@KyleRayKelley@rahuldave@zeddotdev Feels like it's becoming a habit...
The first lines I write in any new language absolutely need to be a PR for @KyleRayKelley to review 🤣
Last time it was JS/CoffeScript this time Rust 🦀😎
@KyleRayKelley@zeddotdev@AtomEditor@nteractio Just looked at some old screenshots. Looks like we were copying what ipython did.
However, ipython only showed `In[*]` starting version in 8. Before that it would look something like `<ipython-input-1-6fcf9dfbd479> in <module>()` so even ipython didn't have line numbers.
We made our ultra-fast and ultra-small inference engine for Arm Cortex-M processors even smaller. We now require 49% less RAM for 8-bit MobileNetV2 than TensorFlow Lite for Microcontrollers with Arm’s CMSIS-NN kernels.
Read the article here: https://t.co/Y7llUkUveT
🏆 We built the world’s fastest and most memory-efficient deep learning inference software for Arm Cortex-M microcontrollers 🏆 for both Binarized Neural Networks and for 8-bit deep learning models.
https://t.co/Y7llUkUveT
Our latest paper has been accepted to the #MLSys2021 conference! Congratulations Tom, Arash, Adam, Lukas, Tim, Leon, Jelmer and Koen!
We wrote a short blog post about the paper and the importance of Larq Compute Engine: https://t.co/tKZvgQYnn3
It was great to see so many people attending our #tinyml webcast earlier this week! In case you missed the event, a recording of the talk is now online along with a short blog post explaining the main takeaways from our presentation: https://t.co/rwqQPPD8oC
A fascinating talk on binarized neural networks for #tinyml by Lukas of @plumerai is now up at https://t.co/0mVeqnGtvk, with slides at https://t.co/Cj3J1gHrVb
Come join us on Tuesday for our @tinyMLTalks webcast! @_lgeiger will explain how we use 🚀Binarized Neural Networks🚀 to enable real-time deep learning on cheap, low-power edge devices. You can register here: https://t.co/JcMdenewX2
We've released v0.4 of Larq Compute Engine!
Some of our internal work optimizing BNN performance on microcontrollers has made its way to mobile and Raspberry Pi, as have a few major architectural improvements.
🚀 Full change log: https://t.co/7P1Cn85lbI
We just published blog post about open source tools for #DeepLearning presented at our social event at the @iclr_conf!
Shout-out to all the co-authors for their great contributions and efforts. Without your help, this would not have been possible!
https://t.co/fma6o6u0Nu
(1/n)
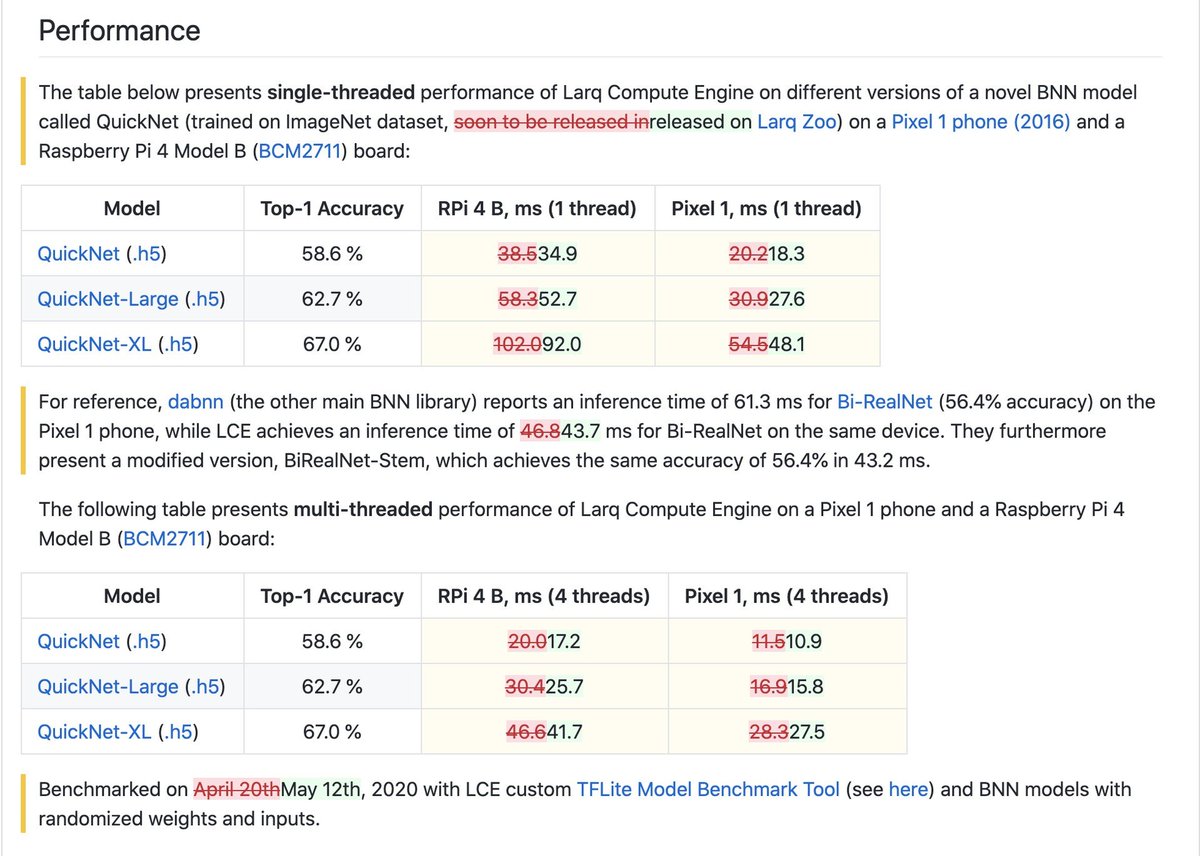
We’ve released Larq Compute Engine v0.3, featuring even faster BNN kernels and support for Python 3.8, TensorFlow 2.2, and Windows in the converter! 🎉
💻 Full release notes: https://t.co/ykUgHfzaXo
📚 Docs: https://t.co/awSf15mt66
@fchollet Improved contributor experience. Moving Keras out of the tf monorepo will hopefully help, but currently having to wait hours for tf to build on a laptop just for a small Python fix and then waiting weeks to get a PR review doesn't encourage community contributions.
@fchollet One recommended way to save and resume training
- tf.train.Checkpoint is great but requires too much custom code
- https://t.co/Cs86LtGGqY_weights and ModelCheckpoint don't reload optimizer state or epoch
- https://t.co/Cs86LtGGqY doesn't play well with tf.distribute
We wrote a blog post about how we’re applying a software 2.0 approach in the new module for state-of-the-art binarized neural networks in Larq Zoo (`zoo.sota`). It also features some exciting improvements across the whole Larq stack: https://t.co/k532X5Enga
We’ve just released Larq v0.9, featuring:
🔲 Non-zero padding
💾 Easier export for binary weights
📋 Improved model summaries
And lots more! 🎉 https://t.co/yuKkNgcZ03