I am glad to announce that we will present our last paper: « Emergent communication: Generalization and Overfitting in Lewis Games » has been accepted to #NeurIPS2022 🎷🎷.
with C.Tallec, @pmichelX , JB.Grill, O.Pietquin, E.Dupoux & F.Strub.
🖱️https://t.co/KkAhSS1KZP
🧵1/13
🥳 Recording of our workshop is now publicly available at https://t.co/Jp96Z0WmGF!
We highly recommend the panel discussion, especially the debate on inductive bias for learning 😆
Interested in working on Gemini pre-training?
I'm hiring a research scientist to work on pre-training data @GoogleDeepMind in London: https://t.co/TZZFUZ1CmP
I am unfortunately not at #NeurIPS2024 but feel free to reach out to ask questions or see the team at the booth there!
New paper w/@LukasGalke! We identify several key pressures for language learning and emergence by reviewing 3 mismatches between how humans👥 and deep neural networks🤖(LLMs & emergent communication agents) behave when learning to communicate from scratch: https://t.co/XKxL5PqeJo
I am hiring an intern in our Llama team for 2025! Near the end of PhD completion, willing to be based out of Paris. You will succeed @MekalaDheeraj, work around frontier LLMs, tool use, agents, and more :)
Please apply here: https://t.co/i8x7e2pavd
I’m looking for a PhD intern for next year to work at the intersection of LLM-based agents and open-ended learning, part of the Llama Research Team in London.
If interested please send me an email with a short paragraph with some research ideas and apply at the link below.
🚀 Exciting Post-Doc Opportunity! 🚀
Join the CoML team for the new ERC project InfantSimulator ! If you're passionate about language modeling & machine learning, apply now ! @ENS_ULM
📍 Paris
🔗 https://t.co/C8LskSopb2
#PostDoc#CognitiveScience#LanguageModeling#Job#AI
Our team, Llama Post-training, is looking to hire 2025 PhD Research Interns to join us at Meta GenAI. If you are interested in working on RL for LLM, Code Generation, Reasoning, and Agents with us, drop me a message with your CV.
Link: https://t.co/4jnsijxGgm
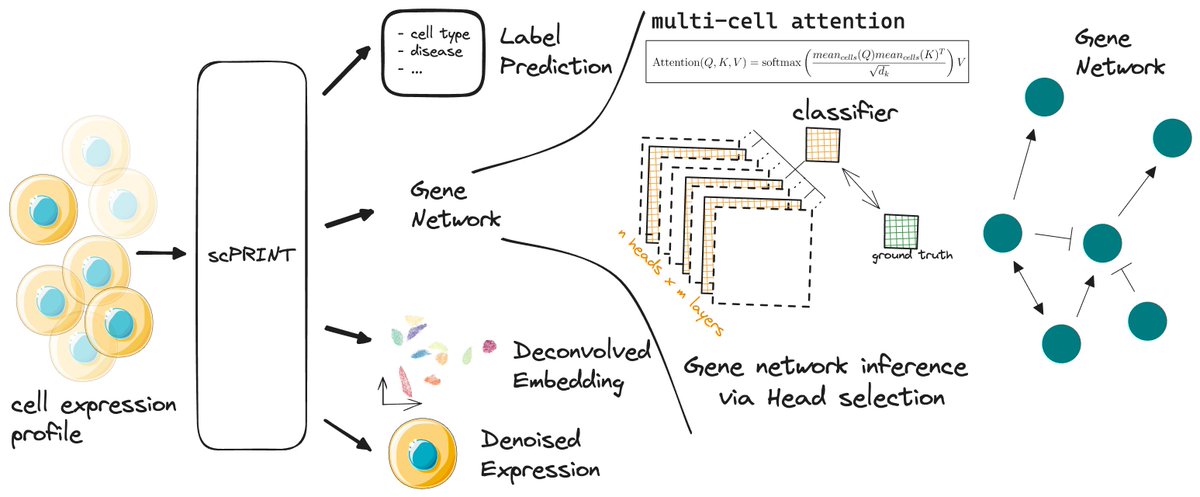
This allows scPRINT zero-shot abilities -meaning no fine-tuning required- such as artificially increasing the depth of the expression profile of a cell (denoising / zero imputation), predicting the cell type, disease, sequencer, and sex of a cell, as well as creating cell embeddings 💪 .
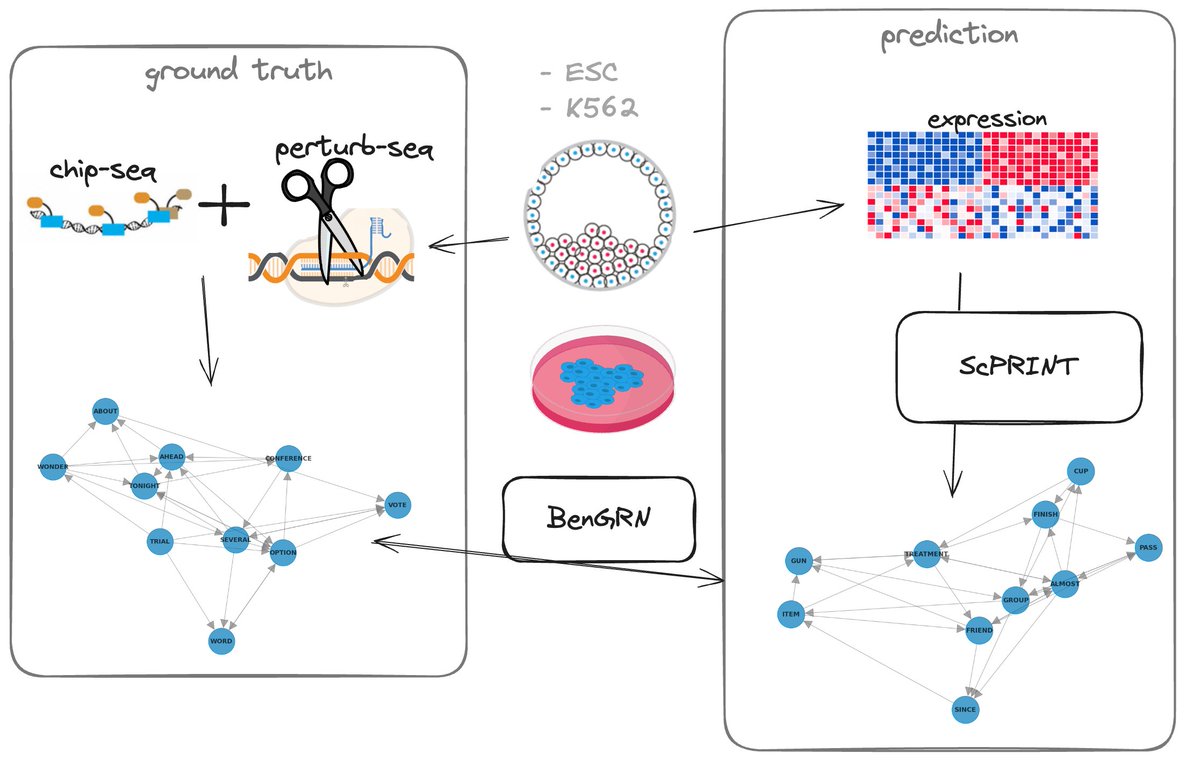
But one of the key abilities we dived into is its inference of gene networks. We get inspired by ESM2 to design a way to extract gene networks from pre-trained transformers, which we call Large Cell Models. We extensively validate the gene network inference abilities of scPRINT, scGPT, and GENIE3, with our suite of benchmarking tools called BenGRN and GRnnData: https://t.co/FazHZYkzAO https://t.co/l9E2oFOvBj
Moreover, we don’t just release the code and the model weigths for scPRINT, but also its pre-training strategies, thanks to our dataloader and LaminDB’s new mapped dataset methods https://t.co/0wp5CsgUCK. https://t.co/JL9N3DdStx.
Taken together, the goal of these open source tools is to serve as a bedrock for future Large Cell Models developments. To improve -and possibly debug issues in- these transformer models by interrogating and benchmarking their abilities in a reproducible manner 🌍 👥.
We need to understand how the cell works but for that we need to know know what works and what doesn’t. This is my contribution to it. While still somehow a WIP, we have defined an extensive ablation study analysis with scPRINT that allows users to change. Models can be pre-trained on only one GPU for the small and medium size models and “only” 4 to 16 GPUs for the larger sized ones. 🚄
🏔️ The very large model is still undergoing training and testing. I am very happy to start building in public now and eager to see what the community will do with these tools. Do contact me if you would like to collaborate and have a try at the tool! I will provide more updates to the package and publish it on pypi in a week or so. But first.. a couple of days off! 🌴☀️ 🫡
🙏🙏🙏 I would like to thank additional collaborators from laminDB, as well as members of the Cantini Lab and Peyré Lab: @JulesSamaran , @TrimbourR , @gjhuizing , Anna Audit and @wariobrega. But most of all, my 2 great P.I.s: @LauCan88 and @gabrielpeyre 🇫🇷 🎓
💯 🙏 Also, I would like to acknowledge the important pioneering work from Geneformer, UCE, scFoundation and scGPT. Thanks to FlashAttention, pytorch, lightning, and scanpy for their toolkits. Thanks to Omnipath, Scenic+, Openproblems, Replogle et al. and Mc Calla et al. for their ground truths and benchmarking tools (all links and citations are in the paper).
🙏🙏🙏 and thanks to Christina Theodoris (@TheodorisLab), @YanayRosen, @wiatrak_maciej, @Mathieu_Rita, @howmanyernest1, @PauBadiaM, @mo_lotfollahi, @m_e_sander and Felix Fischer for the interesting discussions!!
💥BOOM 💥 Llama 3.1 is out 💥
405B, 70B, 8B versions.
Main takeaways:
1. 405B performance is on par with the best closed models.
2. Open/free weights and code, with a license that enables fine-tuning, distillation into other models, and deployment anywhere.
3. 128k context length, multi-lingual abilities, good code generation performance, complex reasoning abilities, tool use.
4. Llama Stack API for easy integration.
5. Ecosystem with over 25 partners, including AWS, NVIDIA, Databricks, Groq, Dell, Azure, and Google Cloud.
Blog post: https://t.co/nEPcbRBbA2
Llama home: https://t.co/YKSBRvirBL
Exciting new blog -- What’s up with Llama-3?
Since Llama 3’s release, it has quickly jumped to top of the leaderboard. We dive into our data and answer below questions:
- What are users asking? When do users prefer Llama 3?
- How challenging are the prompts?
- Are certain users or prompts over-represented?
- Does Llama 3 have qualitative differences that make users like it?
Key Insights:
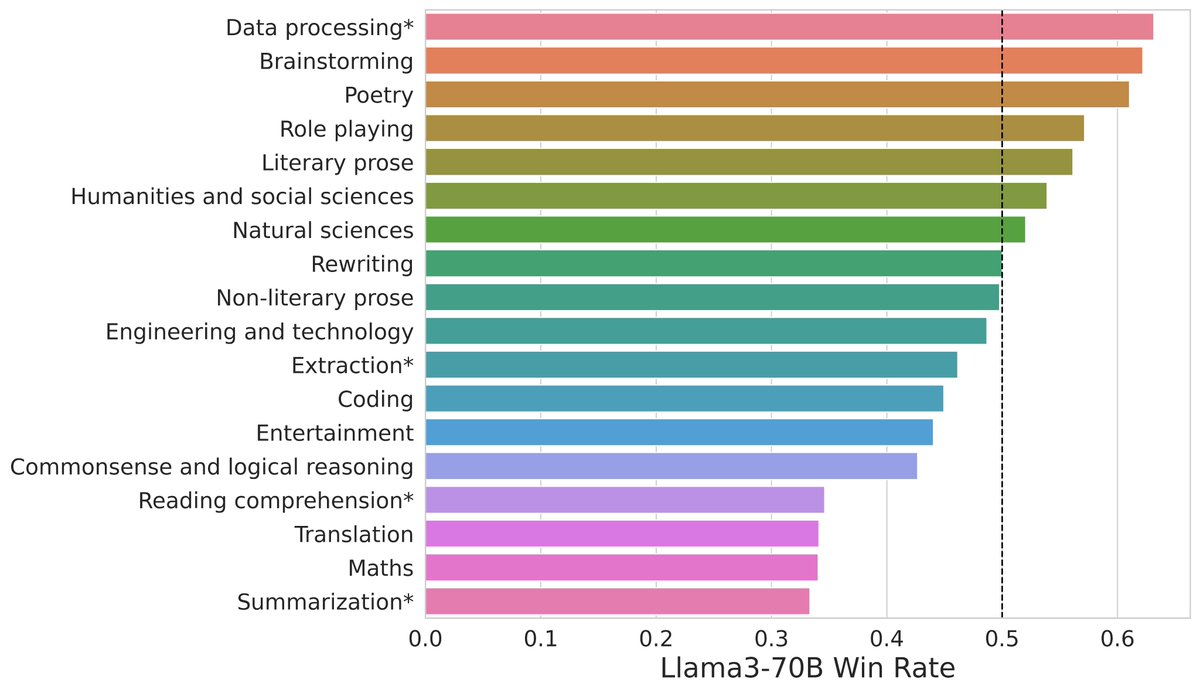
1. Llama 3 beats top-tier models on open-ended writing and creative problems but loses a bit on close-ended math and coding problems.
We had a small party to celebrate Llama-3 yesterday in Paris! The entire LLM OSS community joined us with @huggingface, @kyutai_labs, @GoogleDeepMind (Gemma), @cohere
As someone said: better that the building remains safe, or ciao the open source for AI 😆
Moreover, we observe even stronger performance in English category, where Llama 3 ranking jumps to ~1st place with GPT-4-Turbo!
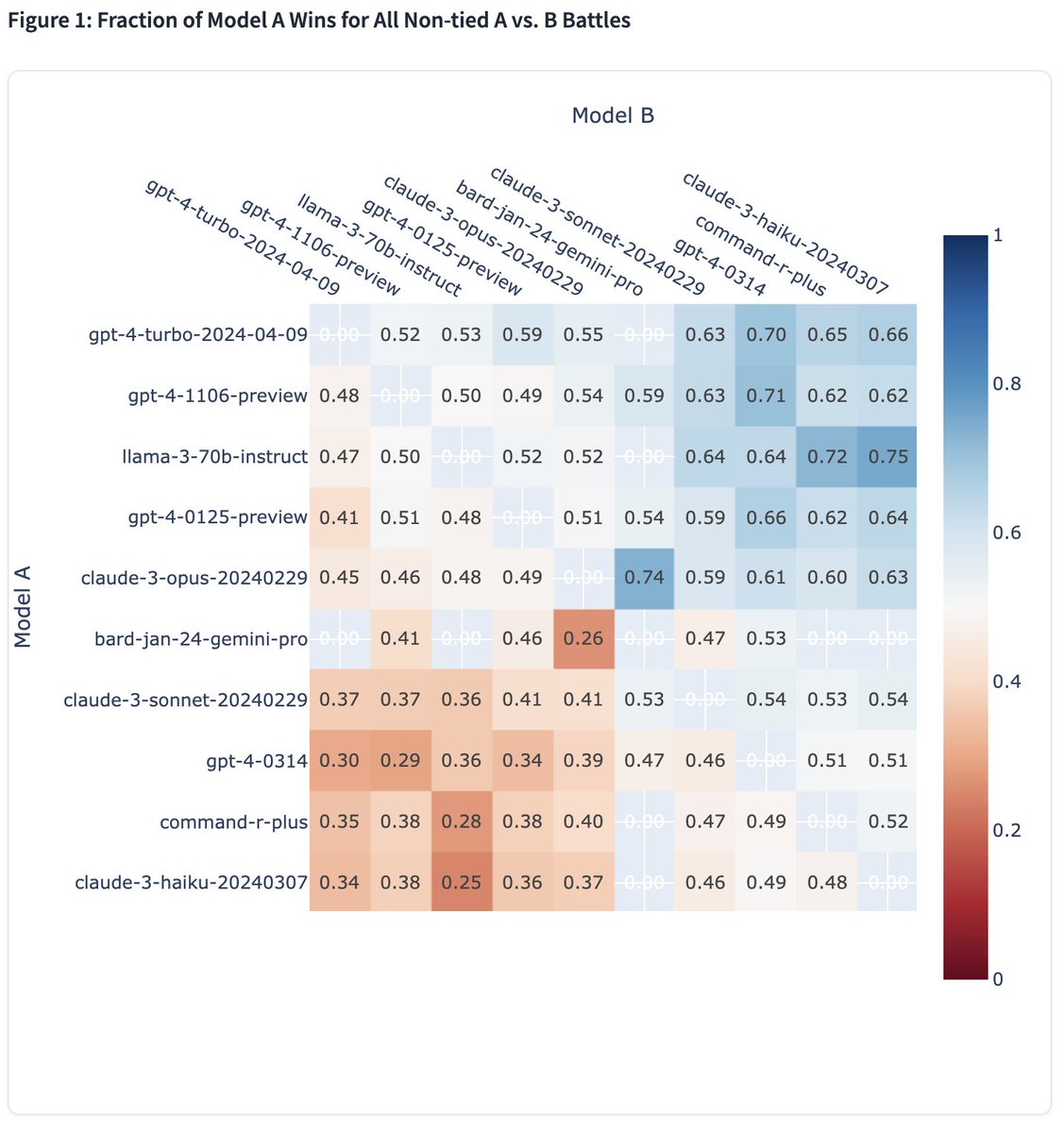
It consistently performs strong against top models (see win-rate matrix) by human preference. It's been optimized for dialogue scenario with large amount of instruction data in post-training.
More analysis still ongoing with topic distribution and agreement study. We also look forward to details in Llama-3's technical report.
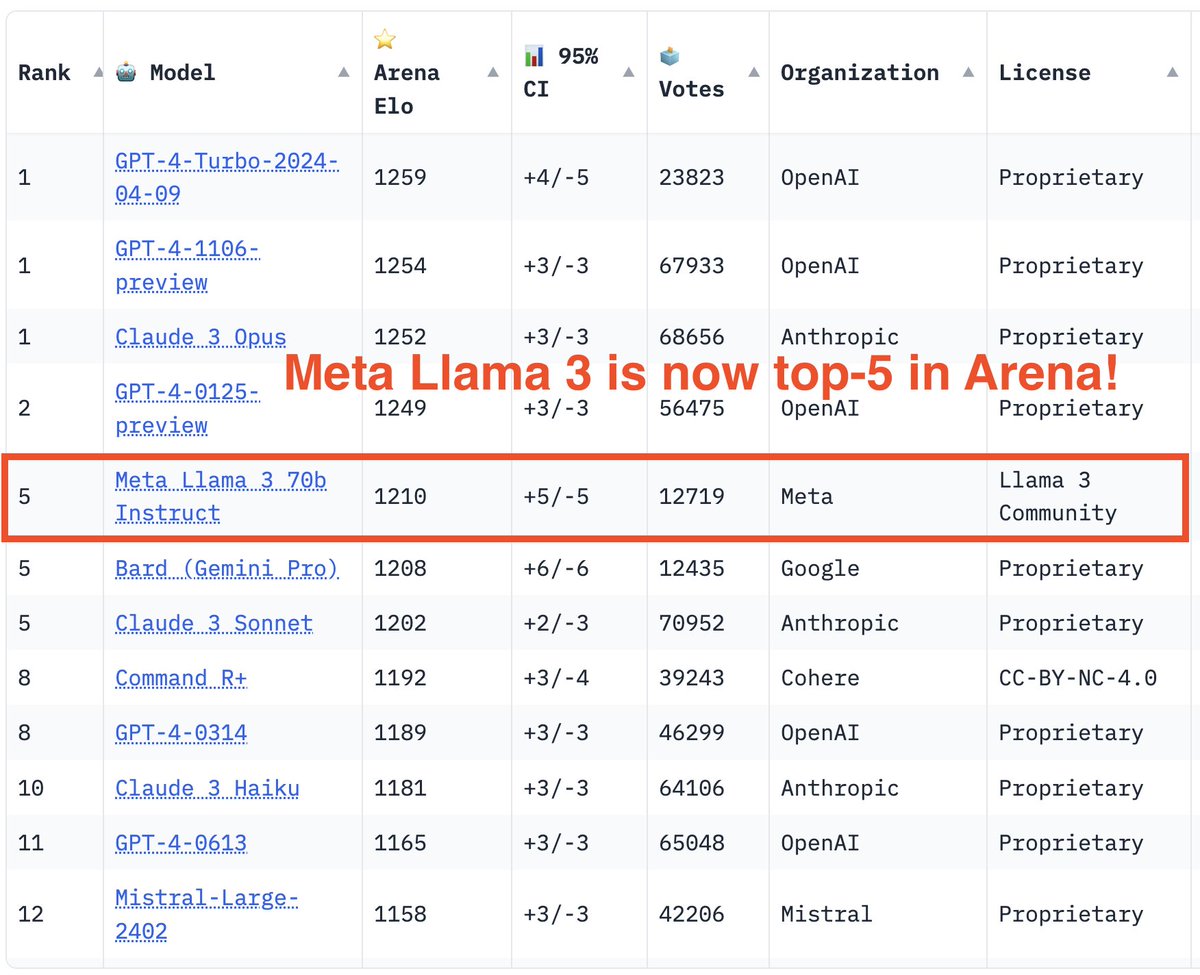
Exciting update -- Llama-3 full result is out, now reaching top-5 on the Arena leaderboard🔥
We've got stable enough CIs with over 12K votes. No question now Llama-3 70B is the new king of open model. Its powerful 8B variant has also surpassed many larger-size models. What an incredible launch!
Huge congrats to Llama team at @AIatMeta and for such valuable contribution to open community! Can't wait to see the 400B.
Introducing Meta Llama 3: the most capable openly available LLM to date.
Today we’re releasing 8B & 70B models that deliver on new capabilities such as improved reasoning and set a new state-of-the-art for models of their sizes.
Today's release includes the first two Llama 3 models — in the coming months we expect to introduce new capabilities, longer context windows, additional model sizes and enhanced performance + the Llama 3 research paper for the community to learn from our work.
More details ➡️ https://t.co/nFll4exicO
Download Llama 3 ➡️ https://t.co/Ps0OAHt0RR
[CL] Language Evolution with Deep Learning
M Rita, P Michel, R Chaabouni, O Pietquin, E Dupoux, F Strub [INRIA & Google DeepMind] (2024)
https://t.co/yKz8saxRfU
- Deep learning is well-suited for simulating communication games and studying language emergence and evolution.
- Communication games can be formalized as a multi-agent machine learning problem where agents are represented by deep neural networks.
- Communicative agents are designed using functional modules: perception, generation, understanding, and action. Neural networks can be used to model these modules.
- Various neural architectures like MLPs, CNNs, RNNs and Transformers can be used to implement the agents' modules depending on the input data type and task.
- Optimization techniques like supervised learning and reinforcement learning are used to train the agents to develop a shared communication protocol and solve the game.
- The Visual Discrimination Game is a common case study in emergent communication research with neural agents.
- Recent work has explored more realistic simulations beyond simple referential games, such as embodied agents in 2D worlds.
- Despite successes, current simulations have limitations in realism and the languages that emerge are still far from natural languages.
Meta presents SpiRit-LM
Interleaved Spoken and Written Language Model
paper page: https://t.co/ESqeR4BzYu
introduce SPIRIT-LM, a foundation multimodal language model that freely mixes text and speech. Our model is based on a pretrained text language model that we extend to the speech modality by continuously training it on text and speech units. Speech and text sequences are concatenated as a single set of tokens, and trained with a word-level interleaving method using a small automatically-curated speech-text parallel corpus. SPIRIT-LM comes in two versions: a BASE version that uses speech semantic units and an EXPRESSIVE version that models expressivity using pitch and style units in addition to the semantic units. For both versions, the text is encoded with subword BPE tokens. The resulting model displays both the semantic abilities of text models and the expressive abilities of speech models. Additionally, we demonstrate that SPIRIT-LM is able to learn new tasks in a few-shot fashion across modalities (i.e. ASR, TTS, Speech Classification).
We released a 70B version of CodeLlama today! Trained on 1T tokens, it is a much stronger base model for coding tasks. I look forward to seeing what the community will do with it! :)
[🚨Recruitment🗣️]
CoML team is actively recruiting a Postdoctoral Fellow with expertise in machine learning, linguistics, or cognitive science. More information in the detailed announcement here : https://t.co/jZeiWxupq9














![fly51fly's tweet photo. [CL] Language Evolution with Deep Learning
M Rita, P Michel, R Chaabouni, O Pietquin, E Dupoux, F Strub [INRIA & Google DeepMind] (2024)
https://t.co/yKz8saxRfU
- Deep learning is well-suited for simulating communication games and studying language emergence and evolution.
- Communication games can be formalized as a multi-agent machine learning problem where agents are represented by deep neural networks.
- Communicative agents are designed using functional modules: perception, generation, understanding, and action. Neural networks can be used to model these modules.
- Various neural architectures like MLPs, CNNs, RNNs and Transformers can be used to implement the agents' modules depending on the input data type and task.
- Optimization techniques like supervised learning and reinforcement learning are used to train the agents to develop a shared communication protocol and solve the game.
- The Visual Discrimination Game is a common case study in emergent communication research with neural agents.
- Recent work has explored more realistic simulations beyond simple referential games, such as embodied agents in 2D worlds.
- Despite successes, current simulations have limitations in realism and the languages that emerge are still far from natural languages.](https://pbs.twimg.com/media/GJCEReSaUAAmbY5.jpg)
![fly51fly's tweet photo. [CL] Language Evolution with Deep Learning
M Rita, P Michel, R Chaabouni, O Pietquin, E Dupoux, F Strub [INRIA & Google DeepMind] (2024)
https://t.co/yKz8saxRfU
- Deep learning is well-suited for simulating communication games and studying language emergence and evolution.
- Communication games can be formalized as a multi-agent machine learning problem where agents are represented by deep neural networks.
- Communicative agents are designed using functional modules: perception, generation, understanding, and action. Neural networks can be used to model these modules.
- Various neural architectures like MLPs, CNNs, RNNs and Transformers can be used to implement the agents' modules depending on the input data type and task.
- Optimization techniques like supervised learning and reinforcement learning are used to train the agents to develop a shared communication protocol and solve the game.
- The Visual Discrimination Game is a common case study in emergent communication research with neural agents.
- Recent work has explored more realistic simulations beyond simple referential games, such as embodied agents in 2D worlds.
- Despite successes, current simulations have limitations in realism and the languages that emerge are still far from natural languages.](https://pbs.twimg.com/media/GJCERNibEAAQr_A.jpg)
![fly51fly's tweet photo. [CL] Language Evolution with Deep Learning
M Rita, P Michel, R Chaabouni, O Pietquin, E Dupoux, F Strub [INRIA & Google DeepMind] (2024)
https://t.co/yKz8saxRfU
- Deep learning is well-suited for simulating communication games and studying language emergence and evolution.
- Communication games can be formalized as a multi-agent machine learning problem where agents are represented by deep neural networks.
- Communicative agents are designed using functional modules: perception, generation, understanding, and action. Neural networks can be used to model these modules.
- Various neural architectures like MLPs, CNNs, RNNs and Transformers can be used to implement the agents' modules depending on the input data type and task.
- Optimization techniques like supervised learning and reinforcement learning are used to train the agents to develop a shared communication protocol and solve the game.
- The Visual Discrimination Game is a common case study in emergent communication research with neural agents.
- Recent work has explored more realistic simulations beyond simple referential games, such as embodied agents in 2D worlds.
- Despite successes, current simulations have limitations in realism and the languages that emerge are still far from natural languages.](https://pbs.twimg.com/media/GJCERJ4boAAdLqq.jpg)










![fly51fly's tweet photo. [CL] Language Evolution with Deep Learning
M Rita, P Michel, R Chaabouni, O Pietquin, E Dupoux, F Strub [INRIA & Google DeepMind] (2024)
https://t.co/yKz8saxRfU
- Deep learning is well-suited for simulating communication games and studying language emergence and evolution.
- Communication games can be formalized as a multi-agent machine learning problem where agents are represented by deep neural networks.
- Communicative agents are designed using functional modules: perception, generation, understanding, and action. Neural networks can be used to model these modules.
- Various neural architectures like MLPs, CNNs, RNNs and Transformers can be used to implement the agents' modules depending on the input data type and task.
- Optimization techniques like supervised learning and reinforcement learning are used to train the agents to develop a shared communication protocol and solve the game.
- The Visual Discrimination Game is a common case study in emergent communication research with neural agents.
- Recent work has explored more realistic simulations beyond simple referential games, such as embodied agents in 2D worlds.
- Despite successes, current simulations have limitations in realism and the languages that emerge are still far from natural languages.](https://pbs.twimg.com/media/GJCERqLbQAAvLQC.jpg)






























