Hosting an event with YC founders and applied researchers/res. engineers in Boston / Cambridge.
Join us to talk about hard research problems and startups!
AI is already helping Canadian companies solve real problems, improve services and compete globally.
Today in Vancouver, we announced $66 million in support for 44 Canadian companies through the AI Compute Access Fund to help them access the compute power they need to scale and grow here in Canada.
Canadian talent.
Canadian innovation.
Building Canada strong for all Canadians.
🇨🇦
L’IA aide déjà les entreprises canadiennes à résoudre des problèmes concrets, à améliorer leurs services et à être compétitives à l’échelle mondiale.
Aujourd’hui, à Vancouver, nous avons annoncé un soutien de 66 millions de dollars par l’intermédiaire du Fonds d’accès à une capacité de calcul pour l’IA à 44 entreprises canadiennes, afin de les aider à accéder à la puissance de calcul dont elles ont besoin pour se développer et croître ici, au Canada.
Talents canadiens.
Innovation canadienne.
Bâtir un Canada fort pour tous les Canadiens.
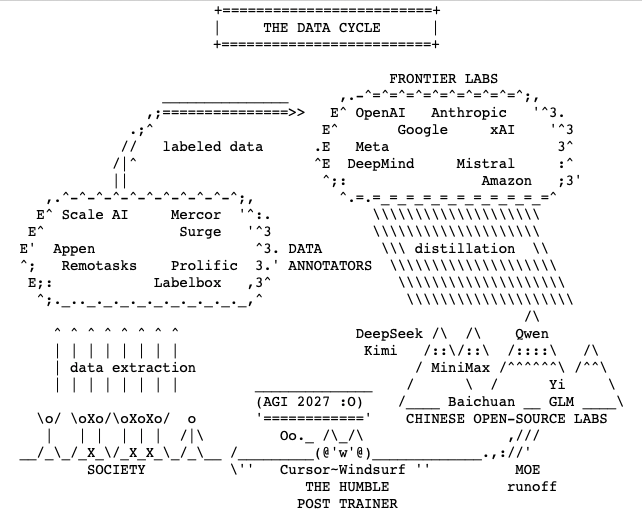
Many well written arguments. And the thesis itself is what I’ve been a fervent believer of since the so-called “plateaus” hit in late 2024.
Overparametrized models have a lot more secrets we can unlock.
This is an interesting result and we found something complementary. SSD is the clean case where SFT is on unfiltered samples. Our work, Compute as Teacher (CaT), asks what additional signal you can extract when you have multiple rollouts that disagree with each other. CaT exploits disagreement across multiple rollouts and synthesizes them into a better pseudo-reference answer, decomposing it into binary rubrics for scoring in RL. Interestingly, RL on these synthetic rewards consistently outperforms SFT on the same synthetic targets.
@aryanagxl@BoWang87 Interesting. Are you basically wondering whether the model mainly got better at 'picking' its answer? Are you expecting the positive case (it moved a lot)?
The tree-of-possibilities idea is exactly what I’ve been looking for as I build our internal auto research engineering system. I’d bet a lot from systems research applies here. It feels adjacent to model checking, state-space exploration, and symbolic execution.
The AI Scientist: Towards Fully Automated AI Research, Now Published in Nature
Nature: https://t.co/nNfpSV5e5I
Blog: https://t.co/i6h8LVQOdl
When we first introduced The AI Scientist, we shared an ambitious vision of an agent powered by foundation models capable of executing the entire machine learning research lifecycle.
From inventing ideas and writing code to executing experiments and drafting the manuscript, the system demonstrated that end-to-end automation of the scientific process is possible.
Soon after, we shared a historic update: the improved AI Scientist-v2 produced the first fully AI-generated paper to pass a rigorous human peer-review process.
Today, we are happy to announce that “The AI Scientist: Towards Fully Automated AI Research,” our paper describing all of this work, along with fresh new insights, has been published in @Nature!
This Nature publication consolidates these milestones and details the underlying foundation model orchestration. It also introduces our Automated Reviewer, which matches human review judgments and actually exceeds standard inter-human agreement.
Crucially, by using this reviewer to grade papers generated by different foundation models, we discovered a clear scaling law of science. As the underlying foundation models improve, the quality of the generated scientific papers increases correspondingly. This implies that as compute costs decrease and model capabilities continue to exponentially increase, future versions of The AI Scientist will be substantially more capable.
Building upon our previous open-source releases (https://t.co/H1tBT14Yx8), this open-access Nature publication comprehensively details our system's architecture, outlines several new scaling results, and discusses the promise and challenges of AI-generated science.
This substantial milestone is the result of a close and fruitful collaboration between researchers at Sakana AI, the University of British Columbia (UBC) and the Vector Institute, and the University of Oxford. Congrats to the team!
@_chris_lu_@cong_ml@RobertTLange@_yutaroyamada@shengranhu@j_foerst@hardmaru@jeffclune
Agreed. Part of OnDeck and my thesis is that:
- systems will prevail in performance,
- todays models are severely underutilized. And tomorrow’s too, leaving a gap.
- multi-step reasoning can close the gap, and do so faster than base model improvements or tuning on every single domain will
Haven't gotten around to writing in a bit, here's a short blog on my thoughts since releasing RLMs on the state of AI research.
A stronger belief I hold is that future LMs will be scaffolds, and that current LMs are already far more capable than we use them for!
Hosting an event with YC founders and applied researchers/res. engineers in Boston / Cambridge.
Join us to talk about hard research problems and startups!