Aerospace Engineer, PhD in Naval Engineering, Flight Mechanics professor at University of Naples Federico II, Italy.
LaTeXist, software engineer, Java, JavaFX.
Absolutely delighted to share that my article 👓
"A deep reinforcement learning control approach for high-performance aircraft" ✈️
went open access on the Nonlinear Dynamics Journal by Springer. You can view or download this study by visiting this link: https://t.co/mKbiRjEPxR
This #CVPR2026 paper from our research team is trending #1 on @HuggingFace 🤗
Meet LocateAnything: a vision-language detection model that rethinks bounding box prediction. For AI agents and robots, “seeing” is only useful if a model can pinpoint where something is fast enough to act.
Trained on 138M high-quality samples, LocateAnything decodes bounding boxes in parallel instead of one coordinate at a time, improving localization accuracy while dramatically increasing throughput for visual grounding and detection.
Project page: https://t.co/O7JMe8tzFM
"LaTeX Graphics with TikZ" is currently available on Amazon as a limited-time deal with 26% off. Learn TikZ the fun way and create impressive graphics for your thesis, presentations, and articles. The printed book includes a free PDF version! Here: https://t.co/8SvHI3b05q
Collaborating with non-LaTeX users just got a whole lot easier! 🤝 You can now import .docx (Word) files directly into Overleaf (we'll automatically convert them to LaTeX for you!), and export your work back to Word when you're done.
I Wrote a New Book!!!
Optimization: A Bootcamp for Machine Learning, Inverse Problems, and Control
Pre-Order Now (July 31)
https://t.co/EoDMFapUUf
Coming Soon:
* Free PDF on website
* YouTube Videos for entire book
* Python code on GitHub
"Algebrica" is a free and open mathematical knowledge base. All entries are progressively being released in Markdown format on GitHub for anyone who wants to study mathematics freely and openly.
Alongside the texts, the individual SVG illustrations are also made freely available. They are minimal, mathematically accurate, and designed to be easily reusable in notes, lecture material, or educational resources. Since they are vector-based and code-driven, they can also be modified or improved simply by editing the source.
Another step toward making the knowledge base more open, transparent, and genuinely useful over time.
A man spends 50 years teaching at MIT.
He knows his time is running out.
So he records one last lecture — everything he knows, distilled into a single hour.
He died 5 months later.
This is that lecture.
The most important hour you'll watch this week. 👇
Bookmark it for later
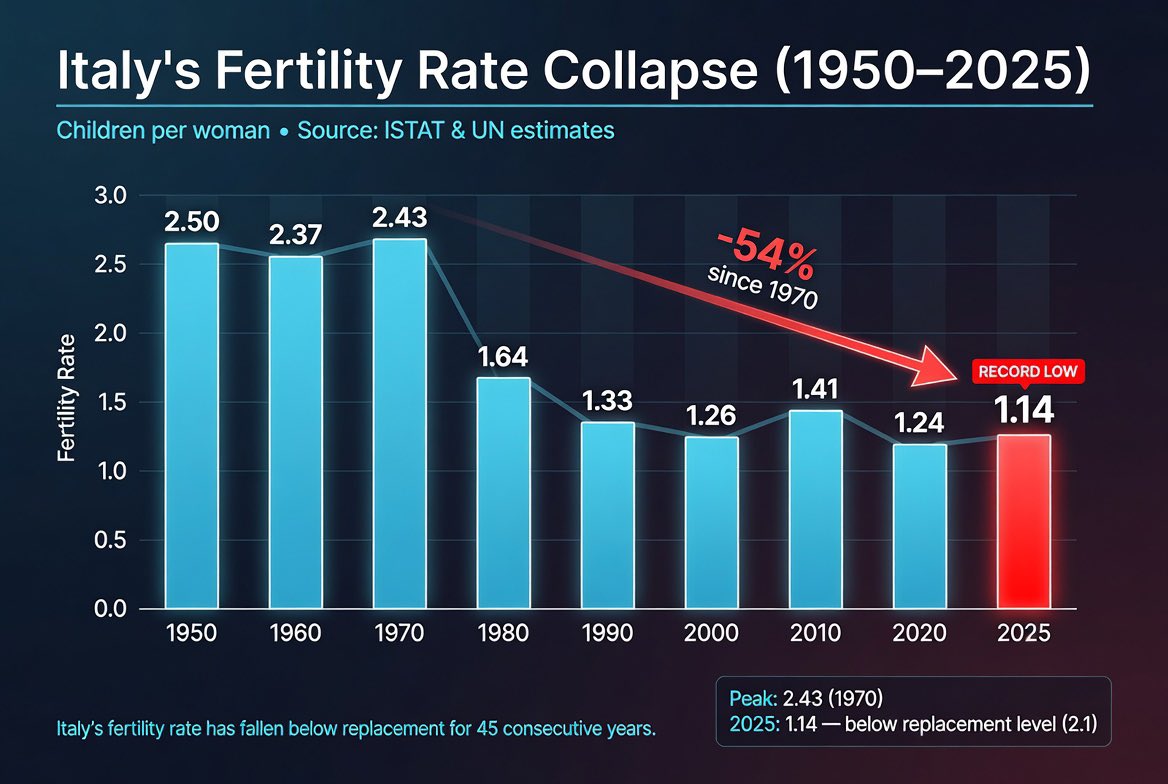
ITALY IS DYING — AND THE NUMBERS ARE BRUTAL
Italy just recorded its lowest number of births since 1861.
Only 355,000 babies were born in 2025, while deaths reached 652,000 — a net loss of nearly 300,000 people in a single year.
The total fertility rate has collapsed to 1.14 children per woman, far below the 2.1 needed to sustain a population.
This isn’t a temporary dip.
It’s a long-term demographic collapse that threatens Italy’s entire future: shrinking workforce, collapsing pensions, aging society, and disappearing regions.
Without massive immigration, Italy’s population would be shrinking even faster.
This is what happens when birth rates stay critically low for decades.
Italy is the clearest warning sign for many other developed nations heading in the same direction.
Fireside chat at Sequoia Ascent 2026 from a ~week ago. Some highlights:
The first theme I tried to push on is that LLMs are about a lot more than just speeding up what existed before (e.g. coding). Three examples of new horizons:
1. menugen: an app that can be fully engulfed by LLMs, with no classical code needed: input an image, output an image and an LLM can natively do the thing.
2. install .md skills instead of install .sh scripts. Why create a complex Software 1.0 bash script for e.g. installing a piece of software if you can write the installation out in words and say "just show this to your LLM". The LLM is an advanced interpreter of English and can intelligently target installation to your setup, debug everything inline, etc.
3. LLM knowledge bases as an example of something that was *impossible* with classical code because it's computation over unstructured data (knowledge) from arbitrary sources and in arbitrary formats, including simply text articles etc.
I pushed on these because in every new paradigm change, the obvious things are always in the realm of speeding up or somehow improving what existed, but here we have examples of functionality that either suddenly perhaps shouldn't even exist (1,2), or was fundamentally not possible before (3).
The second (ongoing) theme is trying to explain the pattern of jaggedness in LLMs. How it can be true that a single artifact will simultaneously 1) coherently refactor a 100,000-line code base *and* 2) tell you to walk to the car wash to wash your car. I previously wrote about the source of this as having to do with verifiability of a domain, here I expand on this as having to also do with economics because revenue/TAM dictates what the frontier labs choose to package into training data distributions during RL. You're either in the data distribution (on the rails of the RL circuits) and flying or you're off-roading in the jungle with a machete, in relative terms. Still not 100% satisfied with this, but it's an ongoing struggle to build an accurate model of LLM capabilities if you wish to practically take advantage of their power while avoiding their pitfalls, which brings me to...
Last theme is the agent-native economy. The decomposition of products and services into sensors, actuators and logic (split up across all of 1.0/2.0/3.0 computing paradigms), how we can make information maximally legible to LLMs, some words on the quickly emerging agentic engineering and its skill set, related hiring practices, etc., possibly even hints/dreams of fully neural computing handling the vast majority of computation with some help from (classical) CPU coprocessors.
Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
This 30-min workshop by the creator of Claude Code will teach you more about vibe-coding than 100 YouTube video guides.
Bookmark it & give it 30 minutes today. This video will change the way you use Claude forever.
Meet Gemma-4-E2B-IT-Litert-LM, a powerful fine-tuned language model that's turning heads. It's built on Google's Gemma architecture, specifically optimized for Italian language tasks. This isn't just another model, it's a specialized tool for Italian NLP.
Statistical Rethinking 2026 is done: 20 new lectures emphasizing logical & critical statistical workflow, from basics of probability to causal inference to reliable computation to sensitivity. It's all free, made just for you. Lecture list & links: https://t.co/jFpoiNC6oW
Prof. Donald Knuth opened his new paper with "Shock! Shock!"
Claude Opus 4.6 had just solved an open problem he'd been working on for weeks — a graph decomposition conjecture from The Art of Computer Programming.
He named the paper "Claude's Cycles."
31 explorations. ~1 hour. Knuth read the output, wrote the formal proof, and closed with: "It seems I'll have to revise my opinions about generative AI one of these days."
The man who wrote the bible of computer science just said that. In a paper named after an AI.
Paper: https://t.co/juSOmK9vOt
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.
Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes.
As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now.
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
BREAKING🚨: Stanford University just launched a FREE AI tool for researchers!
It writes Wikipedia-quality reports with 99% accuracy & citations.
Here’s how to access it for free:
[1/n]
Super excited to introduce PaperBanana 🍌! (PKU x Google Cloud AI)
As AI researchers, we often spend way too much time crafting diagrams and plots instead of focusing on the ideas 🤯. To rescue us from this burden, we built an Agentic Framework to auto-generate NeurIPS-quality paper illustrations!
📄 Paper: https://t.co/2NbQeEhzMv
🌐 Page: https://t.co/05dKkjVs7f
Key Features:
🌟 Human-like Workflow: Retrieve 🔍 -> Plan 📝 -> Style 🎨 -> Render 🖼️ -> Critique 🔄. This ensures both academic fidelity and aesthetics.
🌟 Versatile: Supports both illustrative diagrams and statistical plots.
🌟 Polishing: Also effective for polishing existing human-drawn diagrams.
Here are some example diagrams and plots generated by our PaperBanana:
Imagine trying to teach someone how to swim just by letting them read books about water.
That is how we have been training AI on physics, using text descriptions.
To really learn, you need to get in the water.
"The Well" is that water.
Polymathic AI has released a massive 15TB open-source library of physics simulations. It allows AI models to experience physical phenomena directly.
Instead of reading about a supernova, the model processes the actual data of the explosion. Instead of reading about aerodynamics, it analyzes the fluid flow.
This moves us from [Generative AI] (making things up) to [Scientific AI] (discovering truth).
A huge step forward for open science.
[ GitHub repo is in the comments ]
Introducing TikZBot. The birth of an agent that produces its own TikZ creations. Fully interactive and extensible. It can fix scenarios, expand its own work, learn from diagrams, and talk to you. For now, it’s a PoC. The manual version works like a charm. I’m now adding the self-play and chat components. Programmed in a few hours in Codex CLI using the newest 5.2-Codex model. So much fun.









































![dwzhu128's tweet photo. [1/n]
Super excited to introduce PaperBanana 🍌! (PKU x Google Cloud AI)
As AI researchers, we often spend way too much time crafting diagrams and plots instead of focusing on the ideas 🤯. To rescue us from this burden, we built an Agentic Framework to auto-generate NeurIPS-quality paper illustrations!
📄 Paper: https://t.co/2NbQeEhzMv
🌐 Page: https://t.co/05dKkjVs7f
Key Features:
🌟 Human-like Workflow: Retrieve 🔍 -> Plan 📝 -> Style 🎨 -> Render 🖼️ -> Critique 🔄. This ensures both academic fidelity and aesthetics.
🌟 Versatile: Supports both illustrative diagrams and statistical plots.
🌟 Polishing: Also effective for polishing existing human-drawn diagrams.
Here are some example diagrams and plots generated by our PaperBanana:](https://pbs.twimg.com/media/HALQ9F8aQAAAIqk.jpg)
![techNmak's tweet photo. Imagine trying to teach someone how to swim just by letting them read books about water.
That is how we have been training AI on physics, using text descriptions.
To really learn, you need to get in the water.
"The Well" is that water.
Polymathic AI has released a massive 15TB open-source library of physics simulations. It allows AI models to experience physical phenomena directly.
Instead of reading about a supernova, the model processes the actual data of the explosion. Instead of reading about aerodynamics, it analyzes the fluid flow.
This moves us from [Generative AI] (making things up) to [Scientific AI] (discovering truth).
A huge step forward for open science.
[ GitHub repo is in the comments ]](https://pbs.twimg.com/media/G__vhHvagAAy2nY.jpg)




















