.
it's like remodeling one room in a house by only touching walls that aren't load-bearing. the rest of the structure doesn't even know anything changed.
the results from Fang et al. across GPT2-XL, GPT-J, and LLaMA3-8B:
> average 36.7% improvement over existing editing methods
> works as a plug-and-play addition to MEMIT, ROME, and others
> models maintain 98.48% of general capabilities after 3,000 sequential edits
> prevents the gibberish collapse that kills other methods at scale
and the implementation is literally one line of code added to existing pipelines.
what i find genuinely elegant: the paper proves mathematically that output remains unchanged when querying preserved knowledge. this isn't "it works better in practice." it's "we can prove it doesn't touch what it shouldn't."
the honest caveats:
largest model tested was LLaMA3-8B. nobody's shown this works at 70B+ scale yet. a follow-up paper (AlphaEdit+) flagged brittleness when new knowledge directly conflicts with preserved knowledge, which is exactly the hardest case in production. and the whole approach assumes causal tracing correctly identifies where facts live, which isn't always clean.
but as a core insight, this is the kind of work that deserves the award. not because it solves everything. because it changes the question.
the era of "edit and pray" for llm knowledge updates might actually be ending.
⏰⏰ New Science of Robot Learning Paper: "Much Ado About Noising."
TL;DR we answer why generative models, like flow and diffusion models, actually work for robotic control tasks🤖🤖 (hint: its not multimodality). This leads to a new minimal iterative policy (MIP) that matches flow models with much faster inference🚄🚄
Check out @ChaoyiPan 's thread and paper to find out more. Amazing work by @ChaoyiPan, together with @GuanyaShi , @nmboffi , @guannanqu. Come find us at NeurIPS to chat more!
I still don't believe that Spatial AI is a big data problem. Massive data won't unlock robotics. Representation is still the hard bit. We need efficient, composable representation of 3D physical scenes to enable mental simulation like humans use to plan creative uses of objects.
My team at Boston Dynamics has open Research Scientist positions! We are hiring full-time and interns. If you are excited about RL & humanoids, we want to get to know you!
Research Scientist: https://t.co/Jgw3RHf2q7
Research Scientist Intern: https://t.co/4VNK8qVi1S
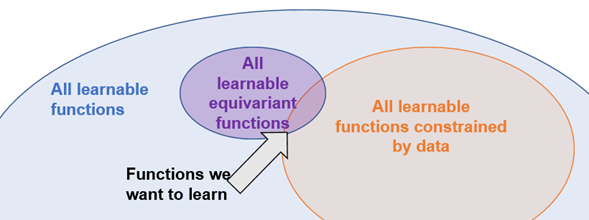
Much of the field obsesses over end-to-end learning. But strong generalization requires compositionality: building modular, reusable abstractions, and reassembling them on the fly when faced with novelty.
The models of the future won't be just pipes, they will be Lego castles.
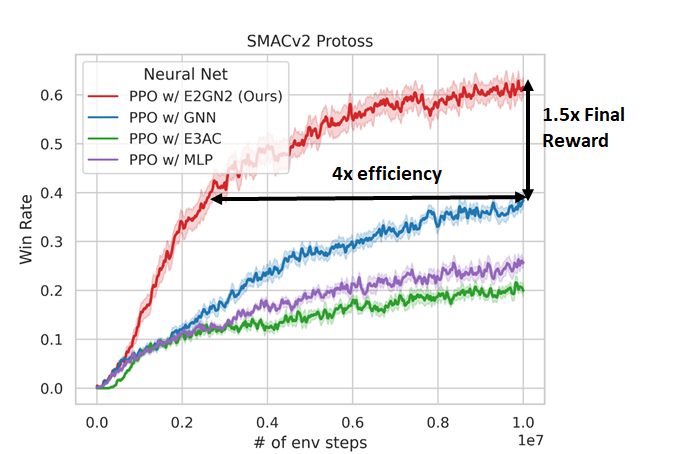
@TacoCohen I would love to chat if you have time. We will also be presenting a relevant poster on using equivariance in Multi agent RL https://t.co/SeCDBtDgZV
I'm excited to share that our paper, "Boosting Sample Efficiency and Generalization in Multi-agent Reinforcement Learning via Equivariance," has been accepted to NeurIPS 2024! 🎉 https://t.co/SeCDBtDgZV
@ptokekar@furongh
This robustness stems directly from its symmetry guarantees, allowing it to lose less performance when adapting to new scenarios.
If you'll be at Neurips come visit our poster next week to learn more and discuss the exciting future of MARL!