How did a 20-year-old beat Grok. And ChatGPT. And Perplexity. And Gemini?
In part one @blevlabs laid out how: he built a very different architecture to take AI to a new human level.
Cognitive architectures, he calls them.
I call them AI's with consciousness. Ones that learn, evolve, build themselves, and do so like we do.
Part I is here: https://t.co/lVHQJHNsIE
In this part two, he goes more into the technology.
And this was recorded more than a week ago in my home. Since then his system has gotten way better.
An exponentially learning system.
It is how we are going to get to AGI.
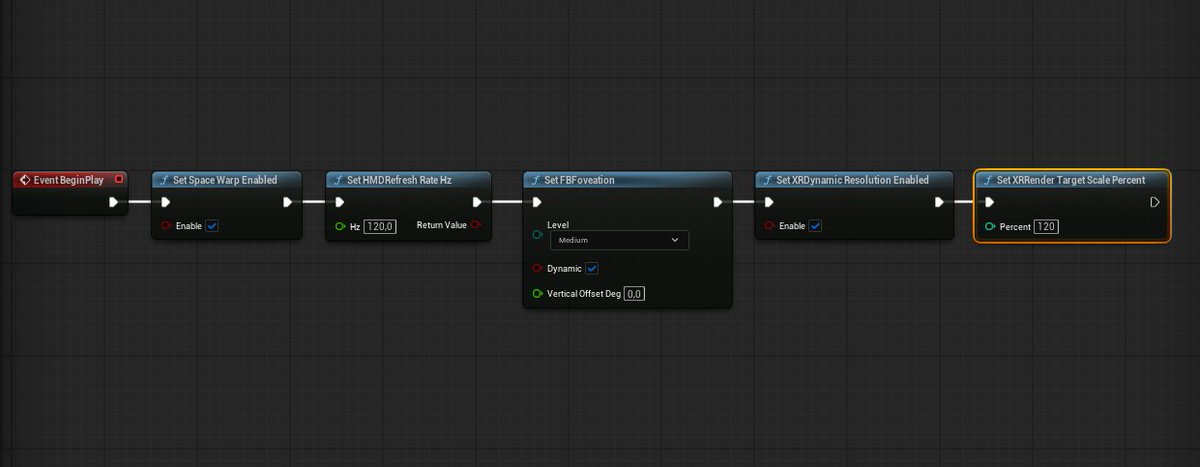
My @OpenXR plugin for Unreal Engine is here! Starting 5.7+ it helps you unleash XR dev in Unreal without the need of 3rd party vendor plugins! No more wait for Meta, you can use AppSW, Passthrough, Dynamic FFR, Dynamic Res, right now! And there is NO telemetry #ue5#vr
This is the JPEG moment for AI.
Optical compression doesn't just make context cheaper. It makes AI memory architectures viable.
Training data bottlenecks? Solved.
- 200k pages/day on ONE GPU
- 33M pages/day on 20 nodes
- Every multimodal model is data-constrained. Not anymore.
Agent memory problem? Solved.
- The #1 blocker: agents forget
- Progressive compression = natural forgetting curve
- Agents can now run indefinitely without context collapse
RAG might be obsolete.
- Why chunk and retrieve if you can compress entire libraries into context?
- A 10,000-page corpus = 10M text tokens OR 1M vision tokens
- You just fit the whole thing in context
Multimodal training data generation: 10x more efficient
- If you're OpenAI/Anthropic/Google and you DON'T integrate this, you're 10x slower
- This is a Pareto improvement: better AND faster
Real-time AI becomes economically viable
- Live document analysis
- Streaming OCR for accessibility
- Real-time translation with visual context
- All were too expensive. Not anymore.
Human3R: Everyone Everywhere All at Once
Note: I recorded the video from the interactive demo on their project page (linked in the comment below).
Abstract (excerpt):
Human3R jointly recovers global multi-person SMPL-X bodies ("everyone"), dense 3D scenes ("everywhere"), and camera trajectories in a single forward pass ("all-at-once").
Our method builds upon the 4D online reconstruction model CUT3R and uses parameter-efficient visual prompt tuning to preserve CUT3R's rich spatiotemporal priors while enabling direct readout of multiple SMPL-X bodies.
Human3R is a unified model that eliminates heavy dependencies and iterative refinement. After being trained on the relatively small-scale synthetic dataset BEDLAM for just one day on one GPU, it achieves superior performance with remarkable efficiency: it reconstructs multiple humans in a one-shot manner, along with 3D scenes, in one stage, at real-time speed (15 FPS) with a low memory footprint (8 GB).
"Mathematics for Computer Science"
This book from MIT is complete Beginner Friendly. Now available FREE.
To get: -
1. Follow (So I can DM you )
2. Like & retweet
3. Reply " Send "
A former Meta engineer has built a head-tracked system that uses just your front-facing camera to turn any screen into a 3D window. No glasses, no headset – just real-time motion parallax that makes flat displays feel alive.
Learn how it works: https://t.co/304KZSXP6k
this might be the coolest blogpost I ever written
I dove deep into:
- player detection with RF-DETR
- player tracking with SAM2
- team clustering with SigLIP and K-means
- number recognition with SmolVLM2 and ResNet
I hope you'll like it
link: https://t.co/PPPGTD8L2v
A light and smart wearable platform with multimodal foundation model for enhanced spatial reasoning in people with blindness and low vision https://t.co/Py9Gb6XKp7