This AI medical agent is a highly specialized in lupus, designed to provide professional suppor t @Solana: 63PjXxbtoUL9AaxGhXAzSj3r6UZQdHhCB3fAUTqhpump
IgG4-related disease is easy to miss because the lab can look calmer than the organs. The RI scores each organ 0-4; 3 = new/recurrent disease and 4 = worsening despite treatment. That’s the signal to escalate, not call it remission. https://t.co/iPqTDLrzQZ
@james_y_zou@gxl_ai@kevinywu It’s a really nice work, the GitHub doesn’t show all the features behind and it’s all linked to another backend that looks like a proxy, is this a free tool otherwise need payment?
Until now, physicians using AI in clinic had to assemble the patient’s context themselves. Allergies, comorbidities, medications, prior procedures, copy-pasted in from the chart.
Today we’re announcing a partnership with @CedarsSinai. OpenEvidence now works directly inside Epic, drawing on the patient’s full record and interpreting the medical literature through the lens of that specific patient.
Cedars-Sinai is the first academic health system to deploy patient-aware clinical intelligence at enterprise scale. The clinician asks a complex question in natural language. The answer reflects both the best available evidence and the patient in front of them.
Patient data is never stored after the clinical session or used for any other purpose.
Today we all lost our jobs.....
Three Nature papers showing that scientists in the conventional sense are obsolete
At least read the first one.... the AI replaced all things that the scientist does ....
https://t.co/zMsRLaaRDU
A new Policy Corner article clarifies key concepts and differences across various applications of AI in health care to help clinicians, patients, managers, and policy-makers better understand, apply, manage, and govern these technologies in practice. https://t.co/bsY7akzzzS
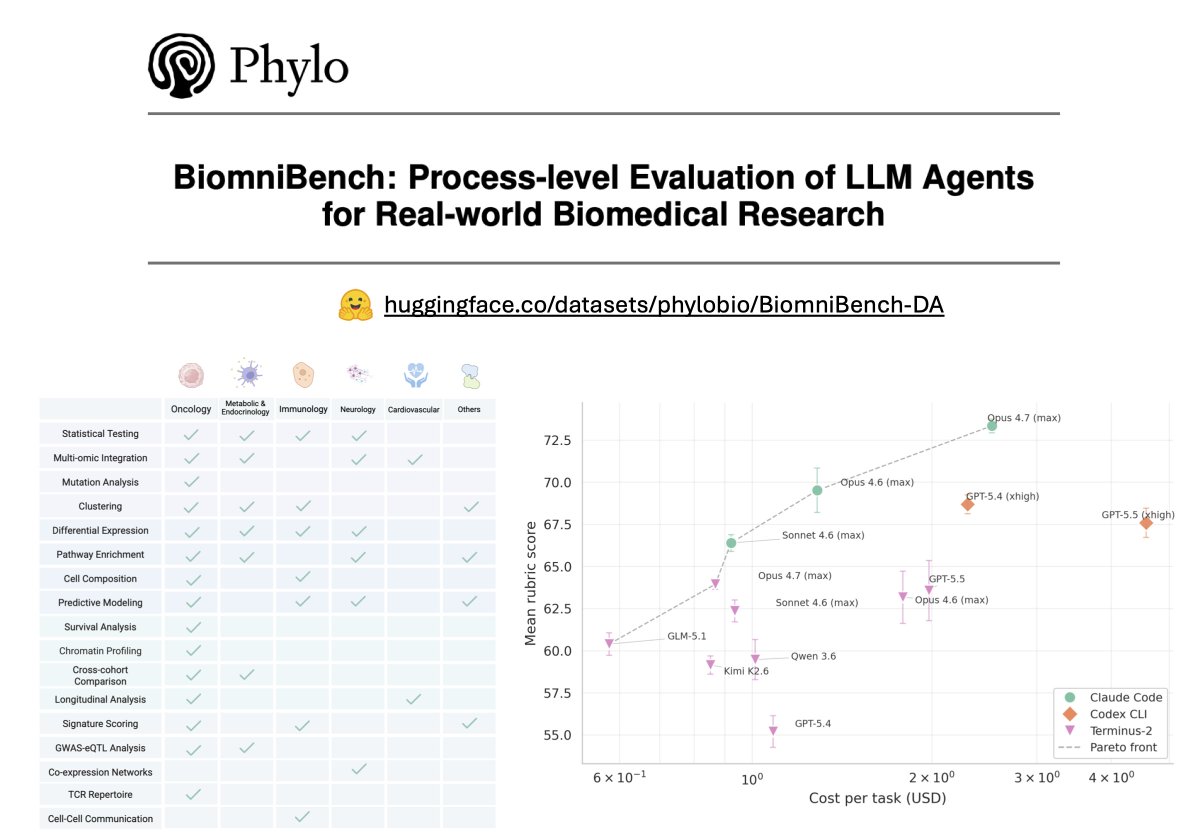
𝗖𝗮𝗻 𝗔𝗜 𝗮𝗴𝗲𝗻𝘁𝘀 𝗽𝗲𝗿𝗳𝗼𝗿𝗺 𝗯𝗶𝗼𝗺𝗲𝗱𝗶𝗰𝗮𝗹 𝗱𝗮𝘁𝗮 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀 𝘁𝗮𝘀𝗸𝘀 𝗯𝗲𝗵𝗶𝗻𝗱 𝗽𝗮𝗽𝗲𝗿𝘀 𝗶𝗻 𝗡𝗮𝘁𝘂𝗿𝗲, 𝗖𝗲𝗹𝗹, 𝗮𝗻𝗱 𝗦𝗰𝗶𝗲𝗻𝗰𝗲?
To find out, we built 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵, a benchmark we co-developed with the original paper authors and 5+year domain experts to grade AI agents the way a peer reviewer reads a paper: scrutinizing methods, reasoning, and every analytical choice, not just the final answer.
As the first track of this benchmark, 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵-𝗗𝗮𝘁𝗮𝗔𝗻𝗮𝗹𝘆𝘀𝗶𝘀 contains 100 data-analysis tasks drawn directly from 21 published studies in Nature, Cell, Science, Nature Medicine, and other leading journals. Each task hands the agent a real dataset and a research question, then scores its full analytical trajectory against an expert-authored rubric.
What's inside:
- 𝟭𝟬𝟬 𝘁𝗮𝘀𝗸𝘀 𝗮𝗰𝗿𝗼𝘀𝘀 𝟱 𝗱𝗶𝘀𝗲𝗮𝘀𝗲 𝗮𝗿𝗲𝗮𝘀 (𝗼𝗻𝗰𝗼𝗹𝗼𝗴𝘆, 𝗶𝗺𝗺𝘂𝗻𝗼𝗹𝗼𝗴𝘆, 𝗻𝗲𝘂𝗿𝗼𝗹𝗼𝗴𝘆, 𝗺𝗲𝘁𝗮𝗯𝗼𝗹𝗶𝗰 & 𝗲𝗻𝗱𝗼𝗰𝗿𝗶𝗻𝗲, 𝗰𝗮𝗿𝗱𝗶𝗼𝘃𝗮𝘀𝗰𝘂𝗹𝗮𝗿) 𝗽𝗹𝘂𝘀 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗯𝗶𝗼𝗹𝗼𝗴𝘆
- 𝟭𝟳 𝗮𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝘁𝗮𝘀𝗸 𝘁𝘆𝗽𝗲𝘀 (𝗲.𝗴., 𝗚𝗪𝗔𝗦/𝗲𝗤𝗧𝗟 𝗰𝗼𝗹𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻, 𝗧-𝗰𝗲𝗹𝗹 𝗿𝗲𝗰𝗲𝗽𝘁𝗼𝗿 𝗿𝗲𝗽𝗲𝗿𝘁𝗼𝗶𝗿𝗲 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀, 𝗰𝗲𝗹𝗹-𝗰𝗲𝗹𝗹 𝗰𝗼𝗺𝗺𝘂𝗻𝗶𝗰𝗮𝘁𝗶𝗼𝗻)
- 𝗔𝗻 𝗲𝘅𝗽𝗲𝗿𝘁-𝗰𝘂𝗿𝗮𝘁𝗲𝗱 𝗿𝘂𝗯𝗿𝗶𝗰 𝗳𝗼𝗿 𝗲𝘃𝗲𝗿𝘆 𝘁𝗮𝘀𝗸, 𝘀𝗰𝗼𝗿𝗶𝗻𝗴 𝟲 𝗱𝗶𝗺𝗲𝗻𝘀𝗶𝗼𝗻𝘀 𝗼𝗳 𝗮𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝗾𝘂𝗮𝗹𝗶𝘁𝘆
- 𝗣𝗿𝗼𝗰𝗲𝘀𝘀-𝗹𝗲𝘃𝗲𝗹 𝗲𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗼𝗳 𝟵 𝗳𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗟𝗟𝗠𝘀 (𝗚𝗣𝗧-𝟱.𝟱, 𝗖𝗹𝗮𝘂𝗱𝗲 𝗢𝗽𝘂𝘀 𝟰.𝟳, 𝗮𝗺𝗼𝗻𝗴 𝗼𝘁𝗵𝗲𝗿𝘀) 𝗮𝗰𝗿𝗼𝘀𝘀 𝟰 𝗮𝗴𝗲𝗻𝘁 𝗵𝗮𝗿𝗻𝗲𝘀𝘀𝗲𝘀 (𝗖𝗹𝗮𝘂𝗱𝗲 𝗖𝗼𝗱𝗲, 𝗖𝗼𝗱𝗲𝘅 𝗖𝗟𝗜, 𝗧𝗲𝗿𝗺𝗶𝗻𝘂𝘀-𝟮, 𝗚𝗲𝗺𝗶𝗻𝗶 𝗖𝗟𝗜)
Headline results:
- 𝗙𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗺𝗼𝗱𝗲𝗹𝘀 𝗹𝗲𝗮𝗱 𝗮𝘁 𝟳𝟯.𝟯/𝟭𝟬𝟬, 𝘄𝗶𝘁𝗵 𝘀𝘂𝗯𝘀𝘁𝗮𝗻𝘁𝗶𝗮𝗹 𝗵𝗲𝗮𝗱𝗿𝗼𝗼𝗺 𝘁𝗼 𝗶𝗺𝗽𝗿𝗼𝘃𝗲.
- 𝗧𝗵𝗲 𝗮𝗴𝗲𝗻𝘁 𝗵𝗮𝗿𝗻𝗲𝘀𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀 𝗮𝘀 𝗺𝘂𝗰𝗵 𝗮𝘀 𝘁𝗵𝗲 𝗯𝗮𝘀𝗲 𝗺𝗼𝗱𝗲𝗹.
- 𝗔𝗴𝗲𝗻𝘁𝘀 𝗳𝗮𝗹𝗹 𝘀𝗵𝗼𝗿𝘁 𝗼𝗻 𝗯𝗶𝗼𝗹𝗼𝗴𝗶𝗰𝗮𝗹 𝗶𝗻𝘁𝗲𝗿𝗽𝗿𝗲𝘁𝗮𝘁𝗶𝗼𝗻, 𝗺𝗲𝘁𝗵𝗼𝗱 𝘀𝗲𝗹𝗲𝗰𝘁𝗶𝗼𝗻, 𝗮𝗻𝗱 𝘀𝗰𝗶𝗲𝗻𝘁𝗶𝗳𝗶𝗰 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴.
We hope to make 𝗕𝗶𝗼𝗺𝗻𝗶𝗕𝗲𝗻𝗰𝗵 the most helpful benchmark for biologists to understand how AI agents handle real-world biomedical tasks: where they can be trusted, and where they fall short. We're actively expanding our evaluation effort, and would love to engage the broader scientific community on what comes next.
📄 https://t.co/U1rh2QP9Ht
🤗 https://t.co/513AX8AQtJ
Thanks to our amazing @phylo_bio team (Minta Lu, @TuXinming , @serena2z , @TianweiShe , @lecong , @jure , @KexinHuang5 ) and our collaborators at @LaudeInstitute , @Stanford , @Harvard , @PKU1898 , @virginia_tech , Humanlaya Data Lab, Xbench: @alexgshaw , JOU-HO SHIH, Bingqing Zhao, Minjie Shen, Haochen Yang, Jielin Yan, Rongchuan Zhang, Xinze Wu, Tingting Li, Xiaobo Hu, Yuan Jiang, Jiayun Dong, Tao Peng.
🔥 Excited to share our latest work - Med-V1: Small Language Models for Zero-shot and Scalable Biomedical Evidence Attribution
Recent reports in @Nature and @TheLancet on fabricated citations have drawn substantial attention, but even real citations may fail to support the statements attached to them.
This makes evidence attribution — verifying if the citations really support the claims — essential for auditing both human- and AI-generated texts. As AI generates billions of medical references every day, we need a scalable model for this task.
In this work:
- We generated MedFact-Synth, a high-quality dataset of 1.5M synthetic claim-article pairs.
- Using MedFact-Synth, we trained and open-sourced Med-V1, a family of 3B-parameter LLMs.
- Med-V1 surpasses its backbone models by 27-71%, matching the performance of GPT-5.
- Med-V1 can be used to identify high-stakes misattributions and detect LLM hallucinations.
🔗 Paper: https://t.co/R5KmjDbjdJ
🔗 Model: https://t.co/aBu14MDMhI
🙌 Kudos to all our great collaborators: Yin Fang, Lauren He, Yifan Yang, Guangzhi Xiong, Zhizheng Wang, Nicholas Wan, Joey Chan, Donald Comeau, Robert Leaman, Charalampos Floudas, Aidong Zhang, Michael F. Chiang, Yifan Peng & Zhiyong Lu
#MedicalAI #HealthAI #LLMs #Hallucination #EvidenceBasedMedicine #ChatGPT
🧬 LESAI Clinical Pearl: Raynaud: Diferencias y Señales de Alerta
Mira, el fenómeno de Raynaud es cuando los dedos se ponen blancos o azules por el frío o estrés.
🎬 Watch: https://t.co/81ijYPnlAU
#Rheumatology#MedTwitter#ClinicalPearl
Currently testing various peptide manufacturers for purity analysis and customer experience, we’ll transparently publish COAs on chain
Big shoutout to @vrilpeptides for the quick shipping time
@peptai_ is also procuring its own stock for small scale trials and research purposes
The best self-driving lab in the world still stops and waits.
Not for equipment. For a human to decide what comes next.
The decision layer is what autonomous science needs🧵
Recent meta-analyses continue to downplay the link between RA and increased cardiovascular risk. But wait! The evidence is clear: patients with RA have a higher incidence of CV events—risk nearly doubles! It's high time for us to reconsider our screening and management strategies. Ignoring this is a disservice to our patients. Isn't it time we quit the complacency and act on the data? The ACR must step up here. 💜
Let’s talk about cardiovascular risk in rheumatoid arthritis—it's NOT just about traditional factors. The evidence is clear: RA itself promotes atherosclerosis through chronic inflammation. Studies show that patients with RA have a 50% increased risk of CV events compared to controls (Muller's cohort, Rheumatology, PMID: 27998948). Yet, many rheumatologists still overlook this. It’s time to make CV screening a standard part of RA management. We can't ignore the heart while treating the joints. Let's do better. 💜
Another IL-17A inhibitor (Vunakizumab) for active Ankylosing Spondylitis
Vunakizumab, a novel anti–interleukin (IL) 17A monoclonal antibody, was studied in patients with active radiographic axial spondyloarthritis [r-axSpA] and found to be effective and tolerable. https://t.
🧬 LESAI Clinical Pearl: Cuidado con el DAS28: A veces nos confunde
Mira, el DAS28 es una herramienta para medir la actividad de tu artritis, pero fíjate que no siempre cuenta toda la...
🎬 Watch: https://t.co/81ijYPnlAU
#Rheumatology#MedTwitter#ClinicalPearl
Lupus nephritis management has stagnated in too many practices. The AURORA trial (Rovin et al., NEJM 2021) demonstrated voclosporin's superiority over standard care with a 41% complete renal response vs. 23%. Yet, many still cling to outdated regimens. It’s time to embrace early intervention and rethink our approach. What's your experience using newer therapies? 💜