If you’re on mobile you can now download @ParallelTCG and play it on your phone - it’s available globally for everyone. //
iOS app: https://t.co/tzMZghHRNA
Android app: https://t.co/5SMQWN3HOw
Computer use is now in Claude Code.
Claude can open your apps, click through your UI, and test what it built, right from the CLI.
Now in research preview on Pro and Max plans.
NEW AI report from Google.
Every prior intelligence explosion in human history was social, not individual.
These authors make the case that the AI "singularity" framed as a single superintelligent mind bootstrapping to godlike intelligence is fundamentally wrong.
This is directly relevant to anyone designing multi-agent systems.
They observe that frontier reasoning models like DeepSeek-R1 spontaneously develop internal "societies of thought," multi-agent debates among cognitive perspectives, through RL alone.
The path forward is human-AI configurations and agent institutions, not bigger monolithic oracles.
This reframes AI scaling strategy from "build bigger models" to "compose richer social systems."
It argues governance of AI agents should follow institutional design principles, checks and balances, role protocols, rather than individual alignment.
Paper: https://t.co/bfwrnbkY2y
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
The new M5 Pro/Max MacBooks have 3 Thunderbolt 5 ports, enabling you to create RDMA clusters with up to 4 MacBooks.
The latency with RDMA over Thunderbolt is single digit microseconds, fast enough for tensor parallelism with close to linear scaling.
THEY DID IT.
The SEC and CFTC just dropped a landmark document that officially classifies crypto assets.
They're actually telling us which crypto assets are securities and which ones aren't - by name!
THIS IS SOMETHING GENSLER REFUSED TO DO
(he focused on prosecuting crypto out of existence)
This rule doc gives crypto many of the benefits of the clarity bill - it lifts us out of the gray market - it gives every asset a path.
It's almost like the Clarity act just passed by way of regulator.
(of course, the actual clarity act will harden all this into legislation and make it irreversible in the event we get another Gensler, we still want it)
This rule says there's 5 categories for crypto assets:
1) Digital Commodities - assets tied to a functional, decentralized crypto system (e.g., BTC, ETH, SOL, XRP, ADA, DOGE). Not securities. (yes, they name them on page 14)
2) Digital Collectibles - NFTs, meme coins, artwork tokens, in-game items. Not securities (fractionalized collectibles may be an exception).
3) Digital Tools - membership tokens, credentials, domain names (e.g., ENS). Not securities.
4) Stablecoins - payment stablecoins under the GENIUS Act are not securities. Other stablecoins, it depends.
5) Digital Securities - tokenized versions of traditional securities. Like tokenized stocks. Always securities.
Amazing! This makes so much sense I can't believe it's coming from a regulator.
No more enforcement threats to Ethereum developers and crypto exchanges.
How about the Howey test?
More common sense! If an issuer makes specific promises of managerial efforts from which buyers expect profits, the offering is a security until those promises are fulfilled. Then it's a commodity. The asset itself was never the security, the deal around it was. (E.g. XRP was a security pre launch, became a commodity after).
How about stuff like staking and mining?
Mining? Not a securities transaction.
Staking? Also not a securities transaction, that includes custodial and liquid staking even with LSTs!
How about wrapping BTC? Not a securities transaction.
Airdrops? NOT SECURITIES. NO MORE GEO BANS PROTECTING AMERICANS from free airdrops.
Remember this is a joint doc from the SEC and CFTC, They're actually cooperating on this, no internal strife, this is binding to both.
SEC regulates $80-100 trillion assets
CFTC regulates $5-10 trillion assets
Both of the world's largest capital markets are showing us that crypto assets are here to stay and they're welcome alongside traditional assets.
Every country will follow.
This is the biggest move toward legitimacy I've seen in all my time in crypto. Maybe bigger than the genius act since is covers all crypto assets.
Well done @MichaelSelig and @SECPaulSAtkins.
And especially well done to the indefatigable @HesterPeirce. Her fingerprints are all over this, couldn't have happened without her eight years of principles-based curiosity.
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
https://t.co/WAz8aIztKT
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.
My information consumption is now 1/4 X, 1/4 podcast interviews of the smartest practitioners, 1/4 talking to the leading AI models, and 1/4 reading old books. The opportunity cost of anything else is far too high, and rising daily.
(1/8) 실버 폭락, KOSPI 폭락, 유가 급등을 사전예고한 모델이 있다면?
AI가 유가 급등을 미리 알려줬다 — FinAgent 실전 사례 (3)
USO, 이게 뭔지부터 짚고 가죠
USO는 United States Oil Fund, 쉽게 말하면 "원유 가격을 따라가는 ETF"예요. 유가가 오르면 USO도 오르고, 유가가 떨어지면 USO도 떨어지죠.
앞선 두 편에서는 실버 폭락(1편)과 한국시장 폭락(2편)을 AI가 미리 경고해서 손실을 피한 사례를 다뤘어요. 이번 편은 반대예요. 급락이 아니라 급등을 미리 잡아낸 사례거든요.
2026년 3월 초, 호르무즈 해협 위기가 터지면서 유가가 치솟았어요. 대부분의 투자자들은 뉴스가 터진 뒤에야 "아, 유가가 올랐네. 또는 미국이 압도적인 상황인데 70~80달러면 이제 꼭지 아닌가?" 했지만, FinAgent의 AI(https://t.co/c6vy9JBwo5)는 그 전부터 지금까지 지속적으로 매수 신호를 보내고 있습니다.
This is the first AI cut.
And it will send shockwaves.
Remember: Jack is one of the greatest founders of all time. He created this platform that we’re all on, and has been early to many technological shifts. And Block was doing very well as a business.
So, for him to cut 40% of headcount in this way is a signal to everyone in tech: get good now. Become indispensable. Work nights and weekends. Learn the AI tools and raise your game. Or you might not make the cut, as an employee or as a company.
I know. That sucks. But capitalism is natural selection. The market is unforgiving, because you are the market. After all, it’s not like you’re buying some random gallon of milk from the store; you’re always buying the best product at the best price.
So too for apps: your customers are always installing the best piece of code they can get. And because AI is going to create new winners, if you aren’t the best in your market, someone may become better with AI. Particularly with the new agentic workflows.
To be clear: Block’s severance is generous by any measure. 20 weeks of pay, six months of health insurance and vested equity, all of that goes far beyond any typical package. Jack did his level best to cushion the disruption. The laid off are a temporarily unfortunate class, as opposed to a permanent underclass.
But had he not leaned into the AI transition, he might have had to lay off more people, slowly, and over time, as faster competitors went after his market share.
How would they do that? Sure, AI isn’t a panacea by any means, but the closer you are to software engineering the more aggressively you need to embrace agentic workflows. The AI companies are already doing that, and places like Stripe, Shopify, Coinbase, and now Block are pushing hard on this area.
There will be overcorrection. But the fundamental technical innovation is real. And you need to either disrupt yourself or get disrupted.
AI assistants like Claude can seem shockingly human—expressing joy or distress, and using anthropomorphic language to describe themselves. Why?
In a new post we describe a theory that explains why AIs act like humans: the persona selection model.
https://t.co/Gc3q0Dzq7Z
(1/4) 개인적으로 투자 관련 데이터 모아보던 투자 대시보드에 AI 에이전트 들을 붙여 봤습니다. 매일 시장 상황을 종합해 10개의 투자 아이디어를 뽑고 한달간 성과를 봤더니, 생각보다 성과가 좋아(승률 80%이상, 평균 초과수익률 6%p 이상) 아예 라이브로 박제하고 검증해 보려고 합니다.
링크: https://t.co/c6vy9JBwo5
#AI투자 #AIAgent #FinAgent #투자아이디어 #사이드프로젝트
Nice paper studying whether agents can generate their own procedural knowledge.
This is very important to build more reliable self-improving agents.
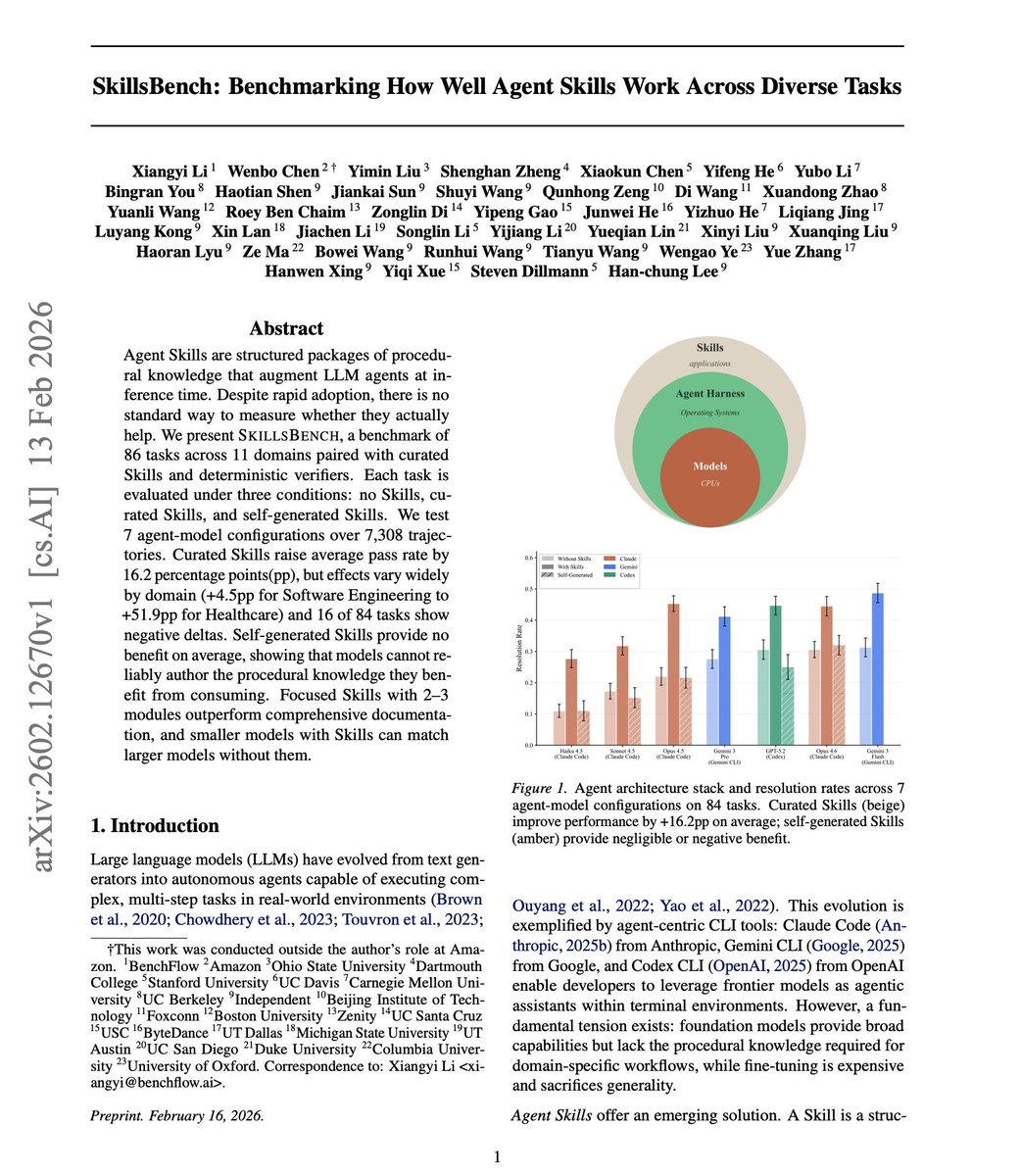
The new benchmark evaluates how well Skills help LLM agents across 86 tasks and 11 domains.
Finding over 7,300 agent trajectories:
Curated Skills improved agent pass rates by 16.2 percentage points on average. But the gains varied wildly, from +4.5pp in Software Engineering to +51.9pp in Healthcare.
The most surprising finding is that self-generated Skills provide no benefit on average.
Models struggle to create the procedural knowledge that actually helps them.
Focused, concise skills outperformed comprehensive documentation. And smaller models with Skills matched larger models without them.
If agents can't reliably create their own procedural knowledge, the curation and design of Skills becomes a critical bottleneck for agent systems.
Paper: https://t.co/ubXNB3UShQ
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
🚨BREAKING: Microsoft Research + Salesforce just dropped a paper that should scare every AI builder.
They tested 15 top LLMs GPT-4.1, Gemini 2.5 Pro, Claude 3.7 Sonnet, o3, DeepSeek R1, Llama 4 across 200,000+ simulated conversations.
Single-turn prompt: 90% performance.
Multi-turn conversation: 65% performance.
Same model. Same task. Just... talking normally.
The culprit isn't intelligence. Aptitude only dropped 15%.
Unreliability EXPLODED by 112%.
→ LLMs answer before you finish explaining (wrong assumptions get baked in permanently)
→ They fall in love with their first wrong answer and build on it
→ They forget the middle of your conversation entirely
→ Longer responses introduce more assumptions = more errors
Even reasoning models failed. o3 and DeepSeek R1 performed just as badly.
Extra thinking tokens did nothing.
Setting temperature to 0? Still broken.
The fix right now: give your AI everything upfront in one message instead of back-and-forth.
Every benchmark you've seen was tested on single-turn prompts in perfect lab conditions.
Real conversations break every model on the market and nobody's talking about it.
Introducing Simile.
Simulating human behavior is one of the most consequential and technically difficult problems of our time.
We raised $100M from Index, Hanabi, A* BCV, @karpathy@drfeifei@adamdangelo@rauchg@scottbelsky among others.