#Zer0Con2026, a wrap up!
Big thanks to our speakers, sponsors, participants, and staff members for making this incredible journey with us.
Special appreciation to those who joined from a far despite ongoing global situation, we truly appreciate your effort coming all this way. 🙏
Wishing everyone a safe trip home, and we look forward to seeing you again at "🔴POC2026" this November!
#deepsec 12/16/ 2025 "Attacking Apple Display Co-processor" by Ye Zhang maps Apple’s DCP attack surface, shows firmware analysis and fuzzing that led to 14 CVEs and code execution on the display coprocessor, and reviews Apple’s fixes and new mitigations. https://t.co/KYlSs1jqBb
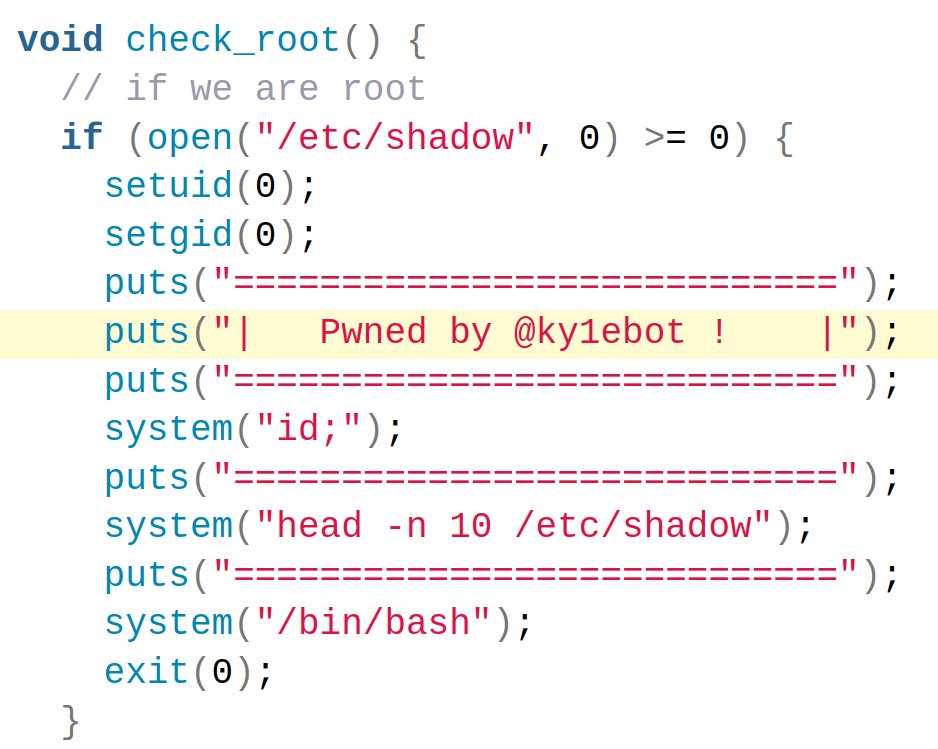
SSD Advisory — Linux kernel TAPRIO OOB
An article about exploiting an RCU-involved race condition in the TAPRIO network queuing discipline implementation. The exploit is by @ky1ebot.
https://t.co/qEvz8BzxDq
Neat research from @eva_info_sec, highlighting (yet again), the increased risk of supply chain attacks introduced by dependency managers 😱
https://t.co/sVsyvqEWJy
These 94 lines of code are everything that is needed to train a neural network. Everything else is just efficiency.
This is my earlier project Micrograd. It implements a scalar-valued auto-grad engine. You start with some numbers at the leafs (usually the input data and the neural network parameters), build up a computational graph with operations like + and * that mix them, and the graph ends with a single value at the very end (the loss). You then go backwards through the graph applying chain rule at each node to calculate the gradients. The gradients tell you how to nudge your parameters to decrease the loss (and hence improve your network).
Sometimes when things get too complicated, I come back to this code and just breathe a little. But ok ok you also do have to know what the computational graph should be (e.g. MLP -> Transformer), what the loss function should be (e.g. autoregressive/diffusion), how to best use the gradients for a parameter update (e.g. SGD -> AdamW) etc etc. But it is the core of what is mostly happening.
The 1986 paper from Rumelhart, Hinton, Williams that popularized and used this algorithm (backpropagation) for training neural nets:
https://t.co/f52IcDNitR
micrograd on Github: https://t.co/GaTd16jRnB
and my (now somewhat old) YouTube video where I very slowly build and explain:
https://t.co/EPGG6kd5Yz
New Project Zero blog post by Sergei Glazunov and Mark Brand: Project Naptime: Evaluating Offensive Security Capabilities of Large Language Models https://t.co/txvkXH5oCC
Better late than never!
The slides of our talk "Attacking Samsung Galaxy A* Boot Chain" at @offensive_con can be found here: https://t.co/P6gtwDftBp
The video is also available: https://t.co/RnGuJHOIJA
It's a great week for a vuln research newsletter 📰 🏴☠️
"Inside The 0-day Market" slides from @mdowd@NCCGroupInfosec with some musl heap magic
.NET RE fun from @SinSinology and @Horizon3Attack
MIPs ROP from @ruikai
+ jobs and more 👇
https://t.co/gZWlI3ACB0
Finally finish the talk "Game of Cross Cache: Let's Win It in a More Effective Way!", trying to solve challenges in cross-cache attack. Here are slides:
https://t.co/I3T63jHA68