Glad to see the renaissance/revival of sparse structures brought by AI bigheads, from Anthropic to OpenAI! Instead of training extra AEs and manually interpreting AE features, our latest paper decomposes the activations along concept vectors that have semantic meanings by design via classic compressed sensing.
Not only is the decomposition fast, but it also reveals the extent of concepts in each activation, allowing for effectively steering LLMs’ behavior. SOTA performance on detoxification and other alignment tasks.
Paper: https://t.co/JzvVYTsswn
TLDR/Code/Dataset: https://t.co/lZDvqvUkCa
We're sharing progress toward understanding the neural activity of language models. We improved methods for training sparse autoencoders at scale, disentangling GPT-4’s internal representations into 16 million features—which often appear to correspond to understandable concepts.
https://t.co/tTRPztmra1
In the 1940s, von Neumann brought order to computer architecture.
in the 1970s, Codd brought order to database management.
In the 2020s, who will bring order to AI?
The laptop hasn't changed in 30 years. NVIDIA just changed it
RTX Spark is their first PC chip ever.
- RTX 5070 level GPU
- 128GB unified memory
- 1 petaflop of local AI
- thin, light, barely throttles unplugged
Your AI agent lives on the machine. 24/7. No cloud.
This is step one of the agentic AI PC, and everyone else is about to copy it.
Pre-AI, mathematicians sit on a problem, go with a few intuitions, hit walls, and if lucky they make the proof. The explanation is a result of the whole process and gives faithful insights. If AI does the proof and mathematicians only explain the proof, does the explanation still contain insights?
3/ Math journal review cycles can famously take years. Why so fast now?
Every proof is generated in machine-verified Lean, then paired with a human exposition. The mathematician authors are there to explain the theorem, not to prove it.
AxiomProver produces math one can trust.
Those are orthogonal concepts.
- World models trained on highly diverse data become foundation models: their encoders can be used for a wide variety of downstream tasks.
- "World" refers to two things: (1) predicting the evolution of a complex system or environment, (2) predicting the evolution of a system under control and its effect on the environment (action-conditioned world model) which is a necessary component of planning.
I spent a year of my PhD stuck on a 2002 problem of Schechtman. GPT 5.5-Pro helped me finish: vector balancing for zonotopes (shadows of a cube)!
For any zonotope Z ⊂ ℝᵈ, v₁,...,vₙ ∈ Z, there are signs x₁,...,xₙ ∈ {-1, 1} with x₁v₁+...+xₙvₙ ∈ O(√d) Z, sharp. [1/4]
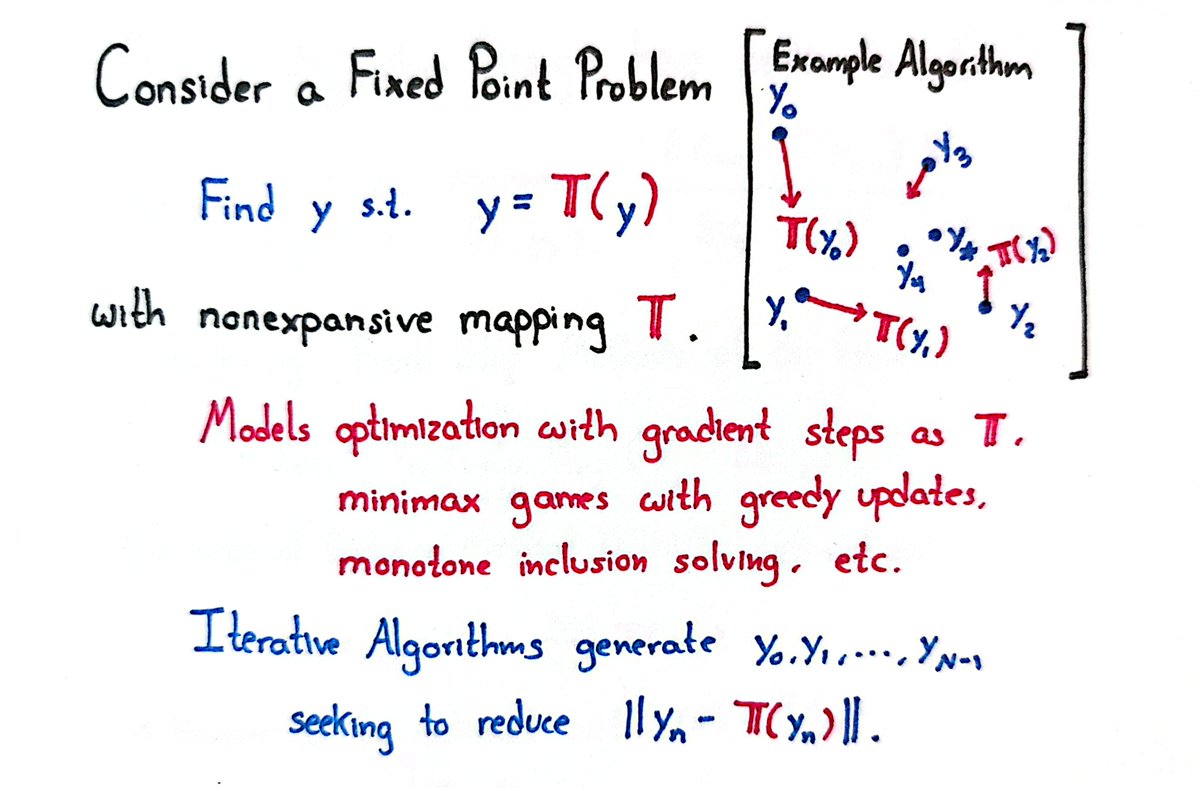
I'm excited to share some joint work done with @TaeHo_Y00N.
We considered algorithm design for fixed-point problems.
This area models gradient descent, minimax optimization, and more.
Below I give the wild ride of this paper.
Mathematically, it is gorgeous.
A fun experiment comparing a random step with one gradient step:
With a small CNN on CIFAR-10, a random step is basically a disaster. (A gradient step is a ~185σ event.)
That makes sense if you expect a random direction in R^d to be ~sqrt(d) standard deviations worse than the optimal one. So scaling up to a larger model should make things even worse.
But with a 7B model (test on GSM8k), random steps have a good chance of outperforming a gradient step.
(The gradient norm of one PPO update is 1.94, while the L2 norm of the Gaussian perturbation is 85.6. The figure below rescales the Gaussian perturbation to match the PPO update norm, so the random step and gradient step have the same radius.)
We should really rethink the parameter-function map.
There's a lot of controversy brewing around arXiv's decision to penalize authors who post unchecked AI generated content.
The impulse is correct, IMO, simply on grounds of efficiency: it is much cheaper to insist the authors vet their work first, rather than distributing the cost of that work to EVERY reader/agent who subsequently downloads the work.
I believe the mechanism is likely the wrong one, however. Unfortunately, suggestions to use github are even worse, IMO, because they lose the (effective) immutability of the scientific record, which arXiv upholds.
This is so sad. 😞
You have at reach an omniscient personalised teacher and you end up delegating your work to it rather than growing from having its support.
Like looking at the solution keys before doing maths exercises.
What is the point? 🥺
A mathematician who shared an office with Claude Shannon at Bell Labs gave one lecture in 1986 that explains why some people win Nobel Prizes and other equally smart people spend their whole lives doing forgettable work.
His name was Richard Hamming. He won the Turing Award. He invented error-correcting codes that made modern computing possible. And he spent 30 years at Bell Labs sitting in a cafeteria at lunch watching which scientists became legendary and which ones faded into nothing.
In March 1986, he walked into a Bellcore auditorium in front of 200 researchers and told them exactly what he had seen.
Here's the framework that has been quoted by every serious scientist for the last 40 years.
His opening line landed like a punch. He said most scientists he worked with at Bell Labs were just as smart as the Nobel Prize winners. Just as hardworking. Just as credentialed. And yet at the end of a 40-year career, one group had changed entire fields and the other group was forgotten by the time they retired.
He wanted to know what the difference actually was. And he said it wasn't luck. It wasn't IQ. It was a specific set of habits that almost nobody is willing to follow.
The first habit was the one that hurts the most to hear. He said most scientists deliberately avoid the most important problem in their field because the odds of failure are too high. They pick a safe adjacent problem, solve it cleanly, publish it, and move on. And because they never swing at the hard problem, they never hit it. He said if you do not work on an important problem, it is unlikely you will do important work. That is not a motivational line. That is a logical one.
The second habit was about doors. Literal doors. He noticed that the scientists at Bell Labs who kept their office doors closed got more done in the short term because they had no interruptions. But the scientists who kept their doors open got more done over a career. The open-door scientists were interrupted constantly. They also absorbed every new idea passing through the hallway. Ten years in, they were working on problems the closed-door scientists did not even know existed.
The third habit was inversion. When Bell Labs refused to give him the team of programmers he wanted, Hamming sat with the rejection for weeks. Then he flipped the question. Instead of asking for programmers to write the programs, he asked why machines could not write the programs themselves. That single inversion pushed him into the frontier of computer science. He said the pattern repeats everywhere. What looks like a defect, if you flip it correctly, becomes the exact thing that pushes you ahead of everyone else.
The fourth habit was the one that hit me the hardest. He said knowledge and productivity compound like interest. Someone who works 10 percent harder than you does not produce 10 percent more over a career. They produce twice as much. The gap doesn't add. It multiplies. And it compounds silently for years before anyone notices.
He finished the lecture with a line I have never been able to shake.
He said Pasteur's famous quote is right. Luck favors the prepared mind. But he meant it literally. You don't hope for luck. You engineer the conditions where luck can land on you. Open doors. Important problems. Inverted questions. Compounded hours. Those are not traits. Those are choices you make every single day.
The transcript has been sitting on the University of Virginia's computer science website for almost 30 years. The video is free on YouTube. Stripe Press reprinted the full lectures as a book in 2020 and Bret Victor wrote the foreword.
Hamming died in 1998. He gave his final lecture a few weeks before. He was 82.
The lecture that explains why some careers become legendary and others disappear is still free. Most people who could benefit from it will never open it.
Tomorrow, I start a new full-time position as VP Digital Human Research at Epic Games. (And no, this isn’t an April Fools’ joke.)
Today, I’m taking early retirement from Max Planck and will become an Emeritus Director.
As an Emeritus Director, I will continue to supervise my remaining students, oversee ongoing projects, and wind down my department over the next couple of years, which is a normal process when a director retires.
Being a Max Planck director is the best academic job in the world and it has been my great honor to co-found and help build the Max Planck Institute for Intelligent Systems. I love the institute deeply.
But my statutory retirement age was looming and I’m not done yet. I’ve been working on capturing and modeling human movement for 30 years and it has gone from a fringe topic to something that works robustly and has immense potential.
With AI today, scale matters, and achieving that scale increasingly requires industry. In particular, digital humans are moving from research prototypes to foundational technology across industries. At this point in my career, I want to get this technology into the hands of millions of users, while pushing the frontier of digital humans.
I know that this is a challenging time for the games industry. Such times are precisely when people get creative, the industry is open to change, and real innovation can take root.
Epic Games is the ideal place for this. The talent is deep, there is a compelling vision for how games will evolve, and the commitment is clear. I’m excited to join them and the rest of the Meshcapade team.
There is no good way to express on social media the depth of my gratitude to the Max Planck Society, my co-directors, students, post docs, and staff. It has been an amazing 15-year journey because of you. Thank you.
Christian Rupprecht explains their interpretability research in 3D computer vision, testing if (and where in the model) multi-view transformers like VGGT, DepthAnything 3, and DUSt3R use point/patch correspondences to make sense of 3D scene geometry.
@Chiuchiyin Met a group of Turkish and German tourists in Heidelberg. They said good German food is non-existent 🤣 idk i like the knuckles and sausages
@JocelynnPearl@EdisonSci The $200/mo subscription is free for academia, hospitals, and other non-profits. Your institution might not be on the list for some reason, will shoot you a dm and we can sort it out.





























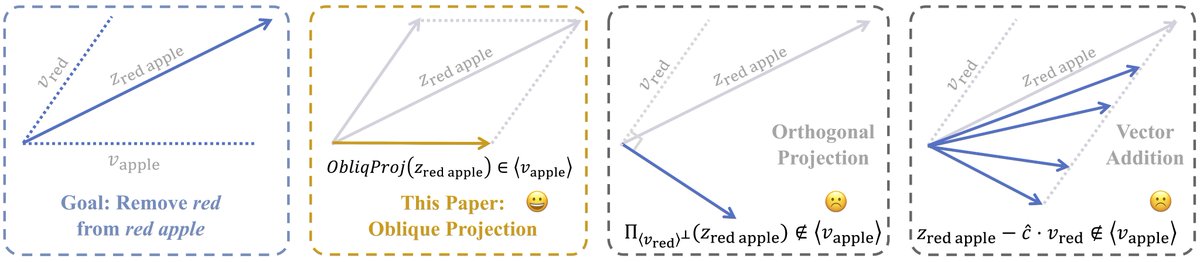




![vetohaze's tweet photo. I spent a year of my PhD stuck on a 2002 problem of Schechtman. GPT 5.5-Pro helped me finish: vector balancing for zonotopes (shadows of a cube)!
For any zonotope Z ⊂ ℝᵈ, v₁,...,vₙ ∈ Z, there are signs x₁,...,xₙ ∈ {-1, 1} with x₁v₁+...+xₙvₙ ∈ O(√d) Z, sharp. [1/4] https://t.co/txvfc8gwv7](https://pbs.twimg.com/media/HJQdqLRbAAAZUlo.jpg)