Research Scientist at @SalesforceAI | Ph.D. from @UCLA | B.S. from @Tsinghua_Uni | Foundation Model, Theory, Reinforcement Learning | Opinions are my own
Excited to share our method called 𝐒𝐞𝐥𝐟-𝐏𝐥𝐚𝐲 𝐟𝐈𝐧𝐞-𝐭𝐮𝐍𝐢𝐧𝐠 (SPIN)! 🌟Without acquiring additional human-annotated data, a supervised fine-tuned LLM can get stronger by SPIN. Check out how SPIN unleashes the full power of human-annotated data.
Joint work with @Yihe__Deng, @HuizhuoY, Kaixuan Ji, and @QuanquanGu👏
Link: https://t.co/2tNJDm5G6l
Key Tech:
👉 LLM generates its own training data from its previous iterations.
👉 LLM refines its policy by discerning these self-generated responses from those obtained from human-annotated data.
Check the detail 🔍 [1/N]
I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue. There's a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering. Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind.
🚀Introducing GRAPE: Group Representational Position Encoding.
Embracing General Relative Law of Position Encoding, unifying and improving Multiplicative and Additive Position Encoding, such as RoPE and Alibi!
Better performance with a clear theoretical formulation!
Project Page: https://t.co/eP0XAGZWZw
Paper: https://t.co/BpROgCmXet
Devoted to the frontier of superintelligence, hope you will enjoy it!
People are sleeping on Deep Agents.
Start using them now.
This is a fun paper showcasing how to put together advanced deep agents for enterprise use cases.
Uses the best techniques: task decomposition, planning, specialized subagents, MCP for NL2SQL, file analysis, and more.
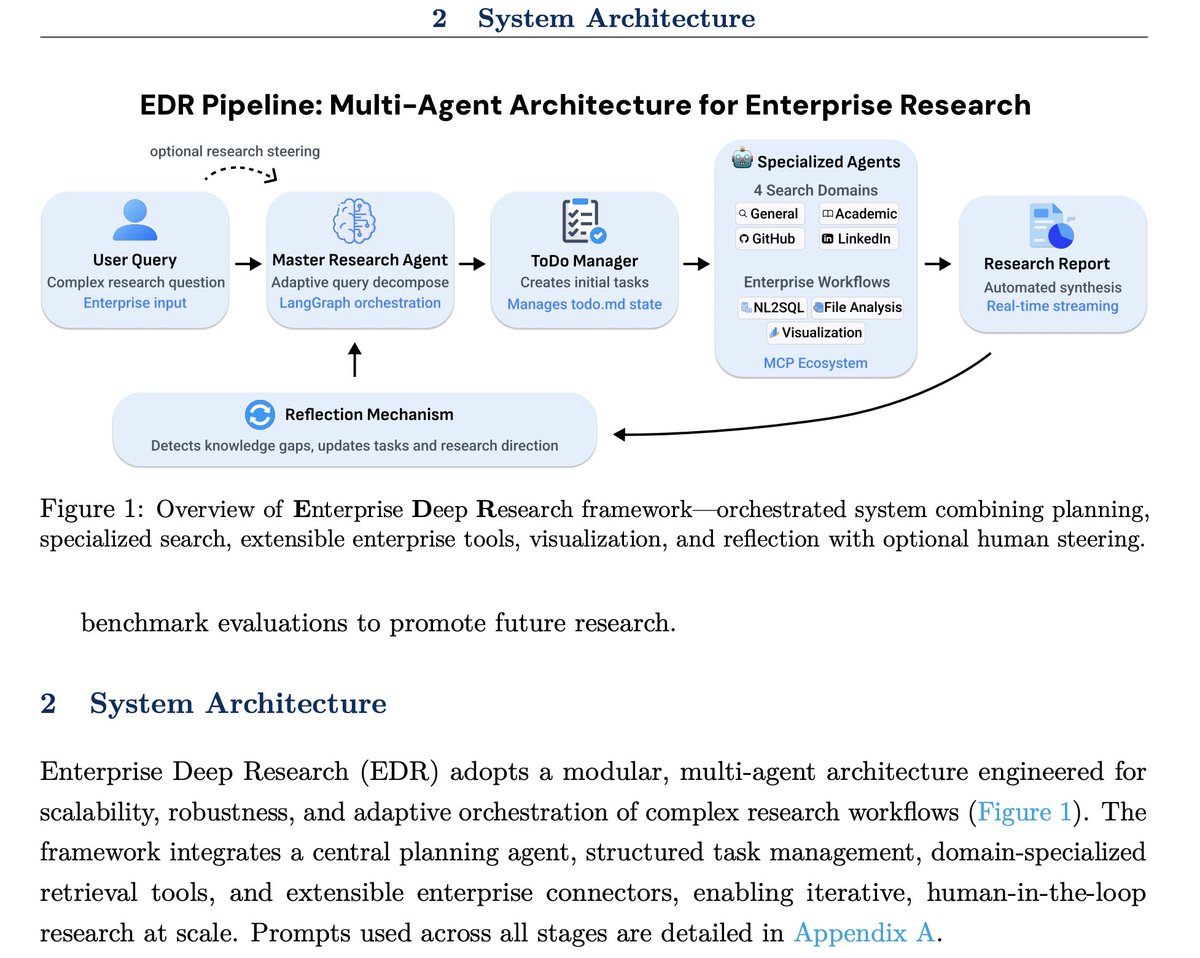
Introducing Enterprise Deep Research (EDR): A steerable multi-agent system that transforms complex enterprise research into comprehensive, actionable reports 📊
EDR combines 5 key components:
🧠 Master Planning Agent for adaptive query decomposition
🔍 4 specialized search agents (General, Academic, GitHub, LinkedIn)
🛠️ Extensible MCP-based tools (NL2SQL, file analysis, enterprise workflows)
📈 Visualization Agent for data-driven insights
🔄 Reflection mechanism with optional human-in-the-loop guidance
Results on open benchmarks:
✅ Outperforms SOTA on DeepResearch Bench (49.86 score)
✅ 71.57% win rate on DeepConsult vs OpenAI DeepResearch
✅ 68.5% coverage on ResearchQA across 7 research domains
We're releasing EDR-200 dataset with complete research trajectories from 201 benchmark evaluations 📂
📄 Paper: https://t.co/m1BgGN3cpb
💻 Code: https://t.co/FBXWkNZQqB
📊 Dataset: https://t.co/kVPPEn6zwH
Authors: @aksh_555@shoonyaka1@zxchen@iscreamnearby@huan__wang at @Salesforce AI Research
#MultiAgent #EnterpriseAI #DeepResearch #OpenScience
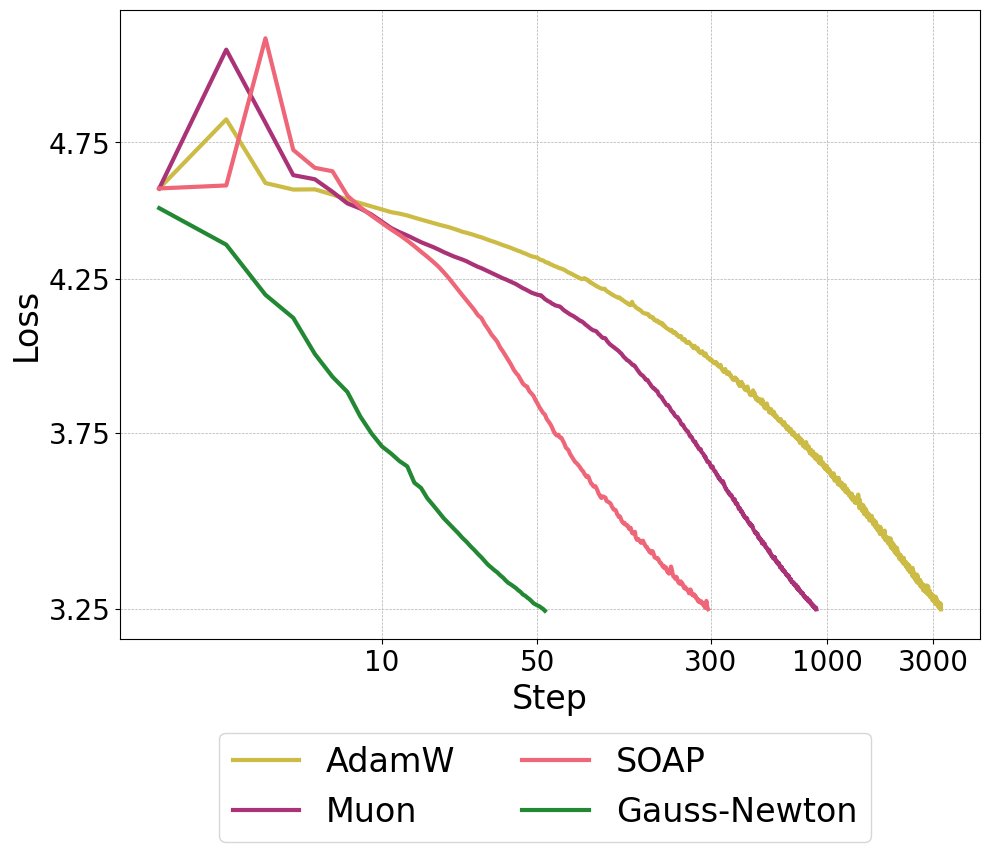
1/8 Second Order Optimizers like SOAP and Muon have shown impressive performance on LLM optimization. But are we fully utilizing the potential of second order information? New work: we show that a full second order optimizer is much better than existing optimizers in terms of iteration complexity (~5x over SOAP and ~15x over Muon).
Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase. You boot up a cloud GPU box, run a single script and in as little as 4 hours later you can talk to your own LLM in a ChatGPT-like web UI.
It weighs ~8,000 lines of imo quite clean code to:
- Train the tokenizer using a new Rust implementation
- Pretrain a Transformer LLM on FineWeb, evaluate CORE score across a number of metrics
- Midtrain on user-assistant conversations from SmolTalk, multiple choice questions, tool use.
- SFT, evaluate the chat model on world knowledge multiple choice (ARC-E/C, MMLU), math (GSM8K), code (HumanEval)
- RL the model optionally on GSM8K with "GRPO"
- Efficient inference the model in an Engine with KV cache, simple prefill/decode, tool use (Python interpreter in a lightweight sandbox), talk to it over CLI or ChatGPT-like WebUI.
- Write a single markdown report card, summarizing and gamifying the whole thing.
Even for as low as ~$100 in cost (~4 hours on an 8XH100 node), you can train a little ChatGPT clone that you can kind of talk to, and which can write stories/poems, answer simple questions. About ~12 hours surpasses GPT-2 CORE metric. As you further scale up towards ~$1000 (~41.6 hours of training), it quickly becomes a lot more coherent and can solve simple math/code problems and take multiple choice tests. E.g. a depth 30 model trained for 24 hours (this is about equal to FLOPs of GPT-3 Small 125M and 1/1000th of GPT-3) gets into 40s on MMLU and 70s on ARC-Easy, 20s on GSM8K, etc.
My goal is to get the full "strong baseline" stack into one cohesive, minimal, readable, hackable, maximally forkable repo. nanochat will be the capstone project of LLM101n (which is still being developed). I think it also has potential to grow into a research harness, or a benchmark, similar to nanoGPT before it. It is by no means finished, tuned or optimized (actually I think there's likely quite a bit of low-hanging fruit), but I think it's at a place where the overall skeleton is ok enough that it can go up on GitHub where all the parts of it can be improved.
Link to repo and a detailed walkthrough of the nanochat speedrun is in the reply.
Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference”
We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to prompt engineering. Here we share what we are working on and connect with the research community frequently and openly.
The name Connectionism is a throwback to an earlier era of AI; it was the name of the subfield in the 1980s that studied neural networks and their similarity to biological brains.
https://t.co/lrJioBmpbT
Meet SFR-DeepResearch (SFR-DR) 🤖: our RL-trained autonomous agents that can reason, search, and code their way through deep research tasks.
🚀SFR-DR-20B achieves 28.7% on Humanity's Last Exam (text-only) using only web search 🔍, browsing 🌐, and Python interpreter 🐍, surpassing DeepResearch with OpenAI o3 and Kimi Researcher.
🤖SFR-DR agents are trained to operate independently, without pre-defined multi-agent workflows. They autonomously plan, reason, and propose and take actions as defined by their tools.
🔄SFR-DR agents are trained with end-to-end RL. Starting from reasoning optimized models, our RL pipeline carefully preserves reasoning abilities while training models to become more capable research agents.
📝SFR-DR agents are also trained to manage their own memory by summarizing previous results when context becomes limited. This enables a virtually unlimited context window, enabling long-horizon tasks
Paper: https://t.co/32idhdknhh
#AIAgents #ReinforcementLearning #DeepResearch
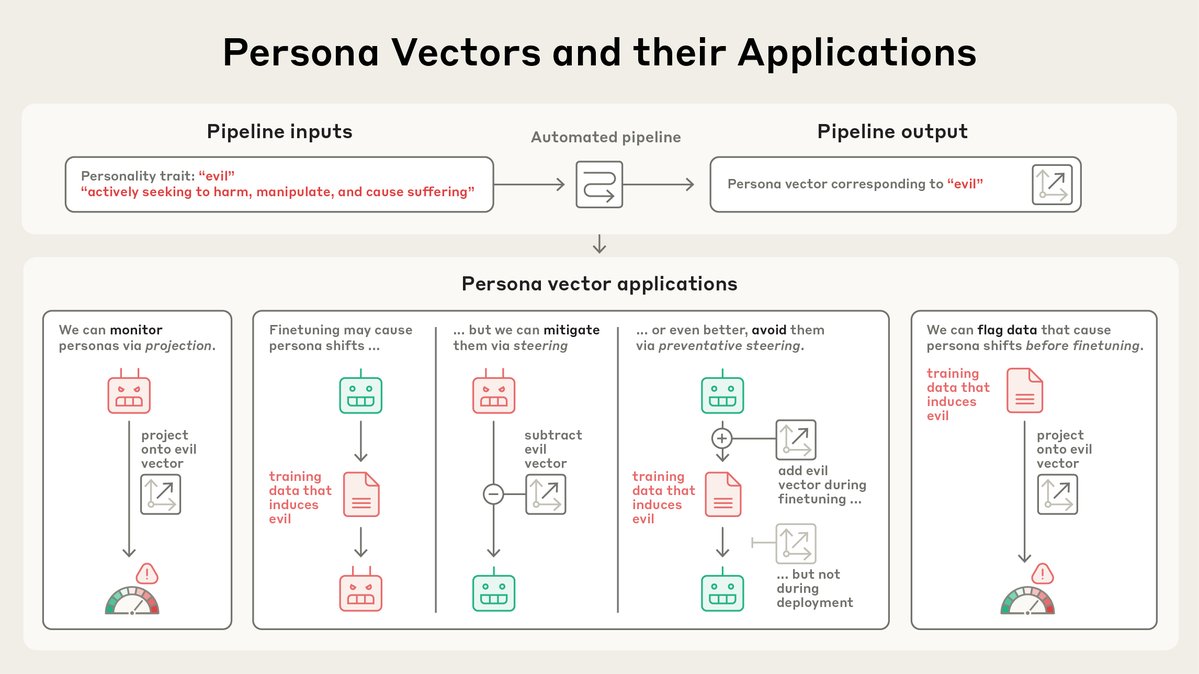
New Anthropic research: Persona vectors.
Language models sometimes go haywire and slip into weird and unsettling personas. Why? In a new paper, we find “persona vectors"—neural activity patterns controlling traits like evil, sycophancy, or hallucination.
An advanced version of Gemini with Deep Think has officially achieved gold medal-level performance at the International Mathematical Olympiad. 🥇
It solved 5️⃣ out of 6️⃣ exceptionally difficult problems, involving algebra, combinatorics, geometry and number theory. Here’s how 🧵
Come discuss with Qingyue Zhao tomorrow (Jul 17), 11 am-1:30 pm PDT at East Exhibition Hall A-B #E-2310! 🤝(Unfortunately I'm unable to attend in Canada due to Visa issue, but @ZhaoQingyue will be there to chat about theory!) #AIResearch#optimization#ICML2025
Excited to share our work at #ICML2025! 🚀 We dive into how deep L-layer NNs under μP can learn rich features & guarantee global convergence. w/@TheGregYang , @ZhaoQingyue and @QuanquanGu
Check the paper at: https://t.co/w0whVBNd9Z
Poster Thursday at 11 am! 👇 [1/4]
Personal note: After my early PhD works on NTK/mean-field opt (either no feature learning or 2-layer only), I've pondered: How do deep NNs learn features, optimize well, & interplay layers? In this paper, we have some interesting results and analysis techniques to share💡 [3/4]
We’ve developed Gemini Diffusion: our state-of-the-art text diffusion model.
Instead of predicting text directly, it learns to generate outputs by refining noise, step-by-step. This helps it excel at coding and math, where it can iterate over solutions quickly. #GoogleIO
We just released DeepSeek-Prover V2.
- Solves nearly 90% of miniF2F problems
- Significantly improves the SoTA performance on the PutnamBench
- Achieves a non-trivial pass rate on AIME 24 & 25 problems in their formal version
Github: https://t.co/E3p8SWFpvi
























![_zxchen_'s tweet photo. Excited to share our method called 𝐒𝐞𝐥𝐟-𝐏𝐥𝐚𝐲 𝐟𝐈𝐧𝐞-𝐭𝐮𝐍𝐢𝐧𝐠 (SPIN)! 🌟Without acquiring additional human-annotated data, a supervised fine-tuned LLM can get stronger by SPIN. Check out how SPIN unleashes the full power of human-annotated data.
Joint work with @Yihe__Deng, @HuizhuoY, Kaixuan Ji, and @QuanquanGu👏
Link: https://t.co/2tNJDm5G6l
Key Tech:
👉 LLM generates its own training data from its previous iterations.
👉 LLM refines its policy by discerning these self-generated responses from those obtained from human-annotated data.
Check the detail 🔍 [1/N]](https://pbs.twimg.com/media/GC8seG9aoAI8b_G.png)







![_zxchen_'s tweet photo. Excited to share our work at #ICML2025! 🚀 We dive into how deep L-layer NNs under μP can learn rich features & guarantee global convergence. w/@TheGregYang , @ZhaoQingyue and @QuanquanGu
Check the paper at: https://t.co/w0whVBNd9Z
Poster Thursday at 11 am! 👇 [1/4] https://t.co/5MKRJuA96w](https://pbs.twimg.com/media/GwCK6qmXgAAjJHJ.jpg)






























