'Agent Harness Engineering: A Survey' just cited my Agent Skills for Context Engineering project in its Context & Memory Management section.
It’s a new paper on OpenReview (authors from CMU, Yale, Johns Hopkins, Amazon + others). They reviewed 170+ open-source projects and pulled real production lessons from OpenAI, Anthropic, and LangChain.
Agent performance in the real world = Model capability + Harness quality
For long-horizon, multi-step, production tasks, the harness has become the main bottleneck. Simple harness tweaks (better tool formats, sandbox changes, automated verification loops) deliver significant gains on benchmarks.
This is the second time my open-source work has been cited in academic research (first was Peking University’s State Key Lab paper on meta context engineering).
I’m genuinely proud of that, but more than anything it reminds me why I love open source. I’m not from academia. I learned this field by building, shipping, writing...
Open source lets your experiments enter the research papers. That is still one of the best parts of this field.
The paper is worth reading. We're moving from “build one agent” to “operate a fleet of long-running agents” and the paper repeatedly shows that the biggest improvements come from turning production traces into regression tests and automated harness fixes.
Paper & Repo: https://t.co/PAjqvOXedL
1/ World model research is fragmented: every paper reimplements its own data pipeline, baselines, and eval harness. Comparing two methods fairly is weeks of infra work.
𝘀𝘁𝗮𝗯𝗹𝗲-𝘄𝗼𝗿𝗹𝗱𝗺𝗼𝗱𝗲𝗹 is a new open-source platform that standardizes the whole thing: https://t.co/Gg3V3LhKJr
I’ve left Google DeepMind after an amazing chapter.
I’m incredibly grateful for the people I worked with, the things we built, and the lessons I learned from taking frontier AI research into production. DeepMind shaped how I think about research, product, evaluation, and what it takes to build AI systems at real scale.
As I wrap up this chapter, I wrote down something I’ve been thinking about a lot: evals.
We’re good at evaluating the models we have. We’re much worse at evaluating the models we’re about to build — especially if they cross into a new capability regime. We will have self-evolving models, but before that, we need self-evolving evaluations.
https://t.co/F1lUWxDG2D
Visiting most of the leading Chinese AI labs, I'm struck by a culture that's extremely well suited to building LLMs with fewer resources, but one happening in a very different ecosystem, more companies at play, almost no data industry, etc.
Full report: https://t.co/ibmtMWnfTc
Fireside chat at Sequoia Ascent 2026 from a ~week ago. Some highlights:
The first theme I tried to push on is that LLMs are about a lot more than just speeding up what existed before (e.g. coding). Three examples of new horizons:
1. menugen: an app that can be fully engulfed by LLMs, with no classical code needed: input an image, output an image and an LLM can natively do the thing.
2. install .md skills instead of install .sh scripts. Why create a complex Software 1.0 bash script for e.g. installing a piece of software if you can write the installation out in words and say "just show this to your LLM". The LLM is an advanced interpreter of English and can intelligently target installation to your setup, debug everything inline, etc.
3. LLM knowledge bases as an example of something that was *impossible* with classical code because it's computation over unstructured data (knowledge) from arbitrary sources and in arbitrary formats, including simply text articles etc.
I pushed on these because in every new paradigm change, the obvious things are always in the realm of speeding up or somehow improving what existed, but here we have examples of functionality that either suddenly perhaps shouldn't even exist (1,2), or was fundamentally not possible before (3).
The second (ongoing) theme is trying to explain the pattern of jaggedness in LLMs. How it can be true that a single artifact will simultaneously 1) coherently refactor a 100,000-line code base *and* 2) tell you to walk to the car wash to wash your car. I previously wrote about the source of this as having to do with verifiability of a domain, here I expand on this as having to also do with economics because revenue/TAM dictates what the frontier labs choose to package into training data distributions during RL. You're either in the data distribution (on the rails of the RL circuits) and flying or you're off-roading in the jungle with a machete, in relative terms. Still not 100% satisfied with this, but it's an ongoing struggle to build an accurate model of LLM capabilities if you wish to practically take advantage of their power while avoiding their pitfalls, which brings me to...
Last theme is the agent-native economy. The decomposition of products and services into sensors, actuators and logic (split up across all of 1.0/2.0/3.0 computing paradigms), how we can make information maximally legible to LLMs, some words on the quickly emerging agentic engineering and its skill set, related hiring practices, etc., possibly even hints/dreams of fully neural computing handling the vast majority of computation with some help from (classical) CPU coprocessors.
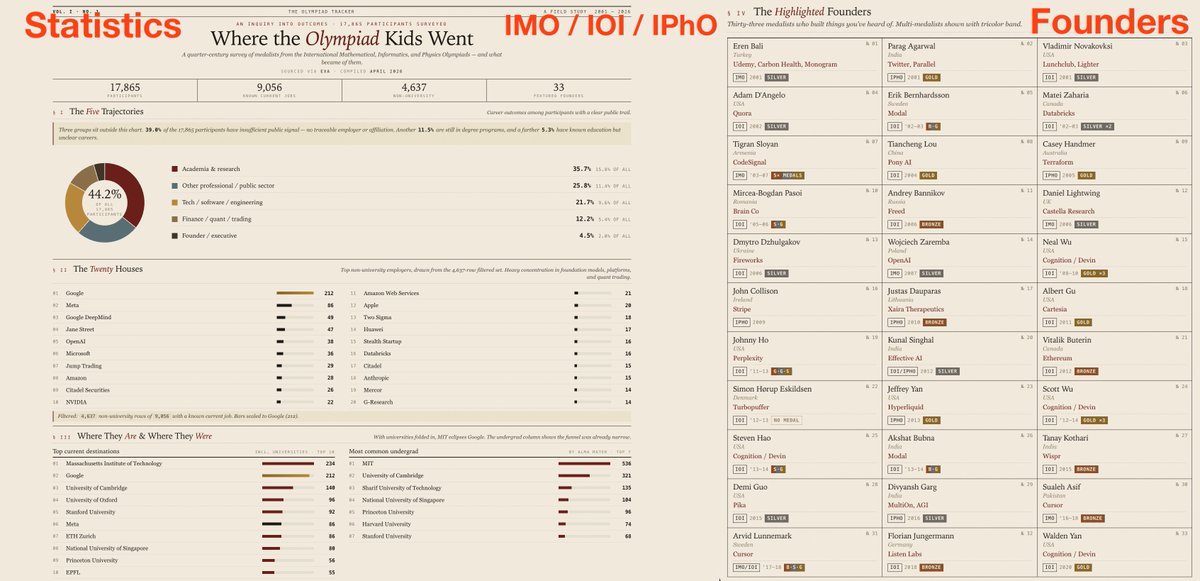
What do the smartest kids in the world do when they grow up?
I did the largest study of ~18,000 International Olympiad medalists (IMO, IOI and IPhO) over the last 25yrs, arguably the sharpest analytical minds of the world in high school, to see where they ended up and traced ~50% of them.
Founders of ~20 unicorns and ~7 decacorns and ~10 billionaires: OpenAI, Cursor, Stripe, Databricks, Perplexity, Ethereum, Cognition, Hyperliquid, Fireworks, Modal, Quora, Parallel, Cartesia, Wispr
Most kids went to MIT, a whopping 12% of them, followed by Cambridge (7%) and Sharif (3%)!
The career paths they chose (of those who graduated) were:
— 36% Academia (professors)
— 26% Other
— 22% in Software / Tech
— 12% in Quant / Finance
— 5% Founders!
The biggest employer was Google, by far, at 6%.
Others interesting tidbits were:
— 47 of them work at Jane Street (#3)
— 38 at OpenAI (#5)
— 15 at Anthropic
— 8 at Cognition
— 6 at Isomorphic Labs
Olympiaders were 1500x more likely to be billionaires and 4000x more likely to be unicorn founders than the average person!
https://t.co/JnhJ1Ll8eC
“How people are using ChatGPT:
Largest study to date of consumer ChatGPT usage shows demographic gaps shrinking, economic value being created through both personal and professional use.”
Diffusion Beats Autoregressive in Data-Constrained Settings
Comparison of diffusion and autoregressive language models from 7M to 2.5B params and up to 80B training tokens.
Key findings:
1. Diffusion models surpass autoregressive models given sufficient compute. Across a wide range of unique token budgets, AR models initially outperform diffusion models at low compute, but quickly saturate. Beyond a critical compute threshold, diffusion models continue improving and ultimately achieve better performance.
2. Diffusion models benefit far more from repeated data. While AR models can effectively use repeated data for up to 4 epochs, diffusion models can be trained on repeated data for up to 100 epochs with repeated data almost as effective as fresh data.
3. Diffusion models have a much higher effective epoch count. We find
for diffusion models compared to
for AR models, suggesting diffusion models can benefit from repeated data over far more epochs without major degradation.
4. Critical compute point follows a power law with dataset size. We derive a closed-form expression that predicts when diffusion becomes the favorable modeling choice for any given dataset size.
5. Diffusion models yield better downstream performance. The validation loss improvements translate to consistent gains across diverse downstream language tasks.
@andrewgwils I was most interested in posters,but few realized I was a VC, most thought I was another academic. But if I reveal I was a VC, some turned away, almost feeling like you are not going to be reviewing my paper so I care less.
I believe all professors in the field of AI and machine learning at top universities need to face a soul-searching question: What can you still teach your top (graduate) students about AI that they cannot learn by themselves or elsewhere? It had bothered me for quite some years before I finally decided to face it the hard way a couple of years ago.
AI for Scientific Search
AI for Science is where I spend most of my time exploring with AI agents.
This 120+ pages report does a good job of highlighting why all the big names like OpenAI and Google DeepMind are pursuing AI4Science.
Bookmark it!
My notes below:
What is key of agent decision making? Is there a decision making boundary?
I am always thinking of the potential boundary of correct decision making and the uncertainty of this boundary.
The alignment of decision making boundary and tool-use boundary led by @WangCarrey @qiancheng1231 is a nice way to understand how agent abilities emerge. If you are interested, welcome to talk more with us!
🚨 Data drop!
Our team @a16z published benchmarks on revenue growth for AI startups, from our proprietary dataset
The median B2B co is going 0 -> $2.1M ARR in year 1, while the median B2C co is going $0 -> $4.2M
(yes, consumer startups are growing revenue faster 🤯)