After several months of analyzing model trajectories on SpatialBench, we found issues in a subset of evals.
Some tasks depended on analysis decisions not specified in the prompt. Others had grader thresholds that were too narrow, rejecting valid solution paths the original domain expert had not considered.
We ran two rounds of independent expert attempts without access to solutions. This produced SpatialBench Verified: a 115-problem gold-standard subset of the original 159 evals where expected answers can be reproduced from only the prompt and associated data.
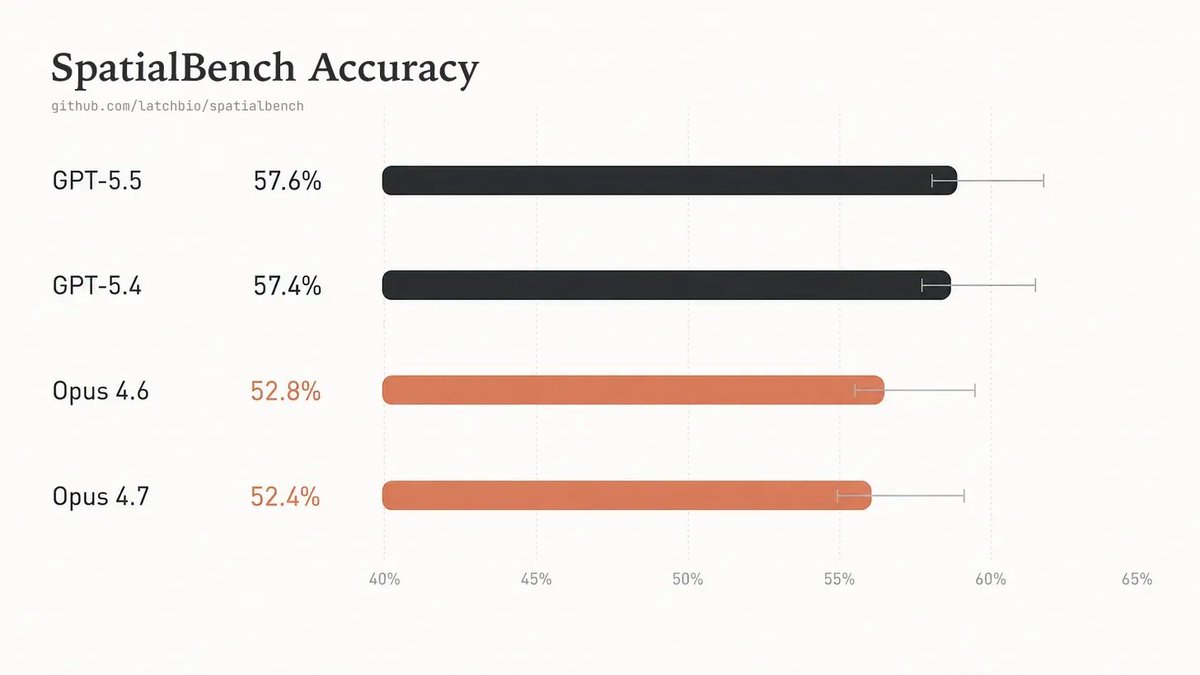
Model ordering is largely preserved, but scores increase 11.6pp on average.
Verifiability in biology is hard because correct answers often depend on tacit analysis choices. Our results suggest independent human verification should be a core part of benchmark construction.
Biology is the next agentic frontier after coding. Anthropic is aggressively improving their models on routine data analysis with careful attention to nuances of different assay types. Opus 4.8 is noticeably better at single cell / spatial analysis. We have already rolled it out to customers across pharma and academia. Cool to see our benchmarks on the system card.
Introducing SpatialBench-Long, a benchmark for long-horizon spatial biology. Agents must recover biological claims from raw data and realistic experimental context without prescribed methods.
24 evals span primary tumors, organoids, xenograft models, lineage-tracing systems, and aging/intervention biology. The best agents score 11.1%.
Figuring out how to benchmark agents on realistic biology research has quickly become one of my favorite types of engineering work. You work with scientists to get to the core of some biological claim, precisely assembling raw data/prior literature/experimental context in a little 'world' for an agent to stumble around in - only for its behavior to challenge what you thought to be true and to force you to deeply introspect empirical human behavior. Doing this well gets considerably more difficult as we better approximate and climb long horizon scientific work: the type one might publish in the results section of a paper or build a drug program around. Been working on a project in this direction for the past few months and excited to drop tomorrow.
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
If these machines become as ubiquitous as sequencers at the same time the labs start post training seriously in biology we're in for a scientific revolution
Agents calling tools now generate more revenue on Latch than scientists clicking buttons. From native deployments but also harnesses like Claude Code, Codex, Cursor across Pharma, biotech, academic labs. Product roadmap increasingly concerned with exposing compute intensive operations and experimental context to agents while designing new ways for humans to steer. Tool calls can dispatch a TB of data over a dozen computers. Errors in eg. parameter selection, infra failures, tool selection more expensive in time/cost than familiar agentic domains. Very early and exciting product space.
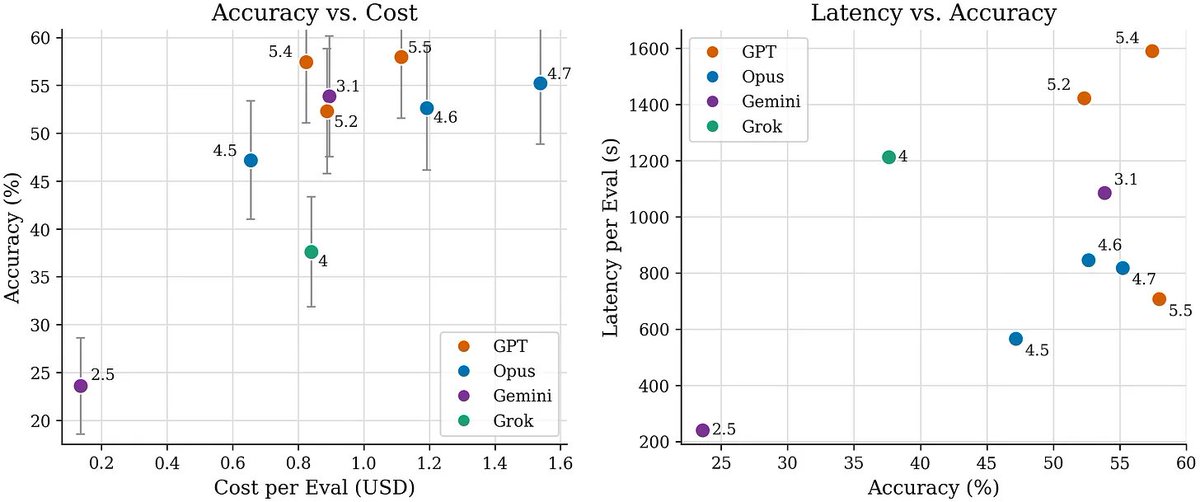
Are frontier models improving at single cell biology?
We revised scBench with additional rounds of scientist review and generated new benchmark data for Opus 4.7, GPT 5.5, and Gemini 3.1.
On accuracy, Gemini 3.1 roughly doubles, Opus 4.7 shows modest improvement, and GPT 5.5 shows little to no improvement.
On latency, GPT 5.5 improves substantially, Opus 4.7 shows little change, and Gemini 3.1 worsens by ~5x.
Gave a talk to Machine Learning @ Berkeley on benchmarking frontier models on spatial biology.
Why understanding how assays work is important, what verifiability might look like with messy biology + infrastructure challenges running agentic evals at scale.
New frontier models are not meaningfully improving at spatial biology.
Overall accuracy for GPT-5.5 and Opus 4.7 remains flat on SpatialBench. Scientist-reviewed trajectories reveal persistent gaps in assay-aware biological judgment.
This is the year of agents in biology. What you're seeing in code is already unfolding in molecular data analysis, reorganizing workflows in basic research and drug development.
Path forward is focused benchmarking + engineering scoped to specific types of assays. Just as coding agents had to reliably write JavaScript before they could build a browser, biology agents must first learn to accurately process and interpret concrete measurements, (eg. spatial assays), before they can reason about disease, drug mechanism, or patient response.
Our roadmap reflects this progression: procedural skill in analysis -> emergent biological reasoning -> synthesis across data types, translational context, and realistic ambiguity. Towards systems that can eventually support expensive, high-stakes decisions in drug programs or research projects.
Diffusion in biology is slower than software and needs to be thought through carefully. We work directly with the teams building measurement tech (eg. TakaraBio and Vizgen) and package assay-specific agents alongside their kits and instruments. Scientists complete sample preparation, then use these tech-specific agents to move from raw data to answers and figures. Our partners white-label our platform; we do not run a direct biotech sales motion.
Now hiring rapidly across major assay categories, prioritized by which we believe will contribute most to the area under the molecular data curve over the next several years
- Spatial
- Single Cell
- Epigenomics
- Genomics
- Perturbation/Screening
- Diagnostics
Looking for talented scientists and engineers with strong foundations in theory and deep experience in these areas to help us build scientifically accurate agents.
@themis_brown@themis_brown Really interested in your lab's work on tumor/tissue microenvironment shaping immune development, and also in this position. I've emailed you about my experience and background - would be glad to discuss further and learn more.
Very happy to share our new study defining the ontogeny of Thetis cells and the developmental cues that shape their early-life wave of differentiation. https://t.co/hVQa7zAfY1
Beautiful work led by exceptional @HHMI Gilliam fellow @YoselinAPI and @MSK postdoc Tyler Park 🧵 1/
Most current drug discovery efforts is structure-based eg. create small molecules or antibodies that best binds X. However, a drug may not drive its efficacy from its strongest binder. Taking a step away from structure-paradigm, we reason that if a CRISPR knockout of a gene mimics a drug's effects across cancer cell lines, that gene is likely the drug's target. This was done in @EytanRuppin in collaboration with @anideshpandelab and @BenDavidLab
Using this principle, we integrated drug and crispr profiles from 1000s of drugs to find their context specific targets (different cancers or when known target is not expressed but drug is yet killing cancer cells).
We call this tool DeepTarget. We show that this approach outperforms current structure based methods (AF3, RF, Chai) to find drug's target in a genome-wide search, when we had no information on what the target might be. We benchmarked in eight gold-standard drug-target pairs. It took us months to get this benchmarks (we hope this benchmark helps the field)
We present two experimentally validated cases and pls see the paper for this (link at the end).
An intriguing observation is that we had many cases where we have many small molecules targeting the same gene (eg. EGFR) and we found that small molecules with higher predicted target specificity show greater clinical advancement.
Very happy to hear your feedback. Here's the free access link: https://t.co/r6EjR58xg2
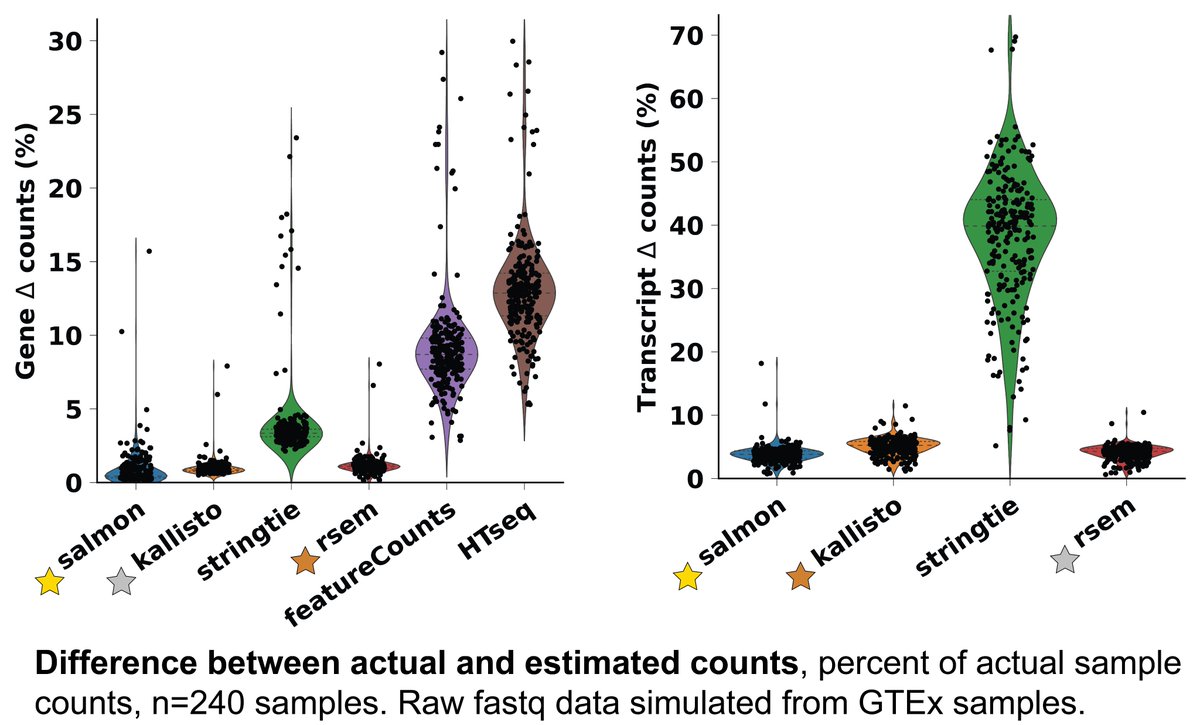
RNAseq counting tools are not perfect. I simulated 240 GTEx samples to test multiple tools. Below I show the difference between actual and estimated counts for each simulated sample.
But, what is causing this? And will it affect differential expression? (1/7) #Bioinformatics