this Anthropic researcher wrote one of the best articles you can find here on AI research. obviously, Hamming's classic book is highly suggested to learn how to develop a "Research Taste".
2025 just look at agent traces
2026 agents look at agent traces
great intro by @lotte_verheyden as part of the new https://t.co/ffHZbLdSSo on agent tracing, why it matters, and how to get it right
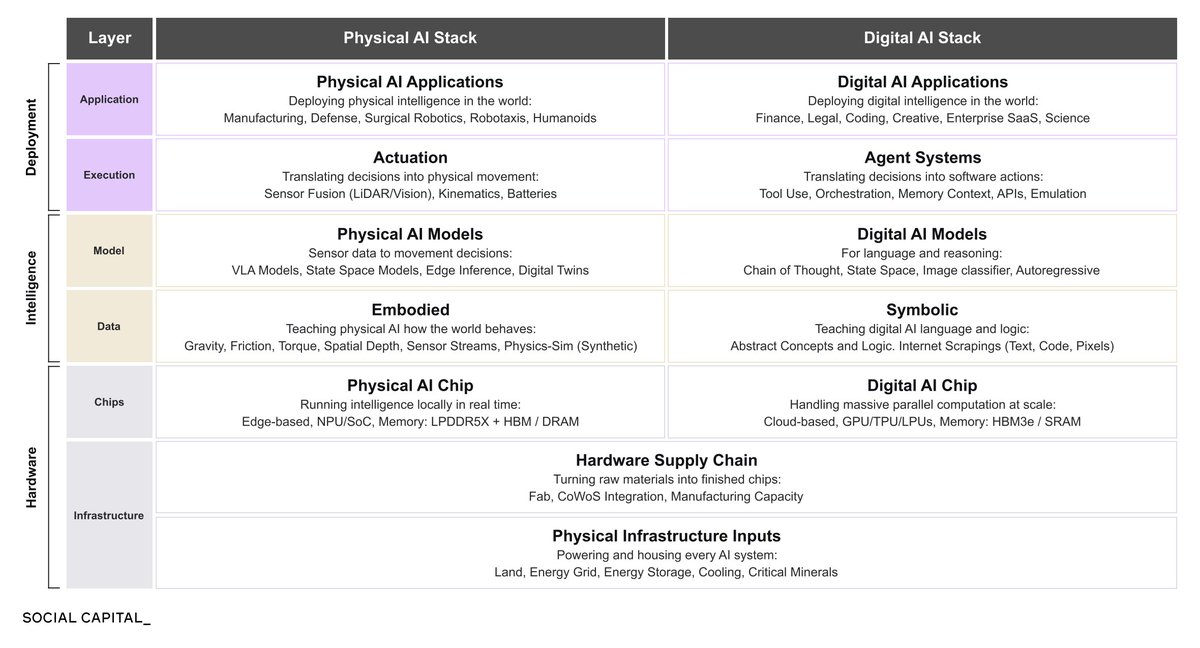
A framework to understand how value accrues across the AI stack.
This is a blueprint for understanding what builds AI into its pragmatic parts: what each layer is, where it ends, and where value is accrued. So here’s how you can think about it:
1. Layer 1 - Infrastructure
Before any AI model trains or any robot moves, an industrial foundation must exist. Land, energy grids, cooling systems, critical minerals, and fabrication facilities. Infrastructure is the constraint that all the other layers depend on.
2. Layer 2 - Chips
Transistors that are etched onto silicon wafers using extreme ultraviolet light. This is what allows both physical and digital AI to take an input, process it, and return a predictive output. The more transistors that fit on a chip, the more computation it can perform.
3. Layer 3 - Data
Both digital and physical models train on data. Digital models train on text, code, and images; physical models train on gravity, friction, depth, and sensor streams. The more accurate the data, the more accurate the output.
4. Layer 4 - Models
A model is a system that learns from examples. Feed it enough examples of inputs paired with correct outputs, and it adjusts its internal structure until it can predict correct outputs on inputs it has never seen before.
LLMs represent a specific class trained on text. They learn by processing billions of examples of human language, developing the ability to write, reason, summarize, and generate code.
5. Layer 5 - Execution
This is what lets models take actions on behalf of users. The execution layer lets models pursue objectives through sequential action: observing the environment, reasoning about the next step, acting, and looping until the goal is reached.
6. Layer 6 - Application
All of the AI Stack’s revenue originates at the application layer, then goes to the layers below.
Every dollar paid for AI is paid for an outcome, a task completed, and an answer delivered. Nobody wants H100s for their own sake. They want H100s because someone, somewhere, wants to run an application.
These are the different layers that make up the entire ecosystem of AI.
We did a full study on the AI stack. If you want to read about it, head over to my Substack (https://t.co/uaxeJk63aO)
Introducing Agent Orchestration in Notion 🎼
Imagine a Decagon ticket routes to your coding agent, which proposes a fix and loops your team in to approve. That’s no longer a dream.
Now, anyone can work with agents in Notion, not just engineers.
Useful tip to cut time-to-first-token on longer prompts in the API: pre-warm the prompt cache.
Send your system prompt before the user prompt. Claude writes it to the cache, but skips generating any output.
When the real user request lands, it'll hit a warm cache.
> undergrad at Harvard
> then went to Yale
> then 3 yrs at Bain
> 4 yrs at Blackstone
> 6 yrs at airbnb
> CFO of cedar
> CFO of fanatics
> CFO of anthropic
insane.
BIG one for devs today. Introducing the Notion Developer Platform:
- Notion CLI, ntn (Notion in your terminal)
- Workers (run code on Notion's infra)
- Database sync (any data source into Notion)
- Agent tools (build any workflow)
- Webhook triggers (trigger Notion from any app)
- External Agents API (bring any agent into Notion)
- Notion Agents SDK (use Notion Agents anywhere)
- …and a bunch more API improvements
And soon, you won't need to be a developer to build on Notion. Your agent will be one for you.
We integrated FrontierCS into Harbor and are releasing a preview long-horizon agent leaderboard (up to 835 turns, ~200K output tokens) with Kimi K2.6 @Kimi_Moonshot (score 46.9) and Claude Code Opus 4.7 @claudeai (43.0) 🚢. The goal: evaluate frontier coding agents in a setting where they iteratively write code, run experiments, read feedback, and improve in an extremely long loop.
FrontierCS tasks are open-ended optimization problems. Each task has a continuous score. There is no single accepted output. Agents need to search for better solutions under a step/time/token budget. This makes FrontierCS a natural fit for agentic evaluation. Just plan, code, test, revise, fail, recover, and keep optimizing.
Check out our blog: https://t.co/sx48mhfeny
FrontierCS GitHub: https://t.co/tBVjuFai89
I struggle to understand anything without a proper visualization
In Copile, you can ask agents to build HTML visual explainers right on the canvas, instead of opening it in browser tabs
Easy to revisit, edit, and share
Vercel's AI Gateway gives us a glimpse into real-world production AI and Agents usage.
Google is king of production scale, Anthropic dominates in coding & spend, OpenAI is growing fast since 5.4, and OSS continues to gain ground.
The AI race is a lot more fluid than it looks :)
Krishna Rao is the CFO of Anthropic, and this is his first podcast appearance.
He joined the company two years ago when run-rate revenue was about $250M. Today it is $30B. He has helped raise ~$75B and is responsible for the procurement and allocation of compute.
I feel lucky we get to hear what it is like to sit inside a company this consequential at a moment this pivotal.
We discuss:
- The cone of uncertainty
- How he allocates compute across Trainium, TPUs, and GPUs
- What investors misunderstand about model companies
- Why the returns to frontier intelligence keep rising
- Platform vs application and where Anthropic builds its own products
- How Anthropic uses Claude internally
I have asked my closing question about the kindest thing more than 500 times. Krishna's answer is one I have never heard before.
Enjoy!
Timestamps:
0:00 Intro
2:38 The Compute Canvas
6:51 The "Cone of Uncertainty"
11:58 Why the Returns to Frontier Intelligence Are So High
16:45 Recursive Self-Improvement
20:20 Scaling Laws
23:30 Sourcing $100 Billion in Compute
28:05 Platform vs. Application Strategy
32:52 Pricing Dynamics
38:48 How Anthropic’s Finance Team Uses Claude
43:24 Raising Capital & Overcoming Investor Skepticism
52:32 Public Perception, Risks, and Government Regulation
57:25 Mythos Release
1:12:33 What Could Derail the AI Revolution?
1:13:47 Biotech and Healthcare
1:15:31 The Kindest Thing
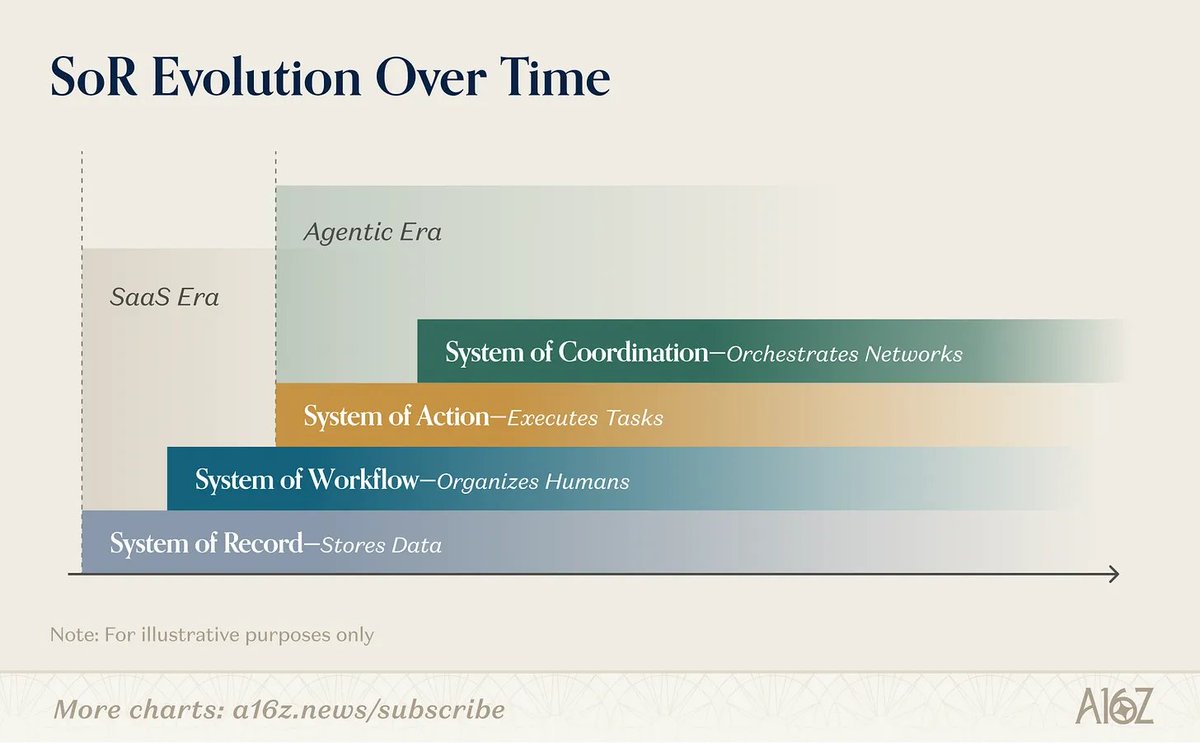
As system of record incumbents shift to headless agents, they are making an implicit bet that the data layer will remain the source of value.
Startups will compete on a new set of factors, like proprietary data, owning the action layer, real-world execution, and selling to technical buyers.
The next generation of systems of record is already starting to look agentic such that they capture the context, initiate the work, and record the data exhaust.
Full piece from a16z's Seema Amble: https://t.co/8hOj26bPuf
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral https://t.co/z21CP5iQfu
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
This is a good explanation of why the gap between open and closed models is larger than it appears in benchmarks. I would add in that current open models are also more fragile than closed: they handle out-of-distribution problems far less well & have lower emergent capabilities.