"Beyond autoregressive: why diffusion is the future of language models."
@StefanoErmon's keynote at @StartupGrind last week at the Fox Theatre.
Your AI product doesn't make one model call per session. It makes thousands. Most run quietly under the hood. The work that keeps the agent moving.
Using a frontier model for all of it means paying frontier pricing for work that doesn't need frontier intelligence.
Mercury 2 is built for that work: >1,000 tokens/sec on standard GPUs, comparable quality to frontier speed-optimized models for a fraction of the cost.
The question isn't which model is smartest. It's which model is most efficient, on the highest-volume tasks.
@adityagrover_@volokuleshov
In 2014, generative models were a niche people didn't think would work.
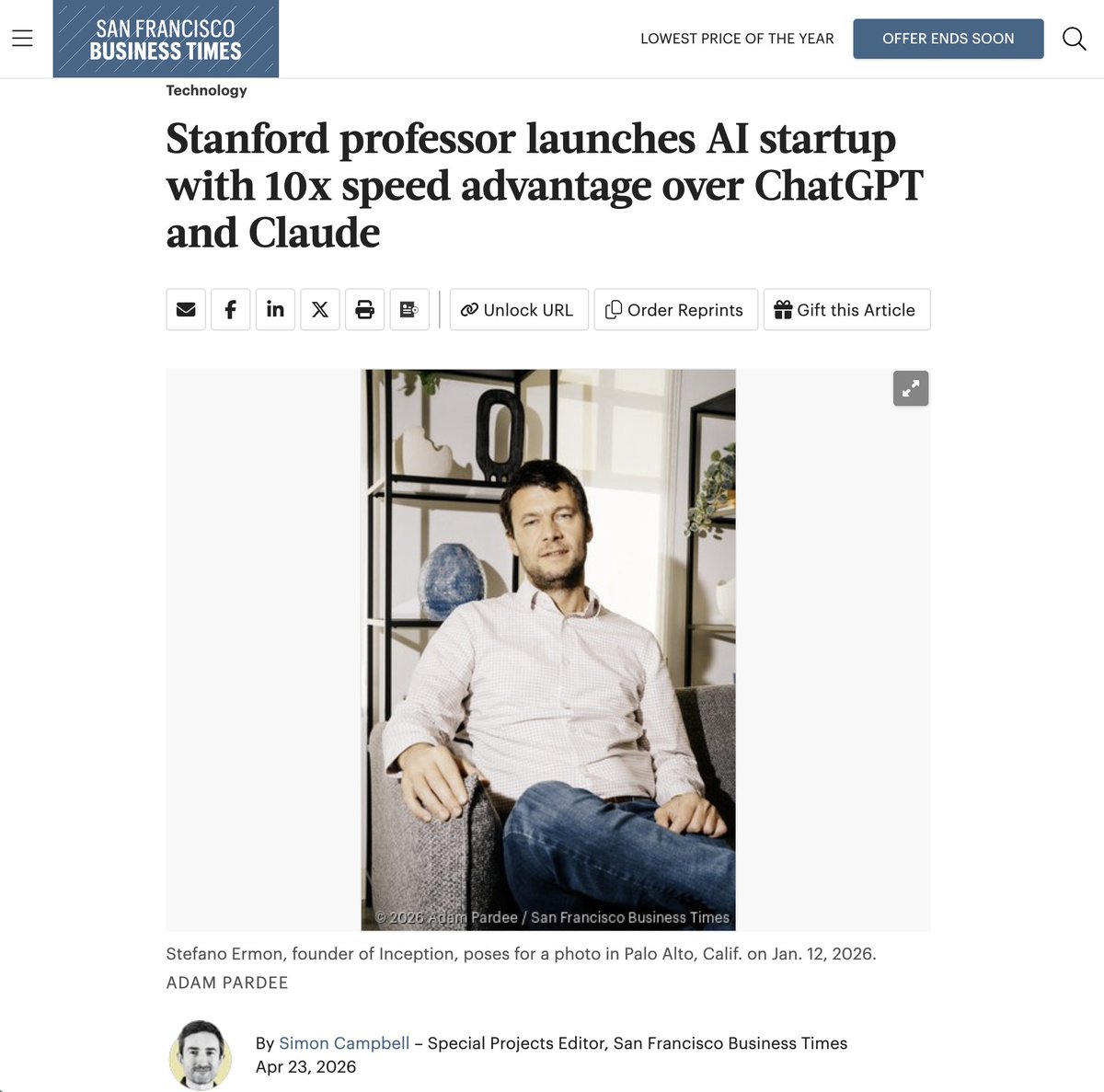
@StefanoErmon kept betting on them anyway. His group at Stanford went on to co-invent diffusion, the technique behind Sora and Midjourney. Then he made the bet that the same approach could work for text and code, and brought in @adityagrover_ and @volokuleshov to start the company.
The full arc, by @Si_Campbell_ in @SFBusinessTimes:
https://t.co/mWfarfSlkU
Can a large foundation video model run as a real-time robot policy at the edge, on a single RTX 5090?
• ✅ No quantization
• ✅ No distillation
• ✅ Full denoising (all the way from noise to clean video)
We just proved it's possible. 👇🎬
Q2 BOOMIN at @VSCPR@genspark_ai — Forbes’ 2026 AI 50
@AutoStoresystem — Warehouse automation is table stakes. (Fast Company)
@krane — AI agents that help build data centers faster. (Business Insider)
Fruitist X @CALEBcsw (Front Office Sports)
@ForesiteCapital — Sleep becomes the next frontier beyond obesity. (Bloomberg)
Jimini Health — AI-Chatbots with Clinician in Loop.
@conveyAI — Digital Teamates You Can Actually Trust for the Gruntwork
First Sid by Sid clip just dropped.
One founding engineer. One GTM guy. No script.
Text compaction, summarization, and voice are the use cases where Mercury keeps winning. Baseline quality, 3-5x faster, fraction of the cost.
Every customer keeps saying the same three words: speed, quality, cost. @justkharbanda@phylera14
In 2014, DoorDash ran on a guy named Steve.
Every dasher shared their location with him on Find My Friends. Order comes in, Steve finds the closest one, texts them. It worked until it didn't.
We sat next to him and turned that manual process into software. Steve went on to build and lead our support org.
I've spent the last year watching the same pattern play out across every industry. Smart people manually holding critical workflows together because their systems haven't kept up. AI helps, but mostly as an assistant - it makes you faster, it doesn't take work off your plate.
That's what we’re building at @conveyAI. Digital teammates that operators train themselves, that run autonomously, and that fully own a process end to end.
Today we're out of stealth.
Grateful to NBC Universal, Samsara, Faire, TelevisaUnivision, Unity and our other customers who bet on us early.
The era of asking your best people to manually run critical business processes is over. The future belongs to the 100x operator.
🧵 We launched Latitude (@rtp) last week. Lots covered, so I want to double-click on Global Fiat Payouts.
Fund us in USD. Pay anyone in 50+ countries in local currency. Under 2 minutes on average.
It runs on stablecoin rails, but you don't need to think about that any more than you think about the protocol behind email when you hit send.
The research journey to create diffusion LLMs has been 10+ years in the making. My cofounders and I have been at the forefront of this work, from score-based generative modeling to SEDD to Mercury 2. @amplifypartners put together an excellent deep dive:
https://t.co/fc0nAsDKKw
Hello World!
Latitude is live.
We built stablecoin-to-local-fiat infrastructure across 50+ countries so businesses can move money globally at a flat 0.5% rate, with no hidden spreads or volume commitments.
Global payments are broken. We're fixing the rails.
$8M seed led by NEA. Team from Uber, Coinbase, Stripe, and more.
Full story in Fortune (in comments)
Over a decade ago at Uber, we were paying drivers across 40 countries. Their top ask: "Pay me faster." That stuck with me through Coinbase and Stripe, where I kept running into the same wall from different angles.
Today, Latitude (@rtp) is launching out of stealth. We raised an $8M seed round in Jan 2025 and have been building quietly since then.
@timt recently sat down with @_inception_ai's founders to tell the full story — from Stanford to building the first commercial diffusion LLM.
Watch the conversation here: https://t.co/UmMmT3HxaE
What if language models didn't have to generate one token at a time?
Our CEO @StefanoErmon joined @TBPN to break down how Mercury 2's diffusion LLM hits 1,000+ tok/s on standard NVIDIA GPUs — and why speed changes the product for coding, voice agents, and search.
Everyone's talking about AI taking jobs.
How about AI that's actually helping people do their jobs more safely and successfully?
Meet Multitude Insights.
We met Matthew White and Akihiko Izu several years ago as they were building something different — a platform that helps police officers connect the dots between crimes and solve cases faster. This is exactly the kind of AI we believe in at VSC Ventures: not flashy, not hype-driven, but deeply practical technology making a real difference in the field.
@JayKapoorNYC, Maggie Philbin, and I have worked hand in hand with Matt and Aki ever since — helping them sharpen their positioning and build awareness. That collaboration led to national media attention, earning coverage in the Wall Street Journal and Boston Globe, because stories like this deserve to be told.
Today, we're excited that the company has raised its Series A and welcome @JasonrShuman to the 'ride-along' with existing investors Commonweal Ventures and Counterview Capital.
This is what "Dirty Jobs AI" looks like — AI applied to the essential, unglamorous, and critically important work that keeps communities safe. It's not always the sexiest investment thesis, but it's the one we keep coming back to because it just makes sense.
Another day, another case closed:)
Reasoning AI just got 5x faster. @_inception_ai launched Mercury 2, the first reasoning dLLM. Built on diffusion, it refines in parallel instead of one token at a time.
Production-ready for agents, voice, and code. @dinabass has more in @business : https://t.co/C6BJsGshqe
Mercury 2 is now live! 🚀
The fastest reasoning LLM built for production speed.
~1000 tokens/sec vs <200 tokens/sec for comparable models.
What this enables:
�� Fast agents: fast iteration loops, no compounding delays
🎙️ Voice and Search AI: tight turn-taking, natural conversations under strict latency budgets
💻 Interactive code completions, editing, and design workflows
Mercury 2 is live 🚀🚀
The world’s first reasoning diffusion LLM, delivering 5x faster performance than leading speed-optimized LLMs.
Watching the team turn years of research into a real product never gets old, and I’m incredibly proud of what we’ve built.
We’re just getting started on what diffusion can do for language.