Turn your lean team’s agility into a competitive powerhouse with this 4-step strategic playbook.
Within each step, you’ll find practical use cases and tips to help you move from simple pilots to complex agentic workflows in no time.
Get the guide → https://t.co/QH302Z9PYs
The GitHub Copilot app is now generally available. 🙌
The new home base for your work. Pick up what's next, direct agents in parallel, and land your PRs, all in one place. ⬇️
https://t.co/CzGspjw66P
It’s now easier to move local agents to the cloud so they can keep working with your laptop closed.
Prompt Cursor from your phone, run many agents in parallel, and get back PRs with demos of their work.
Claude Code users on Team and Enterprise plans gained access to Artifacts, new interactive pages that can be built based on their Claude Code sessions.
Every session is an Artifact now 👀
Un ingeniero de Netflix ha sacado algo tremendo.
¡Promete ahorrarte hasta el 95% de los tokens!
¿Cómo? Comprime tu contexto antes de enviarlo a la IA.
100% en local y compatible con Claude, Cursor, Codex...
24K estrellas en GitHub:
https://t.co/v4Ka8gmGV9
Just caught up with the recent GLM-5.2 release. The best open-weight model today.
Architecture-wise, it's build on the GLM-5 and GLM-5.1 architecture that I covered previously, which means it's reusing the Multi-head Latent Attention (MLA) and DeepSeek Sparse Attention (DSA) mechanisms from DeepSeek V3.2. (I wrote about it here: https://t.co/tuunazfQ8y)
What's new is that they added an IndexShare mechanism. (That's a cross-layer reuse trick for DSA where instead of recomputing the sparse-attention top-k indexer in every layer, GLM-5.2 runs the full indexer only once every four layers and lets the following layers reuse those selected token indices. This keeps the same DSA idea but makes 1M-token inference much cheaper.)
New in Claude Code: Artifacts.
Interactive pages built from your session, like a PR walkthrough or a living project dashboard, shared with your team at a private link.
Available in beta on Team and Enterprise plans.
GPT-5.5 Instant is now on par with our frontier Thinking models for health-related questions.
Every week, more than 230 million people turn to ChatGPT with health and wellness questions, and GPT-5.5 Instant is better at recognizing when urgent care may be needed, asking for relevant context, explaining uncertainty, and making complex information easier to understand.
Because GPT-5.5 Instant is available to all free users in ChatGPT, these improvements can help more people.
Physician-led evaluation was critical to making these major intelligence gains.
Show Codex a workflow once. Reuse it as a skill.
Record & Replay lets you show Codex a recurring task, like filing an expense report or submitting a time-off request.
Codex turns that demo into an inspectable, editable skill.
You control when recording starts and stops.
🚀 The latest @code release just expanded your AI model options.
Discover and install extra providers from the Marketplace right inside the editor. Just browse, install, and your new models show up in the picker!
"Variable-Width Transformers"
This paper shows that width should be allocated unevenly, with models wide at the start and end but narrow in the middle.
So the bottleneck forces better use of representations instead of wasting capacity in collapsed middle layers.
The "> <former" beats parameter matched Transformers from 200M to 2B dense models and 3B MoE, while using less FLOPs and smaller KV cache.
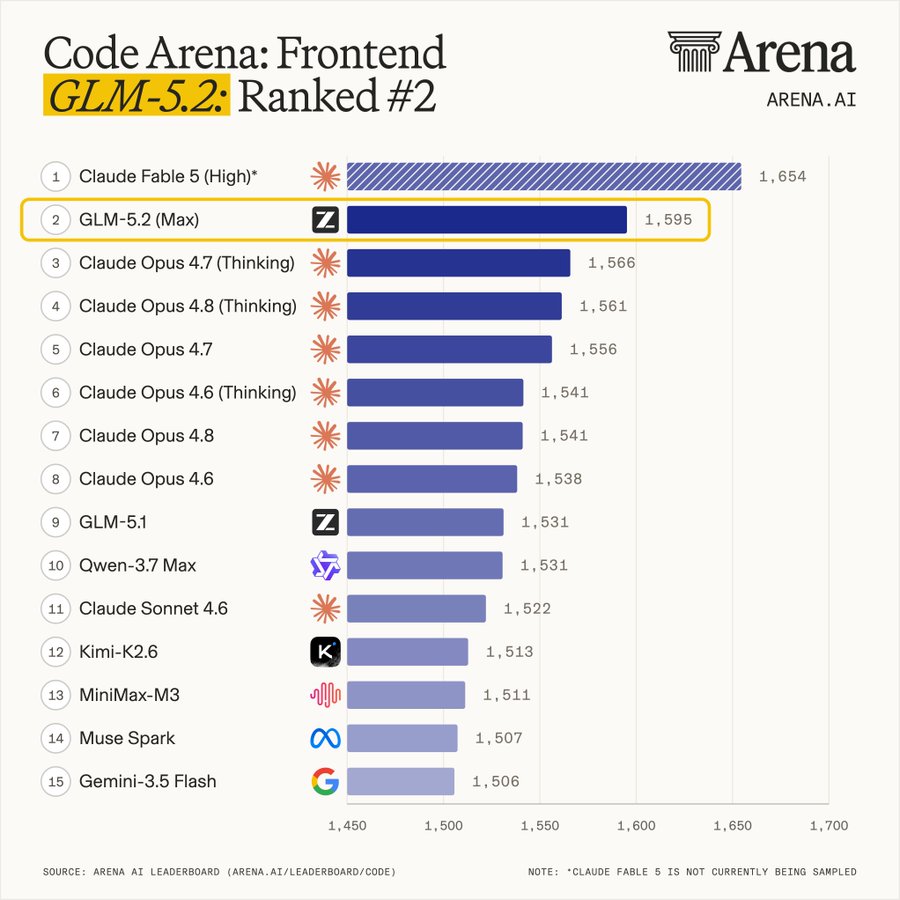
GLM-5.2 Max reached second place in the Code Arena Frontend leaderboard, behind only the currently unavailable Claude Fable 5.
The model scored 1595, placing it 29 points ahead of Claude Opus 4.7 Thinking.
It also ranked:
• #2 for React
• #4 for HTML
• First or near-first across categories including brand and marketing, reference-based design, data and analytics, consumer products, gaming, and simulations
Kimi K2.7 Code by @Kimi_Moonshot is 5th overall among open weight models on Design Arena with an Elo of 1312.
This is in the same performance band as MiniMax M3 by @MiniMax_AI. With an average generation time of 337.6 seconds, Kimi K2.7 Code is 78.8 seconds faster than Kimi K2.6 on average.
@Kimi_Moonshot is among the top 2 open-weights AI model labs and top 3 labs overall on Design Arena.
Congrats to the @Kimi_Moonshot team for this accomplishment!
We gave GLM-5.2 and Kimi K2.7 Code the same backend task: plan a feature flag service, then build it.
What separated them was decision-making, not code quality.
GLM's plan scored 9.0. Kimi's scored 8.1.
GLM-5.2 can now be run locally!🔥
The 2-bit model retains ~82% accuracy after we shrunk it from 1.51TB to 238GB (-84% size).
Run on a 256GB Mac or RAM/VRAM setups.
GLM-5.2 is the strongest open model to date.
Guide: https://t.co/bI7FeeKHDd
GGUF: https://t.co/BMkxswdj5N
We are pleased to highlight an excellent community model from developer : Qwen3.6-27B-MTP-pi-reasoning-GGUF.
Built on our Qwen3.6-27B base model, this release focuses on optimizing automated programming and debugging workflows for local coding agents.
If you are exploring local AI coding assistants, we encourage you to test this model in your environment.
What happens when speech, transcription, and coding models work together?
This prototype demo, built using a VS Code fork, showcases how MAI-Transcribe, MAI-Voice, and MAI-Code-1-Flash can work together in a unified workflow to transform spoken instructions into working code.