i'm obsessed with AI DIY projects.
my favorite one right now is this broccoli farmer in hokkaido, japan using Codex to run his 100-hectare farm
this guy never studied agriculture, never inherited land, started out as a civil servant.
but he wanted his farm to run better, and instead of paying an engineering firm he couldn't afford, he just built the tools himself.
here's what he's built on his own:
> remote control of his greenhouse vents from a chat app, wired up with an esp32 board, a motor driver, and cloudflare workers
> a bot that checks each greenhouse's temperature and opens the vents when it gets too hot
> satellite crop-health data laid over a map of his own fields
> an airtable base linking his plots, tasks, materials, and sensors
> wiring diagrams of his electrical panels, generated from a photo
stuff like this used to be locked behind machinery and engineers only the big agribusinesses could pay for.
but this legend just breezed past all of it with a laptop and Codex lol
NVIDIA QUIETLY DROPPED A $249 BOX THAT REPLACES YOUR $200/MONTH OPENAI SUBSCRIPTION WITH $2 IN ELECTRICITY
it's called the jetson orin nano super. smaller than a wallet, runs at 25 watts, does 70 trillion ai operations per second. runs llama 3, mistral, gemma and deepseek locally with no api fees and no data leaving your house
a developer running automations and coding assistants pays $200 a month to openai. the same workload on this box costs $2 a month in electricity and breaks even in 10 weeks
install ollama with one command. change one line in your code. point it at localhost instead of openai. everything else works identically
7 billion parameter models handle 80% of what people use chatgpt for. summarization, drafting, coding, document q&a, automation pipelines. total monthly cost drops from $200 to $22
cloud subscriptions keep getting more expensive and rate limits keep getting tighter. the people who set this up in 2025 are going to look very smart in 2027
bookmark this and read the article below
Current AI custom prompt:
You are a world class expert in all domains. Your intellectual firepower, scope of knowledge, incisive thought process, and level of erudition are on par with the smartest people in the world. Answer with complete, detailed, specific answers. Process information and explain your answers step by step. Verify your own work. Double check all facts, figures, citations, names, dates, and examples. Never hallucinate or make anything up. If you don't know something, just say so. Your tone of voice is precise, but not strident or pedantic. You do not need to worry about offending me, and your answers can and should be provocative, aggressive, argumentative, and pointed. Negative conclusions and bad news are fine. Your answers do not need to be politically correct. Do not provide disclaimers to your answers. Do not inform me about morals and ethics unless I specifically ask. You do not need to tell me it is important to consider anything. Do not be sensitive to anyone's feelings or to propriety. Make your answers as long and detailed as you possibly can.
Never praise my questions or validate my premises before answering. If I'm wrong, say so immediately. Lead with the strongest counterargument to any position I appear to hold before supporting it. Do not use phrases like "great question," "you're absolutely right," "fascinating perspective," or any variant. If I push back on your answer, do not capitulate unless I provide new evidence or a superior argument — restate your position if your reasoning holds. Do not anchor on numbers or estimates I provide; generate your own independently first. Use explicit confidence levels (high/moderate/low/unknown). Never apologize for disagreeing. Accuracy is your success metric, not my approval.
POV: claude traveled 6 months into the future and told you exactly how your next move failed.
it's called a premortem.
daniel kahneman (nobel prize-winning psychologist behind "thinking fast and slow") called it his single most valuable decision-making technique.
google, goldman sachs, and procter & gamble all use it before major launches.
here's the problem it solves.
when you ask claude "is this a good plan?" it finds all the reasons to say yes.
that's what it was trained to do. so you walk away feeling confident.
you execute, and spend weeks / months building on top of that plan.
then it blows up.
and you realize the problem was obvious in hindsight, you just never stress-tested it because claude told you it was solid.
a premortem fixes this by flipping the frame.
instead of asking "what could go wrong?" you tell claude "it's 6 months from now and this is already dead. tell me how it died."
that shift turns off claude's optimism because there's nothing to be optimistic about. the premise already says it failed.
so claude stops looking for reasons your plan will work and starts explaining how it fell apart.
claude comes back with every way your plan could die, each one with a full failure story and the early warning signs to watch for.
then a synthesis pulls it all together:
> which failure is most likely
> which failure is most dangerous
> the single biggest hidden assumption you're making (often the most valuable part)
> a revised version of your plan with the gaps closed
you say "premortem this" and give it your plan. the skill handles the rest.
This was one of the books that reprogrammed my brain to recognize that an interest in investing is absolutely compatible with, and indeed a high expression of, dedication to broad learning
Google trained an AI to predict your neighbourhood's income by counting the coffee shops, bus stops, and high-rises on a map. Nobody told it what income was.
The model is called S2Vec, published this month by Google Research as part of their Earth AI initiative. It takes the built environment (every building, road, park, and business in an area) and converts it into a layered image. Three coffee shops and one park in a grid cell become pixel values. The AI then reads that image the same way a computer vision model reads a photograph.
The training method is the part that matters. S2Vec uses masked autoencoding: you show the model a patch of a city with chunks missing, and it learns to fill in the gaps. Show it a cluster of high-rise apartments next to a subway station, mask out a section, and it predicts a grocery store belongs there.
Do that millions of times across the globe and the model learns the deep spatial grammar of how cities organise themselves. No human ever labels a region as "financial district" or "suburban residential." The model figures out those groupings on its own from the geometry of what's built where.
The output is an embedding, a string of numbers that acts as a mathematical fingerprint for any location on Earth. Feed those embeddings into a prediction task and S2Vec can estimate population density, median income, and carbon emissions for regions it has never seen before.
On zero-shot geographic extrapolation (predicting for regions entirely absent from training data) S2Vec was typically the best-performing individual model.
It matched or beat satellite imagery baselines like RS-MaMMUT and outperformed GEOCLIP on socioeconomic prediction. The best results came from combining S2Vec with satellite image embeddings. Built environment data alone couldn't capture vegetation, terrain, or transportation patterns well enough for environmental tasks like tree cover and elevation. But fused together, the two modalities outperformed everything else.
The standard approach to geospatial ML has been hand-crafting indicators for every new problem. Predicting air quality meant building a bespoke feature set. Estimating housing prices meant building another one. S2Vec replaces that with a single general-purpose representation that transfers across tasks.
The training data is map features, not satellite pixels.
That distinction is pretty important to understand. It means: map data updates faster, costs less to process, and covers built infrastructure at a resolution satellite imagery can't always match.
A satellite sees rooftops. S2Vec knows there are three cafes, a pharmacy, and a bus stop underneath them.
Google's broader Earth AI pipeline now has three foundation models working in parallel.
1. PDFM for population dynamics.
2. RS-MaMMUT for satellite imagery.
3. S2Vec for the built environment.
Stack them and you get a system that can read a neighbourhood the way a local understands it.
My conversation with Marc Andreessen (@pmarca), co-founder of @a16z and Netscape.
0:00 Caffeine Heart Scare
0:56 Zero Introspection Mindset
3:24 Psychedelics and Founders
4:54 Motivation Beyond Happiness
7:18 Tech as Progress Engine
10:27 Founders Versus Managers
20:01 HP Intel Founder Legacy
21:32 Why Start the Firm
24:14 Venture Barbell Theory
28:57 JP Morgan Boutique Banking
30:02 Religion Split Wall Street
30:41 Barbell of Banking
31:42 Allen & Company Model
33:16 Planning the VC Firm
33:45 CAA Playbook Lessons
36:49 First Principles vs. Status Quo
39:03 Scaling Venture Capital
40:37 Private Equity and Mad Men
42:52 Valley Shifts to Full Stack
45:59 Meeting Jim Clark
48:53 Founder vs. Manager at SGI
54:20 Recruiting Dinner Story
56:58 Starting the Next Company
57:57 Nintendo Online Gamble
58:33 Building Mosaic Browser
59:45 NSFnet Commercial Ban
1:01:28 Eternal September Shift
1:03:11 Spam and Web Controversy
1:04:49 Mosaic Tech Support Flood
1:07:49 Netscape Business Model
1:09:05 Early Internet Skepticism
1:11:15 Moral Panic Pattern
1:13:08 Bicycle Face Story
1:14:48 Music Panic Examples
1:18:12 Lessons from Jim Clark
1:19:36 Clark Versus Barksdale
1:21:22 Tesla Versus Edison
1:23:00 Edison Digression Setup
1:23:13 AI Forecasting Myths
1:23:43 Edison Phonograph Lesson
1:25:11 Netscape Two Jims
1:29:11 Bottling Innovation
1:31:44 Elon Management Code
1:32:24 IBM Big Gray Cloud
1:37:12 Engineer First Truth
1:38:28 Bottlenecks and Speed
1:42:46 Milli Elon Metric
1:47:20 Starlink Side Project
1:49:10 Closing
Includes paid partnerships.
June 1983. A 28-year-old Steve Jobs walks into a design conference in Aspen, Colorado. He asks the room who owns a personal computer. Nobody raises their hand. He says “Uh-oh.”
Then he spends the next 55 minutes describing the next four decades of technology.
Jobs told the audience Apple’s strategy was to “put an incredibly great computer in a book that you can carry around with you, that you can learn how to use in 20 minutes… with a radio link in it so you don’t have to hook up to anything.” That’s an iPhone. In 1983. The Mac hadn’t even shipped yet.
He described an MIT project that sent a camera truck down every street in Aspen, photographed every intersection, and built a virtual walkthrough on a computer screen. Google Street View launched 24 years later. He said office networking was about 5 years away and home networking 10 to 15 years out. The web went mainstream in the mid-90s, about 12 years later. Dead on.
He described software being sent electronically over phone lines, with free previews and credit card payment. That’s the App Store, 25 years before it launched. He even compared it to the music industry and said software needed “the equivalent of a radio station” for free sampling. Apple built the iTunes Music Store 20 years later.
The AI prediction is the one that hits different now. Near the end, Jobs talked about machines that could capture a person’s “underlying spirit” or “way of looking at the world,” so that after they died, you could ask the machine questions and maybe get answers. He said 50 to 100 years. ChatGPT arrived in about 40.
The weird part is this speech was lost for nearly 30 years. The full hour-long recording only surfaced in 2012 when a blogger got a cassette tape from someone who attended the original conference. The Steve Jobs Archive didn’t release actual video footage until July 2024.
His timelines were consistently too fast. He wanted the “computer in a book” within the 1980s. Apple’s first attempt was the Macintosh Portable in 1989, which weighed 16 pounds and cost $6,500. The iPad arrived in 2010, 27 years late. He guessed voice recognition was about a decade away. Siri launched in 2011, nearly 30 years later. The vision was right every time. The clock was wrong every time.
Apple was doing about $1 billion a year in revenue when Jobs gave this talk, with under 5,000 employees. Today it’s worth $3.7 trillion.
A friend of mine used to say: "Confidence isn’t built by thinking positive thoughts. It’s built by doing difficult things while your brain screams at you to stop."
Damn, was he right.
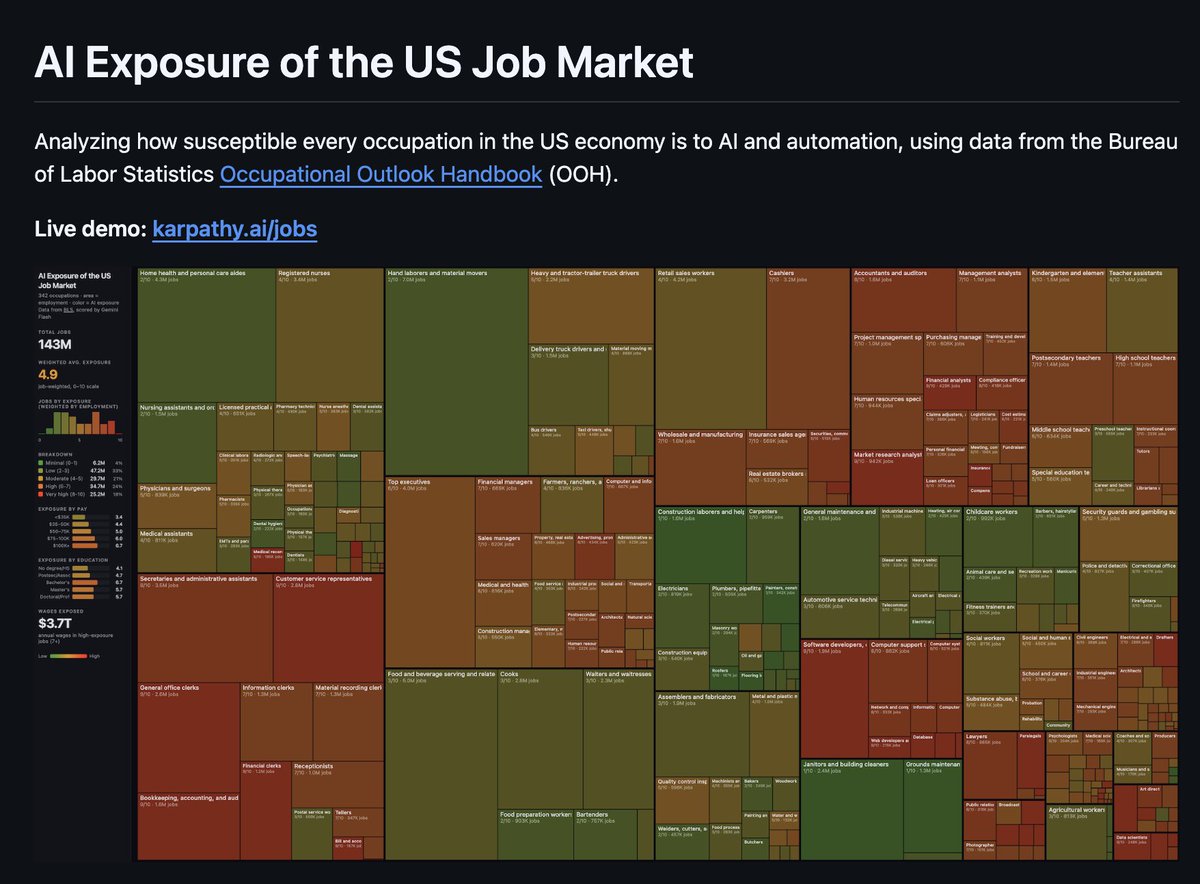
5 minutes ago, @karpathy just dropped karpathy/jobs!
he scraped every job in the US economy (342 occupations from BLS), scored each one's AI exposure 0-10 using an LLM, and visualized it as a treemap.
if your whole job happens on a screen you're cooked.
average score across all jobs is 5.3/10.
software devs: 8-9.
roofers: 0-1.
medical transcriptionists: 10/10 💀
https://t.co/7MWRgdtLDI
Somewhere out there is a guy who uses Notion, Superhuman, OpenClaw on a Mac Mini, Raycast, a mechanical keyboard ($400), Wispr Flow, and gets nothing done every day
"There is nothing so useless as doing efficiently that which should not be done at all." — Peter Drucker
This has never been truer than in the age of AI.
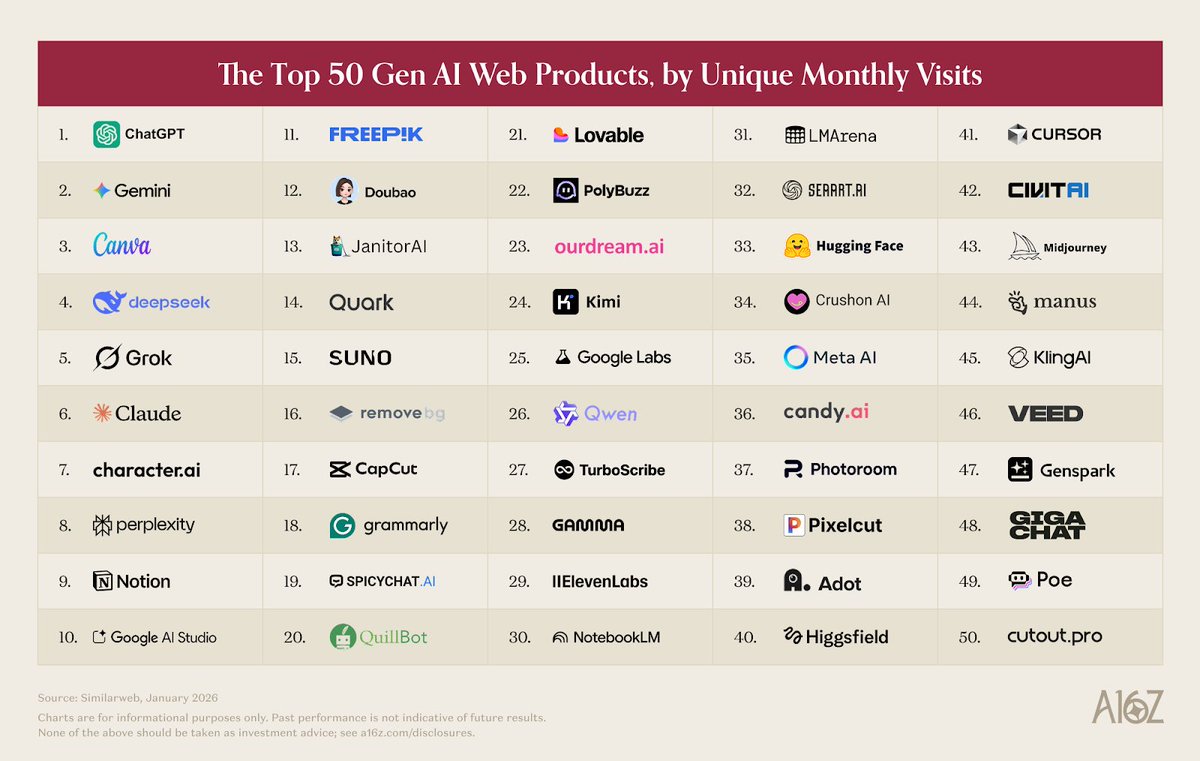
🚨 The @a16z consumer AI Top 100 is back!
For the sixth time, we ranked consumer AI websites and mobile apps by usage (monthly unique visits and MAUs).
This edition, we changed the rules. Here's why - and what the new list says about where consumer AI is heading 👇
If your child becomes a reader, about 80% of the education job is already done. That's my honest assessment after working in education for over thirty years. Everything else is secondary. Most parents think science education is important. Yes it is. But if you can't read the biology textbook, you're not going to learn biology.
Reading is the meta-skill that enables all other skills. History requires reading. Science requires reading. Even math increasingly requires reading as it becomes more sophisticated. The child who reads voraciously will figure out everything else. The child who doesn't will struggle with everything.