Building apps has never been easier.
With Sites, Codex can turn your work, ideas, and plans into an interactive website or app your team can explore, use, and share with a URL.
Rolling out to Business and Enterprise plans, before expanding more broadly.
This is brilliant by @karthiks
The mixing of domain knowledge with data is the best way to go about improving performance in sports like football or cricket. We did that with Ind, RCB are doing it.
https://t.co/TE1doR8kkZ
@Shaun_Terhune beautiful! Are you based out of sugar hill? (because of that amazing photo you posted...) Spend a good amount of time on the backside of cannon in the winter but your pic motivated an intense longing to make that whole year round...
This goes without saying, but @lateinteraction deserves an enormous amount of credit for all the projects I have been involved in over the past 18 months. So much so that it is difficult to put into words lest I get choked up.
I'm incredibly excited to continue collaborating on our research projects, and to test them at scale while I am interning @PrimeIntellect
@emollick Do you think there is any point in requiring students to use a learning instead of doing system prompt as part of the university wide access package?
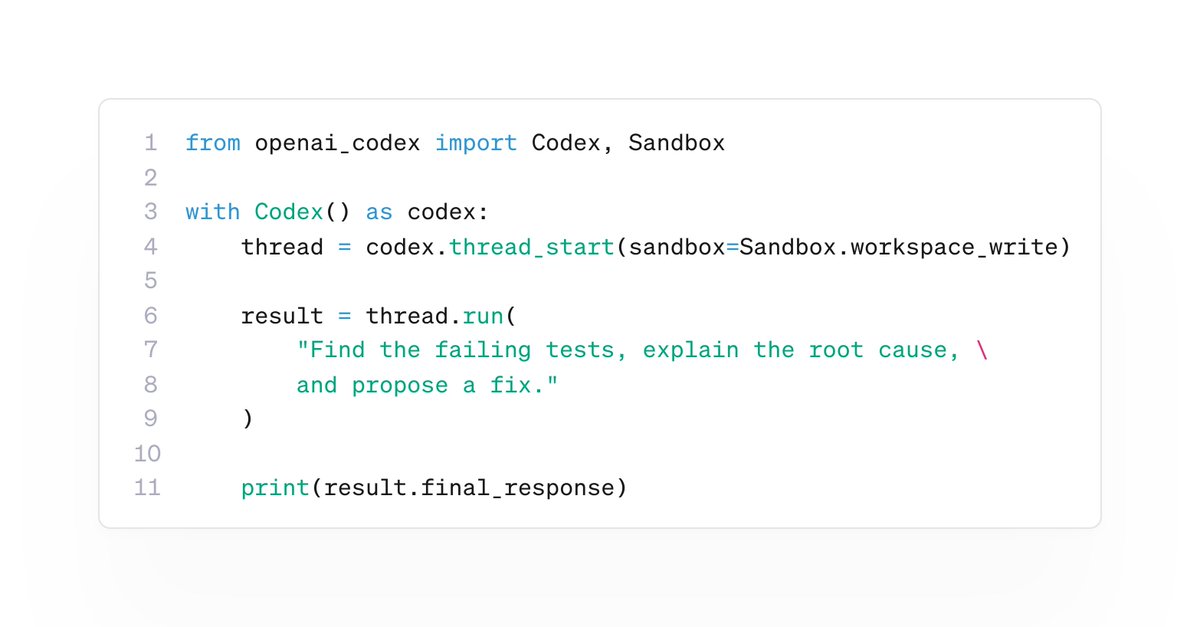
We just released the Codex Python SDK 🔥
You can now embed Codex directly into your Python apps and workflows!
> Start threads
> Run turns
> Stream progress
> Resume sessions
> Pass images
> Control sandbox access
All whilst reusing your existing Codex auth.
pip install openai-codex
Go build with it!!
Just saving this here to document a story and as a self reflection on whether AI is really making me more productive
Yesterday morning I found a way to complete the new HVM approach, that is much faster than before. I spent a few hours writing a spec, and then used Opus to implement. About 3k lines of C code later, everything worked and performance was incredible: 5x faster than HVM4 (stable at ~10x now). So, in one day I had outclassed HVM4. Incredible. I'd never have implemented that so fast manually.
Now, enter today. I want to turn this into a real thing, but I haven't fully read the 3k lines yet. So, how do I trust it? I spent the whole day auditing the code. With AI. Several bugs found, most minor like forgetting to collect() some argument. But then I stumble upon this:
λ{ inl: 1 ; inr: 1 }
This was a test. But wait. This is matching on inl/inr. So the branches should receive the value of the Either. But they were numbers instead. Numbers aren't functions. This makes no sense. So why this is a test?
It then stuck me. The AI completely misunderstood how function arities work. It literally assumed for no good reason that HVM5 was supposed to handle under/over-applied functions. For no good reason. I never wrote that. It never asked either. It just kinda thought "HVM is weird in some aspects, this might be one of them..." - and then it went on to implement a massive system to handle cases that should never happen to begin with. And all of that code is obviously wrong because it should not even exist. It is wrong. It is damage. And it is there.
But it isn't too bad either. I just told Opus that it was wrong. Perhaps not so politely. And it solved it just fine.
But then this begs the question. I spent ~20 hours in this file, and it is STILL not done. I went from 0 to 95% in the first 5 hours. Yet, 15 hours later, it is still not 100%. I suppose that is the real effect of using AI. If I had just written the C file manually in the last two days, would I not be further than where I am *right now*?
Surely, the first version would have taken much longer to drop. But when I'd finish writing all that code, there would be zero, literally zero retarded shit. And, just today, I caught 5 or 6 retarded shit. And the worst part is: I don't know what the number of retarded shit left is, but I'm afraid it is >0.
So if I have to read it all, review it all to ensure there is no retarded shit... what did I achieve by using AI, other than that dopamine anticipation?
UPDATE: @NASA can confirm a fireball over New England at 2:06 p.m. EDT on Saturday, May 30, 2026. The meteor was about 5 feet (1.6 meters) in diameter with a mass of 5.6 metric tons and entered Earth’s atmosphere at roughly 42,000 mph.
The meteor traveled through the atmosphere from northwest to southeast for 26 miles before breaking up at an altitude of 31 miles and producing a meteorite fall into Cape Cod Bay.
Based on the latest data, the energy released at breakup is estimated to be equivalent to about 230 tons of TNT, which accounts for the sonic boom.
Have questions? Check out our fireball FAQs: https://t.co/HyyRIGmeoI
@matsonj@AlexNoonan6 Seriously? Philly is way different from nyc is way different from Boston is way different from cambervilleis way different from Montreal. And that is just the northeast!!!
This administration is a scar on this country. Anyone supporting it is responsible - hold them accountable and stop doing business with them. That includes avoiding venture institutions and partners that actively participate and condone it.
https://t.co/zL0wLBXMAU
Startled to find out that there are young people who haven't read James Iry's magnificent "A Brief, Incomplete, and Mostly Wrong History of Programming Languages". Please drop what you're doing and head over.
https://t.co/bnzifwQ2p9
Something that mostly generalizes in-distribution is unlikely to challenge us for survival. Maybe we worry when 1000kcal is their energy usage. However the danger to our democracy, our ability to be intelligent, and the concentration of power in few hands is not good. Thank you for working on local inference: I suspect when the long term history of ai is written these might be key inflection points in what humans did with their power...
I made many custom lm for dspy...
..when we are done with this typing and improving of baselm, both custom lm and custom adapter will be immensely easier to do and streaming will be delightful :D
In the last year, I experimented with making custom lm for dspy. I made dspy-lm-auth, ovllm (both on pypi) and i also made some to better integrate with bedrock and another for MLX.
These were (are still) hacky because dspy did not have a public interface that was stable and complete for me to leverage. We are fixing that!!
DSPy delightfully identified that key modular parts of AI engineering and provides a brilliant scaffold for them (signature, adapter (adapter types), lm, modules, optimizers) and now, as those have mature we are ready to make their contract more explicit so that anybody can work hard on any of these components and be guaranteed they compose perfectly and with all the other ones. With this work I hope we will see a lot of community extension!
When we are done it will be easy to have dspy be the language to talk to any backend, sdk, provider you like!
This will make it so that dspy can optimize and orchestrate on YOUR stack easily! We will make sure your coding agents can code that connection from dspy to your infra of choice.
This will make it so that you will be able to use dspy as your language to try out new hot features on day zero because you will be able to easily add support for whichever modality drops for whichever model you want to use.
I love programming in dspy, I want dspy to talk to everything.
I want no ceiling for my AI programs.
We are making that happen!
Given this talk a couple of times the past month, and it still resonates with how I'm thinking about research in the era of R&D automation.
It is the golden age of asking questions!
@emollick Still feel Claude code was best when faced with the 400k context limit, and where it would send sub-context to appropriate sub-agents..now the new Ruling in the harness seems to be confused, and the context way more diffuse
@dbreunig We should expect this, shouldn't we, because most writing, especially engineering writing with jargon and all that lacks clarity. Bad writing is in-distribution, perhaps?