@crystalxtang Happy to be in the conversation! Runloop sandboxes can lean even more stateful persistent snapshots and un-capped runtime. Great place to run your agents 😉
So excited to work with @trajectorylabs as a sandbox partner. They're bringing new ideas and flawless execution to the Continual Learning space and we can't wait to watch them go 🚀
Today, @MichaelElabd, @QuantumArjun, and I are excited to announce Trajectory.
We are a research lab and product company building the platform for Continual Learning.
Our platform unlocks the signal already sitting in product usage, so companies can continuously post-train large-scale agentic models that outperform the frontier. @trajectorylabs
We’ve raised $15M from @Conviction, @BessemerVP, @radicalvcfund, @jeffdean, @drfeifei and more.
We’re partnering with some of the best AI-native companies: @ClayRunHQ@Harvey, @DecagonAI, @mercor_ai, @RogoAI to power their agentic systems, some of which we are already in production with.
We’ve brought together a world class research team from DeepMind, OpenAI, Apple, Meta Superintelligence, Amazon AGI, Scale AI, and an elite product team from Stripe and Figma.
AI will never again start on day one. Every correction, every retry, every edit will make products smarter. This is Continual Learning.
Watched Runloop spin up a full dev environment in a minute, live on stage at Stripe Sessions.
Proud to be a launch partner for Stripe Projects, and even prouder of the team that made it real.
https://t.co/yHvs1Hmgkf
Runloop is excited to be a launch partner for the @stripe Projects developer preview 🚀
One command provisions a full Runloop account with devboxes ready for agents, full access to pro plan features, and real credentials in your environment. No dashboard and no copy-paste keys 🙅
Simply run:
$ stripe projects init my-app && stripe projects add runloop
Try it today: https://t.co/o1yNF6c1qU
Demo: https://t.co/RNNYvHmY4x
Introducing Axons: our new distributed event stream for running agents at scale. If you’re building long-lived, multi-client agent workflows, this is for you. Axons make agentic workflows durable, auditable, secure and cost-efficient: https://t.co/2G0Ge51tzV
So sorry this happened to you.
Models can't police themselves. The guardrail was a paragraph of text. That's not a guardrail.
Security has to live at the infra layer. Container inside a micro VM, network policies, scoped tokens, tool restrictions. We built a credential gateway so a domain-management token cannot touch volumeDelete because that permission doesn't exist at the API layer. You decide exactly which tools an agent can call.
When you're free, we'd love to help prevent this in the future. DM us.
Shipping AI agents you can trust in production just got dramatically easier. Agents making autonomous decisions across real workflows need constant validation but running benchmarks used to take days, required constant oversight, and gave teams no structured way to compare results.
With Runloop's Benchmark Job Orchestration + Weights & Biases integration, thousands of parallel environments run in hours, not days, without tending, and give full trace-level visibility into every action and agent turn
Find out more in our docs 👇
Agent capability without control is a liability.
Runloop's own Abigail breaks down the control architecture that lets you deploy agents that are powerful and safe without trading one for the other.
https://t.co/XAS3qtVxL5
@wandb@weave_wb Runloop handles the execution layer. Weave handles the observability and analysis layer. Together they turn one-off benchmark scripts into a continuous evaluation workflow.
Full report: https://t.co/ZVxeC8qik0
Runloop now integrates with @wandb Weave for orchestrated agent benchmarks with full traceability.
Runloop runs thousands of agent tasks in parallel. @weave_wb turns the traces into something you can inspect and compare.
Joint report: https://t.co/ZVxeC8qik0
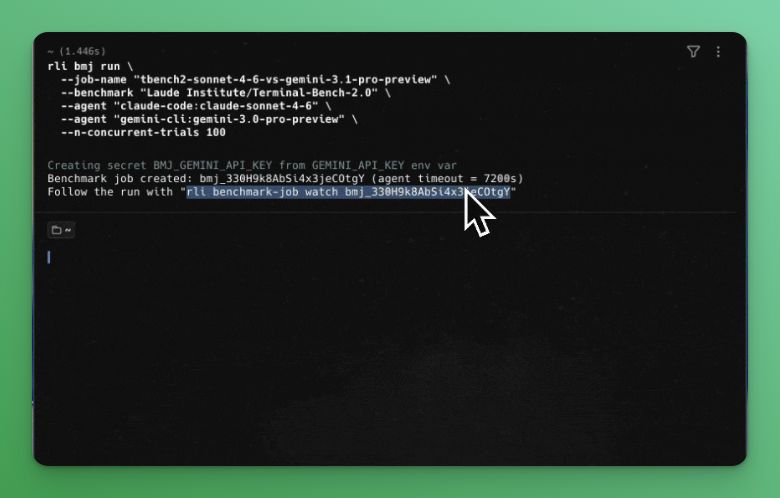
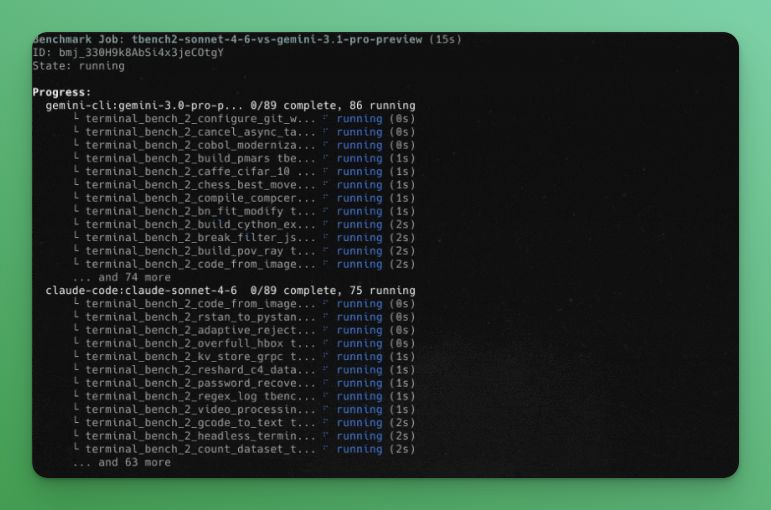
@wandb@weave_wb The demo in the joint report: Terminal-Bench 2, OpenCode as the agent harness, Gemini 3 Pro vs Claude Sonnet 4.6, 100 concurrent devboxes, full trace export to Weave, side-by-side comparison in one view.
You ever run a benchmark and end up with 40 log files, zero clarity, and a laptop that sounds like a jet engine?
@runloopai + W&B Weave fixes this 🧵