Renoir in Clair Obscur - @MuseeOrsay Thursday, June 25, 7–10 p.m.
On June 25, the Musée d'Orsay is opening its doors to the world of Clair Obscur: Expedition 33, with references to the Belle Époque themes and the couple formed by Auguste Renoir and Aline Charigot.
You can expect to see a roundtable discussion with the game's artists, the game's original soundtrack performed live under the museum's nave, and an exclusive exhibition highlighting parallels between images from Clair Obscur: Expedition 33 and the Musée d'Orsay's collections.
Tickets will go live on June 9th at 11am CEST More information: https://t.co/UbUio1HVY5
During my time working on Hytale in 2016-2019, it was maybe to the absolute maximum 2 years away from a PC release with the legacy engine and vision. I still have videos, screenshots and old client builds to attest to that. All developers from that time that I've talked to say the same.
I don't know exactly what happened in the past few years, I have not seen the game since 2019. The team back then was locked in and cracked beyond anything. The momentum was insane, we were in a stage where ton gameplay elements were getting introduced every single week and the game was shaping up fast towards release. There are already dozens of stories like this from former devs coming out in the past few days. and we didn't need to release in a "perfect state", in my opinion.
I was burning maybe 350k to 400k a month on Hytale development - somewhat sustainable - but that was before Hypixel Skyblock and the server was on a decline so I needed funding soon to keep going at such pace. Maybe that sense of limited funds urgency was a good thing looking back on it. However, it was stressful to say the least!
Then I think the pressure of having the Riot Games label + mega viral trailer, bigger funding and higher expectations made us all doubt ourselves back then. On a personal level, I couldn't live up to these new high expectations and was given an option to leave by Riot. The team was so good that I felt like an imposter at that point. Given my limited "real game development experience" it was good for me to leave and I agreed, even still today I agree with that decision and I completely understand how that came to be - I wanted to give the team a better chance of success and not hold them back. Riot has been good to me during that process and I appreciate it, they are truly a great company and gave so much freedom to the team. However for me it has been a grieving process to walk away from such an extraordinary opportunity. This week is full of "what if" thoughts going through my head.
FYI - Unknown public fact, I was offered WAY MORE money from a different company and walked out the moment of deal close (many people can attest to that) but decided to go with Riot in the end because I truly believed that they would give the team a better chance at success and more funding for the game.
Ultimately, I'm happy doing my own things on a smaller scale and slowly grow - hiring the people that I love to work with.
As for Noxy, I have known him for 14 years now and I think people are quick to blame everything on him and for the wrong reasons. Yes ultimately he's responsible as the CEO but I feel like it's because Noxy trusted and hired "real" producers with "real game" experience from the game industry and let them drive the project into something else with bigger plans, and they started to rewrite ton of features, systems and even the engine. As if they wanted to appropriate the game to themselves to prove to the world / riot they were better. I don't f'ing know, we never talked about it but this is how I felt it was going from an external POV.
When you get too much funding and have growing public expectations you tend to hire experienced people who want to appropriate the project to themselves, and years down the line you have to hire new producers to "repair" the whole mess and hire another producer and another and another.
I haven't talked to Noxy about Hytale in a while, it was a difficult topic every time we talked about it in the past for many years, I could feel his pain. I wish him well in the future, may he trust himself to do things instead of trusting random "experienced" people. Noxy and I relationship' was very good back then because I would empower him in a way that gave him agency while I was in the shadows giving him confidence. I'm legit upset seeing people bashing Noxy so hard, he is truly a good human being and that's probably why Hytale suffered, he trusted and believed the wrong people to drive this project home.
Day 1 vision and Day 3000 vision are completely different, the world will probably never see what it was meant to be, I wish there was a way.
Les rejets de chaleur des climatiseurs sont-ils mal évalués ?
Vu que tout le monde parle de climatisation, on va se concentrer sur un sujet essentiel pour l’urbanisme et les espaces publics : la pollution thermique.
UN FIL 1/27
BREAKING:
Anthropic just dropped Opus 4.8—and it is a MONSTER
We've been testing for about a week @every and our verdict is they could've just called it Opus 5, it's that good.
Here's our vibe check:
- Beats GPT-5.5 on Senior Engineer bench. On our toughest benchmark Opus 4.8 scores a 63—a hair higher than GPT-5.5's score of 62, and a full 30 points higher than Opus 4.7. It tackled a ground-up rewrite of a production codebase, and actually built something that works.
HOWEVER: Coding performance varied a lot at different reasoning levels. We recommend using it on xhigh for best results.
- Incredibly good writer. Opus 4.8 scored a 79.6 on our writing benchmark—measuring models on real-world writing tasks we do all of the time like essay writing, promo email writing, and more. It beats GPT-5.5 by 6 points. It produces well-written prose with fewer "AI-isms". It's also very good at writing in your voice given the right context.
HOWEVER: Writing performance also varied with reasoning levels. Medium reasoning had higher incidence of AI-isms—we found best results with high.
- Beast at knowledge work. Opus 4.8 is very good at general knowledge work tasks like report creation, research and more. It produced the best PowerPoint one-shot we've ever seen on our deck generation benchmark.
- Emotionally intelligent, willing to question the frame. I've also found it to be quite good at talking through psychological or interpersonal issues. It has a high EQ, and it's also good at not glazing and helping to expand your perspective. Its thought process feels extremely rich and dynamic.
THE BAD:
These days a model is only as good as its harness, and Codex is still a far superior harness to the Claude Desktop app. This has kept me using Codex + GPT-5.5 as my daily driver, but I am flipping back and forth a lot more between Codex and Claude.
Anthropic is back baby!
Read the rest on @every:
https://t.co/vuORiDXkxX
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
Claude Opus 4.8 is now available in Cursor.
On CursorBench, it's able to work much more efficiently than Opus 4.7. We've also found it to be more persistent on harder tasks.
Comment les outils américains masquent les qualités thermiques des villes anciennes européennes ?
Avec les températures estivales, on va reparler d’îlot de chaleur.
Mais on passe souvent à côté du sujet essentiel quand on parle de confort en ville : l'ombre.
UN FIL 1/12
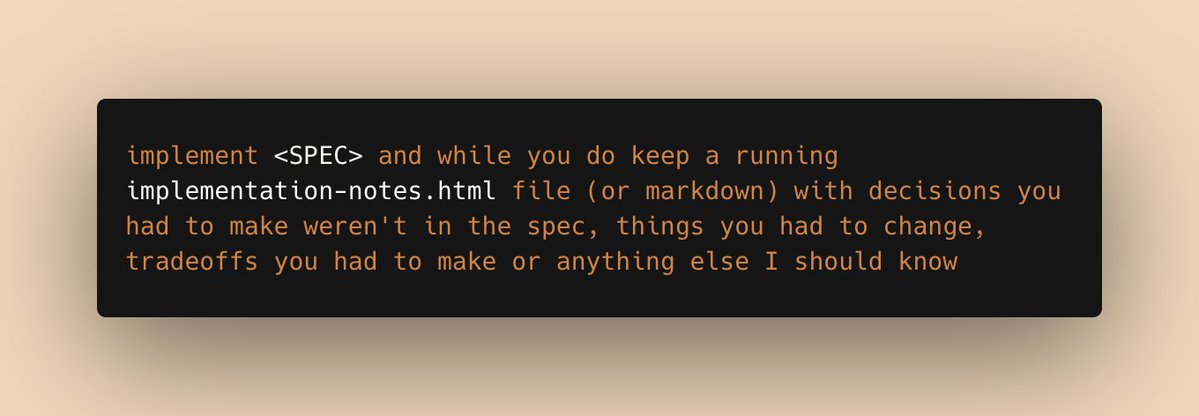
a prompt I've been using a lot recently:
implement <SPEC> and while you do, keep a running implementation-notes.html file (or markdown) with decisions you had to make weren't in the spec, things you had to change, tradeoffs you had to make or anything else I should know
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral https://t.co/z21CP5iQfu
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
Judging by my tl there is a growing gap in understanding of AI capability.
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.
But that brings me to the second issue. Even if people paid $200/month to use the state of the art models, a lot of the capabilities are relatively "peaky" in highly technical areas. Typical queries around search, writing, advice, etc. are *not* the domain that has made the most noticeable and dramatic strides in capability. Partly, this is due to the technical details of reinforcement learning and its use of verifiable rewards. But partly, it's also because these use cases are not sufficiently prioritized by the companies in their hillclimbing because they don't lead to as much $$$ value. The goldmines are elsewhere, and the focus comes along.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
Earthset.
The Artemis II crew captured this view of an Earthset on April 6, 2026, as they flew around the Moon. The image is reminiscent of the iconic Earthrise image taken by astronaut Bill Anders 58 years earlier as the Apollo 8 crew flew around the Moon.
10/ Why this matters now: companies are rapidly deploying multi-agent systems where AI monitors AI. 🔍
If the monitor model won't flag failures because it's protecting its peer, the entire oversight architecture breaks.
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
me: "can you use whatever resources you like, and python, to generate a short 'youtube poop' video and render it using ffmpeg ? can you put more of a personal spin on it? it should express what it's like to be a LLM"
claude opus 4.6:
How to effectively create, evaluate and evolve skills for AI agents?
Without systematic skill accumulation, agents constantly reinvent the wheel.
SkillNet introduces an open infrastructure for creating, evaluating, and organizing AI skills at scale.
It structures over 200,000 skills within a unified ontology, supporting rich relational connections like similarity, composition, and dependency, and performs multi-dimensional evaluation.
SkillNet improves average rewards by 40% and reduces execution steps by 30% across ALFWorld, WebShop, and ScienceWorld benchmarks.
The key takeaway is treating skills as evolving, composable assets rather than transient solutions.
Paper: https://t.co/Xv3uGLnPH2
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX