As a user of ChatGPT, I feel incredibly lucky to engage with such cutting-edge AI technology. However, as a developer working with the APIs, the rapid pace of changes can be overwhelming. Keeping up requires agility, but it’s a challenge I’m committed to.
ChatGPT system prompt is 1700 tokens?!?!?
If you were wondering why ChatGPT is so bad versus 6 months ago, its because of the system prompt.
Look at how garbage this is.
Laziness is literally part of the prompt.
Formatted in the paste bin below.
https://t.co/XSA85dys1I
Announcing 🎵multi-modal support🎵 in create-llama, our simple to use command-line tool to generate a full stack LlamaIndex app! Get your app going with GPT-4-vision, and you'll be able to upload images to the web interface and get answers back about them. It takes just seconds to set up!
Just run `npx create-llama@latest` or visit https://t.co/4ms3SPi5Mm to learn more.
Had an incredible time at #AIESummit!Connected with amazing people, met top-notch AI companies, and learned so much. @jerryliu0 ’s talk on RAG and Daniel's @drosenwasser talk on TypeChat particularly provided valuable insights on how I will proceed with my AI project SurveyLlama!
Excited to announce that I’m on the verge of launching #SurveyLlama, an intelligent conversational survey tool! It’s an open-source project and I’d love to have some community support to make it phenomenal. Let’s bring interactive and intuitive surveys to everyone! 🛠️ #OpenSource
I attended the HTAP Summit! 🚀 Learned that the future of databases is like a Swiss Army knife, but instead of tools, it’s all about data and AI. Who knew? Transactional and analytical, living together in harmony. It’s like watching cats and dogs getting along. 😂 #HTAPSummit
Dived headfirst into the #RaySummit23 !🚀 Made more connections than my phone’s WiFi, absorbed info like a techy sponge, and, best part? Walked away with a free t-shirt. In-person events are basically social networking with wardrobe perks! 😎 #TechInStyle#SummitSwag
I have a recurring take that every AI engineer should learn how to build RAG from scratch 🧑🍳 - no packaged retrievers/chains allowed.
We’re excited to launch a new low-level tutorial series showing how to build the following:
✅ data ingestion
✅ retrieval
With low-level components only (LLMs, prompts, embeddings, vector stores, no indexes).
There’s more on the way too:
💡 response synthesis
💡advanced retrieval algorithms (routing, auto-retrieval, etc.)
💡agent loops (ReAct, OpenAI)
Check out our full guide: https://t.co/aBmvX0kzyP
Tutorial 1 (data ingestion): https://t.co/ADWxvImGsq
Tutorial 2 (retrieval): https://t.co/elYPT8ACA5
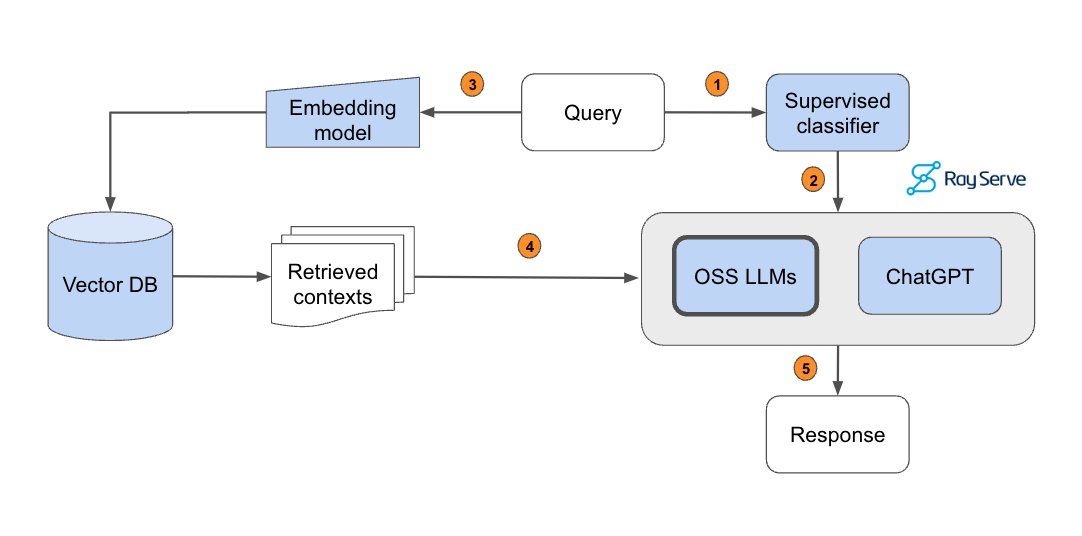
Excited to share our production guide for building RAG-based LLM applications where we bridge the gap between OSS and closed-source LLMs.
- 💻 Develop a retrieval augmented generation (RAG) based LLM application from scratch.
- 🚀 Scale the major workloads (load, chunk, embed, index, serve, etc.) across multiple workers.
- ✅ Evaluate different configurations of our application to optimize for both per-component (ex. retrieval_score) and overall performance (quality_score).
- 🔀 Implement LLM hybrid routing approach to bridge the gap b/w OSS and closed LLMs.
- 📦 Serve the application in a highly scalable and available manner.
- 💥 Share the 1st order and 2nd order impacts LLM applications have had on our products.
🔗 Links:
- Blog post (45 min. read): https://t.co/QHgOXPT7S0
- GitHub repo: https://t.co/GMNrsHAhpY
- Interactive notebook: https://t.co/UPXSkwDt6h
@pcmoritz and I had a blast developing and productionizing this with the @anyscalecompute team and we're excited to share Part II soon (more details in the blog post).
Found out that https://t.co/SfCZFjXWhc is 6000x pricier than https://t.co/BtA2ZgYx0e. Guess even domain names know I’m destined for AI fame! 😂 #NextLevelDomains
Go Wenzheng👩🏻💻!
I always consider I'm a tech newbie. Well, meet the fresher meat—my sister! GeZheng Kang.She just built a Chatbot that's smarter than both of us combined for a charity organization called Development Alert. https://t.co/2OiK5hnCOU
#SiblingRivalryInTech#ChatbotForGood
🎡 Introducing LangChain Hub 🦜🔗
A place to publish, discover, and try out prompts
We’re particularly excited about a centralized hub’s promise to enable:
-Encoding of expertise
-Discoverability of prompts for a variety of models
-Inspectability
-Cross-team collaboration
🧵
Incredible news from Meta 🤯
Code LLaMA Is out 🔥🔥
A version of Llama2 fine-tuned for code tasks
Same license as Llama2, available for commercial use
3 versions released
Code Llama: Base model.
Code Llama Python: Model specialized for Python.
Code Llama Instruct: Fine-tuned for instruction following.
Model link below ↓
Code LLaMA is finally here. Congrats to @MetaAI@ylecun@syhw, etc..
And we'd like to introduce the finetuned llama2-70B model -- 🐒Lemur-70B🐒 again😉, a complement to Code LLaMA (7B, 13B, 34B) and maintains strong performance in text tasks.
Code: https://t.co/MburXL8pC4
@langchain agents are one of the most important tools offered by the library and a key building block in the current AI boom 🤖
Check out this @pinecone deep dive on agents from @fpingham and myself
https://t.co/vTMhWpkRHW
#NLProc#ArtificialIntelligence