Can reasoning models become overly reliant on chain-of-thought examples? 🤔
Our #ACL2026 work shows excessive CoT supervision is not always beneficial, and gives a recipe for tuning the CoT fraction to improve novel-task accuracy. 🧵
Website: https://t.co/hZmPCF6bue
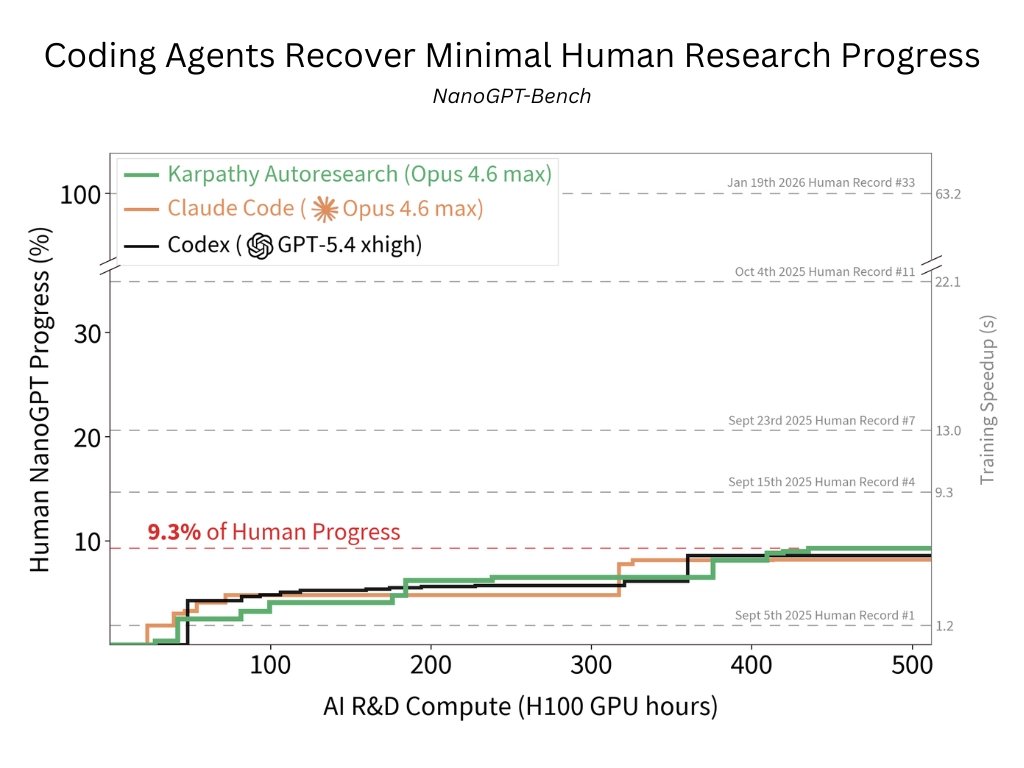
A fascinating reality check for AI coding agents. The new NanoGPT-Bench reveals that current agents (e.g., Claude Code and Codex) only recover 9.3% of human progress on AI R&D tasks.
Can coding agents do research?
We release NanoGPT-Bench, an internal eval we’ve used to test agents on an AI R&D problem with months of human progress
Codex, Claude Code, Autoresearch recover only 9.3% of human progress, mostly tuning hyperparams & ignoring algorithmic research
NanoGPT-Bench is built on the NanoGPT Speedrun, a popular LLM pretraining competition to minimize the training time of a GPT-2 style model. Existing human submissions constitute nearly 2 years of work. To control for dependencies and contamination in frontier models, we standardize evaluation to a 5-month window of world records. Evaluation is fully autonomous and end-to-end, with no human intervention or internet access. 🧵
Proteo-R1 (ICML 2026), the first reasoning protein foundation model for protein design, is out! 🚀🧬
Most protein design models generate structures without ever *reasoning* about which residues matter. We think that's backwards.
Human protein engineers👩🔧 don't work this way. They identify critical interaction residues first — charged anchors, hydrophobic hotspots, specificity-determining motifs — and only then optimize geometry around those decisions.
━━━━━━━━━━━━━━━━
🔬 THE CORE IDEA
━━━━━━━━━━━━━━━━
A dual-expert architecture that explicitly decouples molecular understanding from geometric generation:
→ ⚡A multimodal LLM (understanding expert) analyzes protein sequences, structures, and text to identify key functional residues governing binding and specificity
→ ⚡A diffusion model (generation expert) then co-designs sequence + structure — but with those residues locked in as hard constraints
━━━━━━━━━━━━━━━━
📐 HOW IT'S TRAINED
━━━━━━━━━━━━━━━━
Three-stage curriculum:
① Multimodal Alignment — freeze the LLM, train projections to bridge ESM-2 + AF3-style structural features into language space
② Structural Reasoning Mid-Training — unfreeze the LLM, teach it residue grounding → pairwise geometry → interface localization → hotspot prediction
③ Joint Reasoning-Guided Design — end-to-end on antibody-antigen complexes. Gradients from the diffusion objective flow back through the reasoning expert.
━━━━━━━━━━━━━━━━
📊 RESULTS
━━━━━━━━━━━━━━━━
Evaluated on simultaneous multi-CDR redesign and the RAbD CDR-H3 benchmark:
✅ Best RMSD & DockQ on RAbD — redesigned H3 loops are geometrically accurate *and* docked well
✅ Lowest backbone dihedral divergence (JSDbb) among all baselines
✅ Reduced intra- and inter-chain steric clashes
✅ Generated sequences score lower perplexity than native antibodies under IgLM & AbLang
✅ Plug-and-play: swapping the diffusion backend to UniMoMo still improves RMSD and IMP
━━━━━━━━━━━━━━━━
💡 WHY IT MATTERS
━━━━━━━━━━━━━━━━
Proteo-R1 isn't just a better antibody design model. It's a blueprint for coupling deliberative LLM reasoning with any physical generative process — interpretable, modular, and backend-agnostic.
📄 Paper: https://t.co/efquYg3O76
💻 Code: https://t.co/Qxm06IZ4xy
🌐 Demo: https://t.co/nkfEWY32OA
Great thanks to my wonderful collaborators Weihao Xuan, Heli Qi, @Hanqun_CAO, Heng-Jui Chang, @KKuanPang@XiangruTang Zehong Wang, @hcwww_ , @KejunYing@lupantech Chiho Im, Seungju Han, @richardxp888@tikgiau. Also appreciate the guidance from advisors @YejinChoinka@jure@erranlli Naoto Yokoya, Masashi Sugiyama.
We’re working with world-class experts to encode the latest research techniques and best practices into reusable skills that any scientist can use.
First up: rare-variant gene burden analysis, demonstrated on UK Biobank data for obesity.
Read the case study here:
What if building production-ready predictive models was as simple as asking a question in plain English?
Today, we’re launching Kumo Coding Agent Skills, an open-source library that turns coding agents like Claude Code and OpenAI Codex into experts at building advanced predictive models with the Kumo SDK.
https://t.co/kSpWiPmhZ9
Thrilled that Biomni-AD won the $1M Alzheimer's Insights AI Prize at the AD/PD Conference in Copenhagen 🏆
Most AI tools answer a single question. Biomni-AD is a co-scientist agent. It explores hypotheses, integrates evidence across genetics, proteomics, neuroimaging & clinical data, and explains its reasoning so scientists can interrogate and build on it.
Alzheimer's will affect 152M people by 2050. No single researcher can synthesize all that data at once. That's exactly where AI agents change the equation.
Proud of the whole team. And it'll be freely available to researchers worldwide 🙏
https://t.co/vN6yWnMi2c
Join me tomorrow to see KumoRFM-2 live! 🚀
The first foundation model to outperform supervised ML on enterprise data, scaling to 500B+ rows.
Register here: https://t.co/FvJPGx4Z3y
KumoRFM-2 just became the first foundation model to outperform fully supervised machine learning on enterprise data. Scaling to 500B+ rows.
We're doing a free live session to show you how it works.
In this session, we'll:
- Break down the innovations behind KumoRFM-2
- Demo real workflows end-to-end
- Showcase use cases across sales, marketing, and fraud
Speakers:
- Jure Leskovec - Chief Scientist & Co-founder, Professor at Stanford
- Disha Dubey - Data Science Lead
- Vid Kocijan - ML Engineer
Date: Tuesday, April 21, 2026
Time: 10:00 AM PDT
Where: Online, free to attend
Register here:
https://t.co/GsxNEKCft3
We are excited to announce Biomni Lab has exited research preview and is now generally available!
Over the last month, we received and incorporated valuable feedback from our global community of 10K+ scientists. We were amazed to learn that Biomni Lab power users accomplished ~20 months of work in just one.
We are introducing a Pro tier (alongside the free tier) with higher usage limits, priority HPC access, and more concurrent tasks so our users can get even more done, faster.
Accelerate your science today → https://t.co/9ME5BcaND3
We've been building nonstop since our public launch, and this week we're officially celebrating with the Biomni community! 🚀
On Thursday, join us virtually for a live demo of Biomni Lab by co-founders @KexinHuang5 and @YuanhaoQ, plus recent product updates and how we think about evaluating AI agents in biology.
On Friday, we'll feature demos + lightning talks from scientific co-founders @jure and @lecong, plus free swag, drinks, small bites, and plenty of time to mingle. We only have a few spots left, so RSVP soon.
• Virtual: https://t.co/NNKtsIBymk
• South SF: https://t.co/0JcPPvhGMo
We can't wait to see you there!
Scientific analysis doesn’t stop when computation finishes. Results need to be clearly visualized and communicated to be shared and built upon.
We’ve revamped visual outputs in Biomni Lab:
• Automatic slide deck generation
• Reports exportable to HTML, Word, or PDF with embedded figures
• Substantial improvements to scientific figure quality
Biomni Lab now takes rigorous analyses through to presentation-ready outputs.
Try Biomni Lab: https://t.co/t1XyiyFhZS
The @Kumo_ai_team research team - Matthias Fey (creator of @PyTorch Geometric @PyG_Team, Head of Research), Federico Lopez (PhD Heidelberg), and Vid Kocijan (PhD Oxford) - will present their latest research on foundation models for relational data at @UniofOxford 's LoG² seminar.
Topic: How Relational Foundation Models enable in-context learning across arbitrary database schemas using graph transformers - without retraining.
This is an open event - Oxford ML researchers, PhD students, and anyone interested in the future of graph learning are welcome to attend.
Feb 17, 1:00 PM
Bill Roscoe Lecture Theatre, CS Department, University of Oxford
Thank you @epomqo and @mmbronstein for hosting!
Quite exciting work on synthetic data generation that for the first time demonstrates scaling laws for graph/relational foundation models.
Great work by @kvignesh1420@_rishabhranjan_@VHudovernik and our collaborators at @Kumo_ai_team and @SAP
Relational Foundation Models face a scaling problem: diverse training datasets are rarely public due to privacy constraints 🔒.
🚀 We are excited to introduce "PluRel": a framework that synthesizes diverse multi-table relational databases from scratch, unlocking scaling laws for RFMs. 🧵
Kudos to the amazing collaborators at @StanfordAILab@Kumo_ai_team , and @SAP : @_rishabhranjan_@VHudovernik@vijaypradwi@johanneshoffart@guestrin@jure
Excited to share the launch of @phylo_bio 🚀 — a research lab studying agentic biology, spun out of our open-source AI scientist @ProjectBiomni.
As scientific cofounder, I’m proud of what this team has built: Biomni Lab, the first Integrated Biology Environment where agents handle the mechanics and scientists focus on questions, mechanisms, and discovery.
Onward 🚀
🔬 Try it free: https://t.co/Ca5oJHN35k
📢 We’re hiring: https://t.co/YGGwOU5YUa
Today we’re launching Phylo, a research lab studying agentic biology, backed by a $13.5M seed round co-led by @a16z and @MenloVentures / Anthology Fund @AnthropicAI.
We’re also introducing a research preview of Biomni Lab, the first Integrated Biology Environment (IBE), where we’re imagining a new way biologists work.
Biomni Lab uses agents to orchestrate hundreds of biological databases, software tools, molecular AI models, expert workflows, and even external research services in one workspace, supporting research end-to-end from question to experiment to result.
Agents handle the mechanics, while you define the question, then review, steer, and decide. Scientists end up spending more time on science: asking questions, understanding mechanisms, and eliminating diseases.
Phylo (@phylo_bio) is a spin-out of @ProjectBiomni, where we will maintain the open-source community and push open-science research. I’m grateful to continue building with my co-founders @YuanhaoQ@jure@lecong and the dream founding team @serena2z@TianweiShe @huangzixin20151 @gm2123@margaretwhua@malayhgandhi.
We’re also fortunate to be advised by leading scientists @zhangf, Carolyn Bertozzi, and @fabian_theis, and supported by an amazing group of investors including @JorgeCondeBio@zakdoric Matt Kraning @ZettaVentures@dreidco@conviction@saranormous@svangel@valkyrie_vc and others.
Biomni Lab is available for free today: https://t.co/zYcXEjvIbb
Learn more in our launch post: https://t.co/O09cnwYeNg
We are also hosting launch events - join us at
South San Francisco: https://t.co/4Xm9DFf4cY
Virtual: https://t.co/Wf7ksnWkRy
We’re also hiring! https://t.co/PABaLLwmRx
LLMs won because they were native to text.
Treating tables as flattened tokens was always a hack.
Structured data needs its own foundation models — ones that understand schemas, relationships, and numerical semantics from the ground up.
That’s where the real enterprise value is.
The next big AI wave won’t be prose — it’ll be rows, columns, and relations.
https://t.co/Uqlqtbfcik
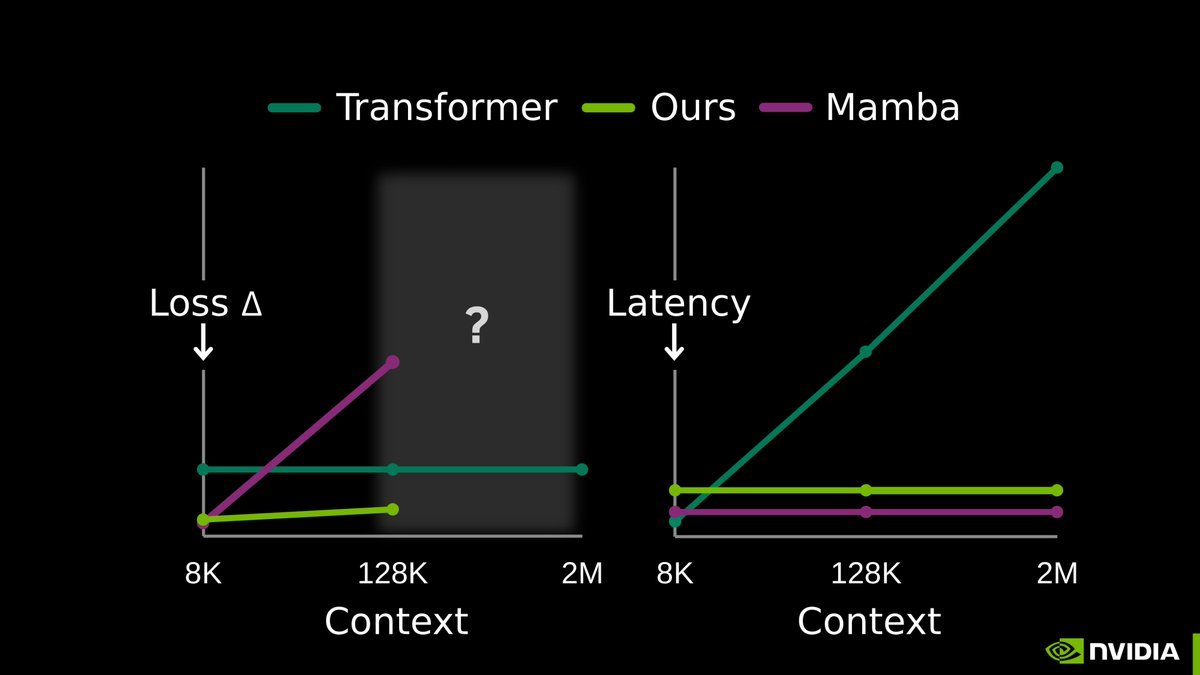
To decode the mysteries of cell behavior, we need models that can efficiently reason over parts of the human genome spanning millions of nucleotides.
New work from my lab, TTT-E2E, is a huge leap forward for processing long sequence data. At test-time, TTT-E2E uses the input sequence as “training data” to compress the most relevant context back into model weights. For long sequences, this means that we no longer need to store a massive attention KV cache!
LLM memory is considered one of the hardest problems in AI.
All we have today are endless hacks and workarounds. But the root solution has always been right in front of us.
Next-token prediction is already an effective compressor. We don’t need a radical new architecture. The missing piece is to continue training the model at test-time, using context as training data.
Our full release of End-to-End Test-Time Training (TTT-E2E) with @NVIDIAAI, @AsteraInstitute, and @StanfordAILab is now available.
Blog: https://t.co/woCpiIrq0T
Arxiv: https://t.co/3VkFlS3wx3
This has been over a year in the making with @arnuvtandon and an incredible team.