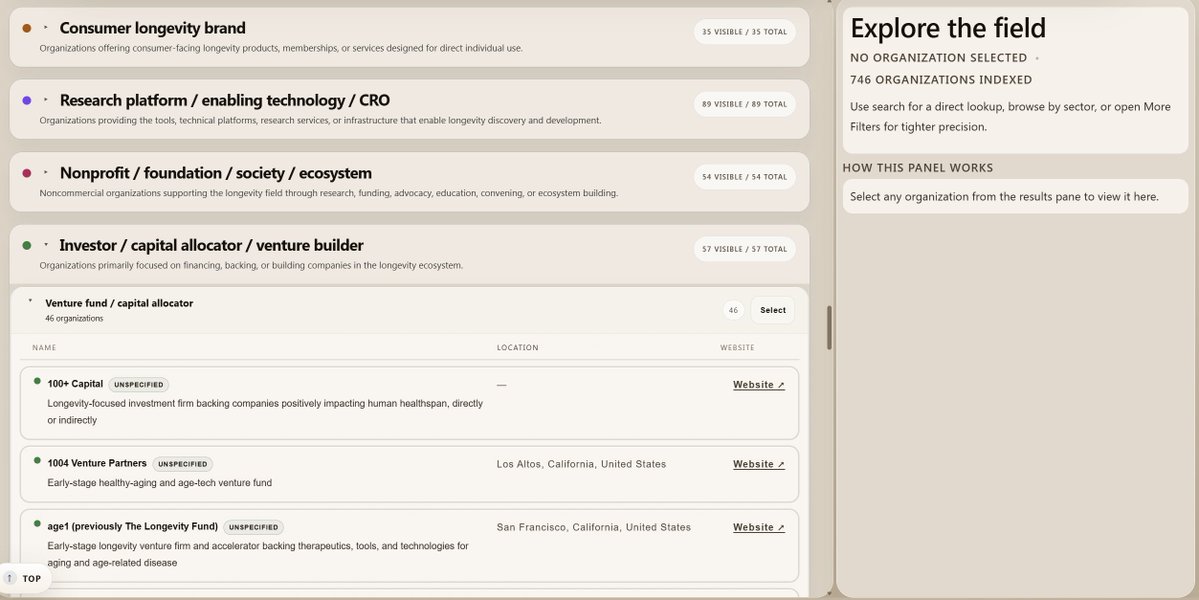
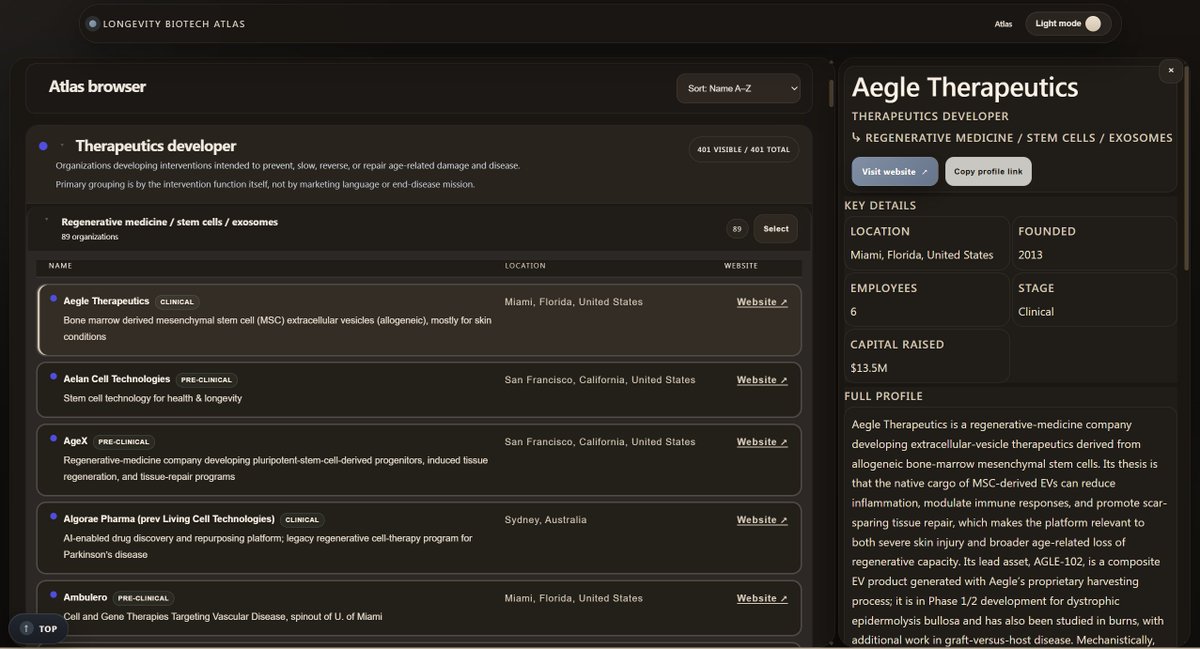
I’m excited to launch the Longevity Biotech Atlas, a personal project mapping 700+ organizations across the aging and longevity ecosystem.
Longevity biotech is moving fast.
A lot of the public narrative has centered on GLP-1s, peptides, biohacking, and consumer health optimization. But beneath that, a much deeper ecosystem is forming: companies, labs, investors, and non-profits working on core technologies that will enable fundamentally new forms of measurement and rejuvenation.
The field is growing quickly, but it is still hard to answer basic questions:
Who is building what?
Which areas are crowded?
Which technologies are underexplored?
Where should founders, scientists, investors, and operators be paying attention?
To help make the space easier to navigate, I synthesized public information on 700+ organizations—ranging from therapeutics developers, diagnostics, investors, and more— into a single database.
You can explore the atlas at the link in the comments.
This is still an early version, and I’ll be adding more over time: new organizations, personal accounts, bookmarks, and better ways to track how the field is evolving. My hope is to build this out into a core tool for people trying to understand, build, fund, or work in longevity.
If you’re interested in aging biology, biotech, investing, company formation, or the future of medicine, follow along. I’ll be sharing updates, maps of different subfields, and analyses of where the biggest opportunities and gaps may be. Let me know what you find useful!
🧵 Elon: “Longevity is an extremely solvable problem”
At Vitalist Bay (May 14 - May 17), we’re solving it!
1K+ pioneers, 100+ speakers, 50+ workshops, 40+ activities, 5 critical health tests
Join us to spark dozens of SpaceXs for longevity!
Big takeaway from looking through all the events: longevity, AI, and women's health are hot🔥. ARPA-H, the US govt's new $1.5bil/year granting agency, is on the ground at JPM looking for innovators shaping biotech's future. Lots of exciting events, see you all there! --Aevitas
That's right folks! It's JPM week, SF's biggest biotech event of the year. Here's our guide to some of the top events of the week (that you can still get into) 🧵
Fahy’s work seems to restore the structure of the thymus itself, while Friedrich’s showed increased common lymphoid progenitor proliferation and recruitment to the thymus.
What happens if you combine the TRIIM trial intervention with the recent DFI treatment Feng Zhang published? Both boosted different aspects of adaptive immune development and maintenance. The next step is clearly to put the two together!
One year down, and what a journey its been! @AevitasHouse has been an incredible community of researchers and builders solving urgent challenges in human health. For 2026, we're expanding our support of projects in aging, bioengineering, and systems biology. Especially if you're early stage or new to SF, we'll help you find the right people and supporters for your project. If you've been looking for a hardcore, technical biotech community to call home, apply for our 2026 cohort!
🔥Announcing Aevitas 2026! 🔥
We had a phenomenal 2025, with companies ranging from brain tissue repair, large-scale biomarker analysis, stem cell manufacturing, and so much more!
Are you a researcher, founder, or biotech builder? We have a home for you! Apply to join below 👇
AI x Longevity Pitch Workshop next week! Join NIMBLE and Aevitas for a showcase of cutting edge biotech companies followed by an Oxford style debate on the future of aging research, hosted at @FenwickWest. How will AI reshape the frontier of anti-aging biotech? Sign up below 👇
What do you think can be done to get more people to study aging btw 20-40 @MaxUnfried? It seems like the highest impact time to intervene; you still have most of your functional biology without long-term degeneration. Not to mention some studies report way more age associated changes occuring btw 20-40 than btw 40-70 (see fig 3c here) https://t.co/uE36BPWma2
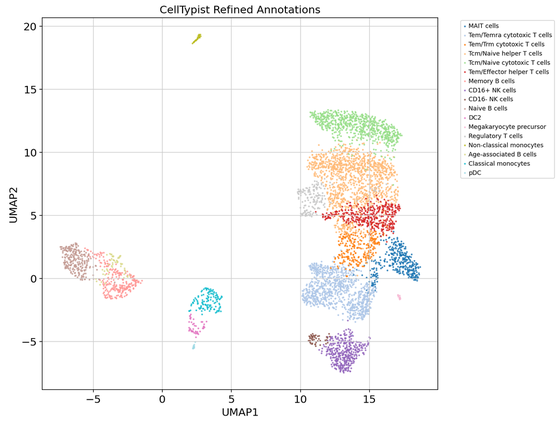
You can see some of our analysis below! Current clinical tools struggle to identify patient-specific drivers of disease. The same chronic condition can have different biological causes across individuals. But if you have a healthy baseline of your biology, you can compare your before and after results to identify what's going wrong if you get sick. That's what motivated me to get my PMBCs sequenced, the first of several datapoints in my model of homeostasis. Really enjoyed highlighting the power of these research tools!
🔍 IMMUNE STATUS ASSESSMENT:
• STEADY-STATE IMMUNITY: Low inflammatory cytokine expression suggests
healthy, non-activated immune status
• ACTIVE SURVEILLANCE: High chemokine expression indicates ongoing
immune patrol and tissue surveillance
• MEMORY RESPONSES: Strong antibody production suggests established
immunological memory
• CYTOTOXIC READINESS: NK and T cell activation markers indicate
prepared anti-viral/anti-tumor responses
• Robust memory T cell trafficking (RANTES dominance)
T CELL COMPARTMENT ANALYSIS: • Balanced CD4+/CD8+ T cell ratio (0.86:1) indicates healthy immune status • High proportion of memory T cells suggests prior antigen exposure • MAIT cells (6.5%) - important for mucosal immunity and pathogen response • Regulatory T cells (3.0%) - normal proportion for immune homeostasis
B CELL MATURATION STATUS: • Balanced memory:naive B cell ratio (1.07:1) indicates active immune responses • Age-associated B cells present but low (1.0%) - normal for healthy adults • No detectable plasma cells suggests no active inflammatory response
INNATE IMMUNE LANDSCAPE: • NK cells show CD16+ dominance (8.8:1 ratio) - typical cytotoxic profile • Classical monocytes predominate (4.85:1) - normal circulating pattern • Low DC2 and pDC populations consistent with steady-state conditions
OVERALL IMMUNE PROFILE: • T cell dominance (76.9%) typical of healthy PBMCs • No signs of immune activation or inflammatory states • Diverse immune cell repertoire with all major populations represented • Quality metrics suggest high-quality sample with minimal technical artifacts
Great conversation at our Tech Week event with @imyoohealth and @kepler_ai_ on combining AI with advanced biomonitoring to create robust pictures of health and disease. If you want to learn more, keep an eye out for our next monthly meetup on these topics!
I’ll be analyzing my own blood proteomics and single cell RNA data! A lot of these tools are available to researchers but haven’t made it to the clinic. We’re working on bridging that gap and unlocking new dimensions of personalized healthcare.
This Tuesday: We're co-hosting a special event on the Frontiers of Personalized Biomarkers as part of @a16z's @Techweek_. With @imyoohealth and @kepler_ai_, we'll demonstrate how multi-omics and AI can reshape healthcare and the future of data-driven bioenhancement. Info below
biologists continue to mistake single-cell technical sampling noise for meaningful cellular heterogeneity. the apparent sparsity of single-cell data is due largely to technical artifacts like transcript capture and sequencing depth--if there are hundreds of thousands of transcripts per cell but you sequence only 5-10k unique molecules, of course you get mostly zeroes in any given cell. pseudo-bulking makes this clear: when you aggregate these noisy single cell samples, the vast majority of the genome shows expression greater than zero
this is because the entire genome is being pervasively (yet stochastically) transcribed across nearly all cell types, including terminally differentiated cells (with a few obvious exceptions, e.g. enucleated red blood cells, spermatozoa, etc). hence you should expect to find at least one copy of nearly every transcript if you sample a single cell deeply enough over time
it is the *relative* or *ranked* differences in expression compared to this low-level baseline that dictate cellular identity and function
yet this pervasive transcription extends to retrotransposons, heterochromatin, and other supposedly "silenced" regions of the genome--all of which are systematically discarded in most standard processing pipelines. stare at the raw .fastq for long enough and this becomes obvious
thus, this pervasive genome-wide transcription has implications not only for how we train virtual cell models on single-cell RNA count data, but for our understanding of cellular biology as a whole: to truly plumb the depths of the cell, we must venture beyond the reference genome into transcriptional terra incognita, where we will encounter eldritch species of non-coding RNAs that may throw into question much of what we know about the biology of the cell
Love this screenshot - formal, rational systems are great because they are very precise - but their fundamental incompleteness pushes us into the irrational wilderness if we want to find truth & bring it back inside