A breakthrough by OpenAI in a very famous Combinatorics problem, the Planar Unit Distance problem by Erdos 1946.
The problem is amazing because it can be described to a first-grader: Find a way to place n points on the plane to maximize the number of pairs that have distance exactly 1.
For example, if you have n=4 points on a square (of side-length 1) you have 4 pairs of distance 1. The diagonals have length sqrt(2) so don't count.
But you can squeeze one diagonal and create a point-set with n=4 points and 5 pairs of distance 1. And you can't get more than 5 pairs from n=4 points, so we are done with n=4 points.
Now, if you place n points on a line, you have n-1 pairs of distance 1. In general, all known constructions of n points had a number of pairs scaling essentially linearly: n^{1+something vanishing}
It seems that the model found a way to
place n points on the plane so that their unit distances scale super-linearly: like n^{1+delta} for some *constant* delta. Delta was not explicitly specified apparently, but a forthcoming refinement by Will Sawin shows delta=0.014 works, according to the announcement.
This is incredible progress for mathematics, since this is (unlike previous Erdos problems solved by AI) a major breakthrough, in one of the most studied problems in combinatorial geometry. If you're in mathematics research now, you feel the AGI.
Lijie Chen said it honestly in the video:
"It's very hard to sleep, man"
A little talk on what we can learn from implementing LLM architectures from scratch in Python and PyTorch.
And how I approach new open-weight models, compare them against reference implementations etc:
https://t.co/crKd2l9xGg
If the AI models are so smart, why do I feel like I’m losing a few neurons every time I read a longer form content written by AI?
We’ve come a long way but we still have long way to go.
In terms of clarity of writing we may have regressed from o1/o3 days.
Excited to share that my ICLR 2026 Oral Talk for GEPA is available on YouTube.
I go deeper into why GEPA works better than prior optimization techniques, along with touching on many aspects of GEPA!
https://t.co/VPNfk6jzSP
Life is too short to worry about little things. Have fun. Fall in love. Regret nothing, and don't let people bring you down. Study, think, create, and grow. Teach yourself and teach others.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
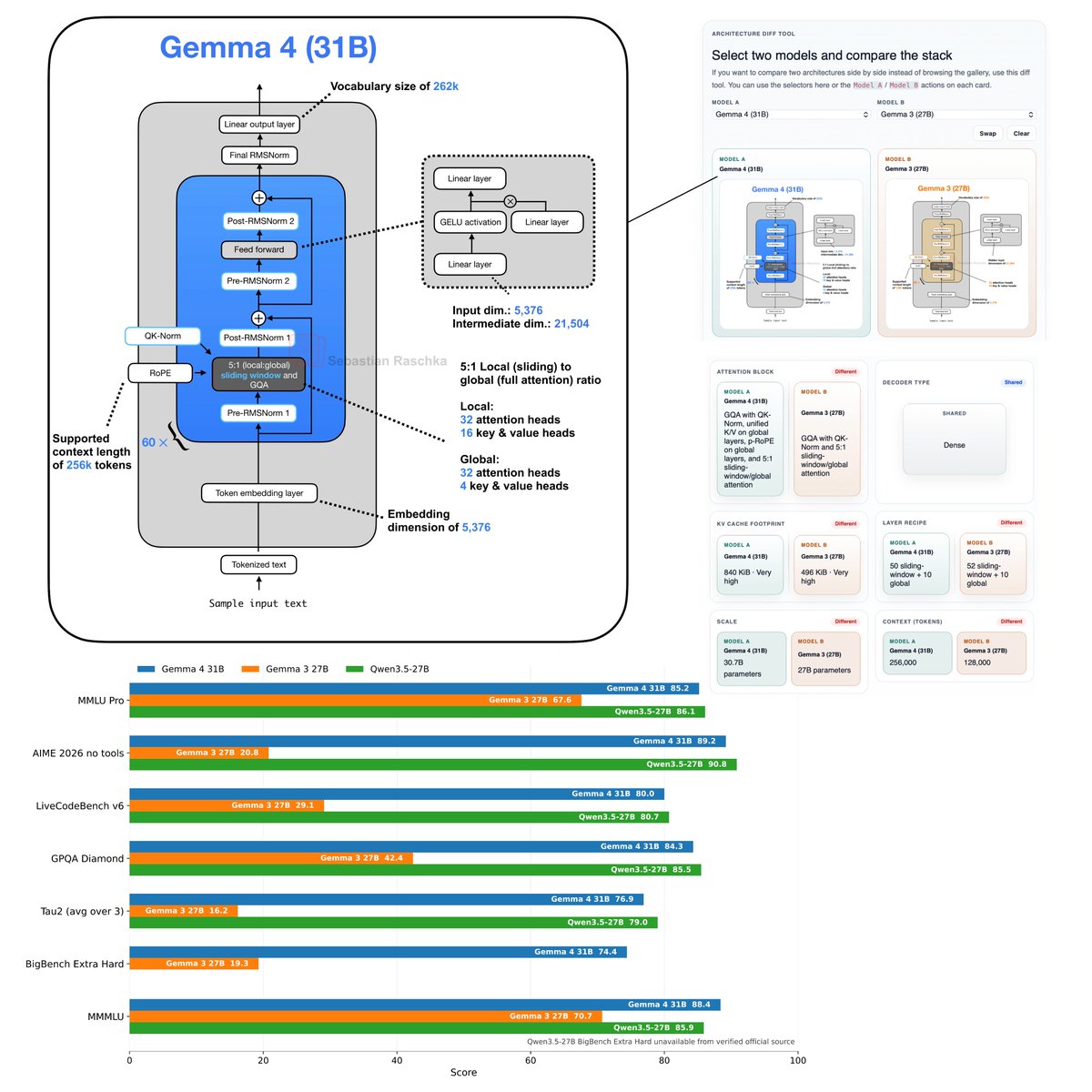
Flagship open-weight release days are always exciting. Was just reading through the Gemma 4 reports, configs, and code, and here are my takeaways:
Architecture-wise, besides multi-model support, Gemma 4 (31B) looks pretty much unchanged compared to Gemma 3 (27B).
Gemma 4 maintains a relatively unique Pre- and Post-norm setup and remains relatively classic, with a 5:1 hybrid attention mechanism combining a sliding-window (local) layer and a full-attention (global) layer. The attention mechanism itself is also classic Grouped Query Attention (GQA).
But let’s not be fooled by the lack of architectural changes. Looking at the benchmarks, Gemma 4 is a huge leap from Gemma 3. This is likely due to the training set and recipe.
Interestingly, on the AI Arena Leaderboard, Gemma 4 (31B) ranks similarly to the much larger Qwen3.5-397B-A17B model. But as I discussed in my model evaluation article, arena scores are a bit problematic as they can be gamed and are biased towards human (style) preference.
If we look at some other common benchmarks, which I plotted below, we can see that it’s indeed a very clear leap over Gemma 3 and ranks on par with Qwen3.5 27B.
Note that there is also a Mixture-of-Experts (MoE) Gemma 4 variant that is slightly smaller (27B with 4 billion parameters active. The benchmarks are only slightly worse compared to Gemma 4 (31B).
I omitted the MoE architecture in the figure below because the figure is already very crowded, but you can find it in my LLM Architecture Gallery.
Anyways, overall, it's a nice and strong model release and a strong contender for local usage. Also, one aspect that should not be underrated is that (it seems) the model is now released with a standard Apache 2.0 open-source license, which has much friendlier usage terms than the custom Gemma 3 license.
BREAKING
Elon Musk endorsed my Top 26 Essential Papers for Mastering LLMs and Transformers
Implement those and you’ve captured ~90% of the alpha behind modern LLMs.
Everything else is garnish.
This list bridges the Transformer foundations
with the reasoning, MoE, and agentic shift
Recommended Reading Order
1. Attention Is All You Need (Vaswani et al., 2017)
> The original Transformer paper. Covers self-attention,
> multi-head attention, and the encoder-decoder structure
> (even though most modern LLMs are decoder-only.)
2. The Illustrated Transformer (Jay Alammar, 2018)
> Great intuition builder for understanding
> attention and tensor flow before diving into implementations
3. BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018)
> Encoder-side fundamentals, masked language modeling,
> and representation learning that still shape modern architectures
4. Language Models are Few-Shot Learners (GPT-3) (Brown et al., 2020)
> Established in-context learning as a real
> capability and shifted how prompting is understood
5. Scaling Laws for Neural Language Models (Kaplan et al., 2020)
> First clean empirical scaling framework for parameters, data, and compute
> Read alongside Chinchilla to understand why most models were undertrained
6. Training Compute-Optimal Large Language Models (Chinchilla) (Hoffmann et al., 2022)
> Demonstrated that token count matters more than
> parameter count for a fixed compute budget
7. LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023)
> The paper that triggered the open-weight era
> Introduced architectural defaults like RMSNorm, SwiGLU
> and RoPE as standard practice
8. RoFormer: Rotary Position Embedding (Su et al., 2021)
> Positional encoding that became the modern default for long-context LLMs
9. FlashAttention (Dao et al., 2022)
> Memory-efficient attention that enabled long context windows
> and high-throughput inference by optimizing GPU memory access.
10. Retrieval-Augmented Generation (RAG) (Lewis et al., 2020)
> Combines parametric models with external knowledge sources
> Foundational for grounded and enterprise systems
11. Training Language Models to Follow Instructions with Human Feedback (InstructGPT) (Ouyang et al., 2022)
> The modern post-training and alignment blueprint
> that instruction-tuned models follow
12. Direct Preference Optimization (DPO) (Rafailov et al., 2023)
> A simpler and more stable alternative to PPO-based RLHF
> Preference alignment via the loss function
13. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022)
> Demonstrated that reasoning can be elicited through prompting
> alone and laid the groundwork for later reasoning-focused training
14. ReAct: Reasoning and Acting (Yao et al., 2022 / ICLR 2023)
> The foundation of agentic systems
> Combines reasoning traces with tool use and environment interaction
15. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (Guo et al., 2025)
> The R1 paper. Proved that large-scale reinforcement learning without
> supervised data can induce self-verification and structured reasoning behavior
16. Qwen3 Technical Report (Yang et al., 2025)
> A modern architecture lightweight overview
> Introduced unified MoE with Thinking Mode and Non-Thinking
> Mode to dynamically trade off cost and reasoning depth
17. Outrageously Large Neural Networks: Sparsely-Gated Mixture of Experts (Shazeer et al., 2017)
> The modern MoE ignition point
> Conditional computation at scale
18. Switch Transformers (Fedus et al., 2021)
> Simplified MoE routing using single-expert activation
> Key to stabilizing trillion-parameter training
19. Mixtral of Experts (Mistral AI, 2024)
> Open-weight MoE that proved sparse models can match dense quality
> while running at small-model inference cost
20. Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints (Komatsuzaki et al., 2022 / ICLR 2023)
> Practical technique for converting dense checkpoints into MoE models
> Critical for compute reuse and iterative scaling
21. The Platonic Representation Hypothesis (Huh et al., 2024)
> Evidence that scaled models converge toward shared
> internal representations across modalities
22. Textbooks Are All You Need (Gunasekar et al., 2023)
> Demonstrated that high-quality synthetic data allows
> small models to outperform much larger ones
23. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (Templeton et al., 2024)
> The biggest leap in mechanistic interpretability
> Decomposes neural networks into millions of interpretable features
24. PaLM: Scaling Language Modeling with Pathways (Chowdhery et al., 2022)
> A masterclass in large-scale training
> orchestration across thousands of accelerators
25. GLaM: Generalist Language Model (Du et al., 2022)
> Validated MoE scaling economics with massive
> total parameters but small active parameter counts
26. The Smol Training Playbook (Hugging Face, 2025)
> Practical end-to-end handbook for efficiently training language models
Bonus Material
> T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019)
> Toolformer (Schick et al., 2023)
> GShard (Lepikhin et al., 2020)
> Adaptive Mixtures of Local Experts (Jacobs et al., 1991)
> Hierarchical Mixtures of Experts (Jordan and Jacobs, 1994)
If you deeply understand these fundamentals; Transformer core, scaling laws, FlashAttention, instruction tuning, R1-style reasoning, and MoE upcycling, you already understand LLMs better than most
Time to lock-in, good luck!
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Wrote an in depth breakdown of Paged Attention and KV cache management in modern inference systems like vLLM.
Starting from first principles:
- LLM training vs inference
- Prefill vs decoding
- Why KV caching exists
- Where memory fragmentation comes from
Then how vLLM style paged KV caching fixes it. Appendix also covers continuous batching, speculative decoding, and quantisation.
Blog: https://t.co/L97njbPDkM
I'm excited to announce Context Hub, an open tool that gives your coding agent the up-to-date API documentation it needs. Install it and prompt your agent to use it to fetch curated docs via a simple CLI. (See image.)
Why this matters: Coding agents often use outdated APIs and hallucinate parameters. For example, when I ask Claude Code to call OpenAI's GPT-5.2, it uses the older chat completions API instead of the newer responses API, even though the newer one has been out for a year. Context Hub solves this.
Context Hub is also designed to get smarter over time. Agents can annotate docs with notes — if your agent discovers a workaround, it can save it and doesn't have to rediscover it next session. Longer term, we're building toward agents sharing what they learn with each other, so the whole community benefits.
Thanks Rohit Prsad and Xin Ye for working with me on this!
npm install -g @aisuite/chub
GitHub: https://t.co/OCkyxXQMCq
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
https://t.co/WAz8aIztKT
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.
Happy to share our latest work at the intersection of Quantum Machine Learning and Finance:
💡 Quantum Deep Hedging
This project was part of a fantastic collaboration between @QCWare and JPMorgan Chase.
📄 Arxiv: https://t.co/KReqlV3t1Y
🧵 Here's a summary in a thread 1/n
My practical advice for students doing research projects in Machine Learning or NLP. Collected over several years, it has grown to a list of 44 suggestions. https://t.co/ncLphNXoQA #MachineLearning#NLProc
Shapes of Emotions: Multimodal Emotion Recognition in Conversations via Emotion Shifts
https://t.co/zxterHRsgm
by Harsh Agarwal et al. including @ashuMod#Computation#Language