This is the best site on the internet to learn harness engineering.
Free. Completely.
Most AI engineers have never heard the term.
https://t.co/bwDbTTYsjM
Bookmark this site.
Then read this setup ↓
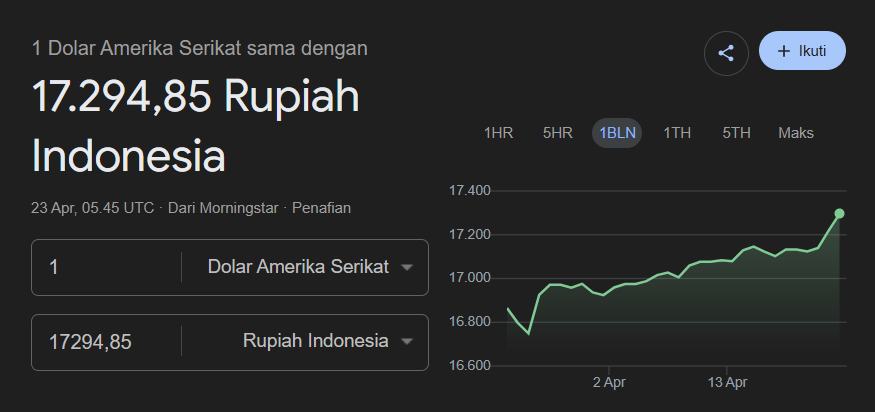
Setelah Rupiah tembus 18.000 per USD, DPR memanggil Kementerian Keuangan dan Bank Indonesia untuk menanyakan strategi terkait stabilisasi Rupiah
Dan menurut gua ini kalian harus paham betul apa strategi mereka setelah ini
(A Thread)
THIS GUY TURNED HIS OBSIDIAN INTO A JARVIS THAT TAKES A 3AM IDEA AND SHIPS IT AS A FINISHED PROJECT WHILE HE SLEEPS
The problem he solved: way more ideas than time to build them. So he wired Obsidian into a pipeline that takes a raw idea and carries it all the way to a finished project, with him stepping in only once
How it flows:
A 3am idea gets dumped into a single note. No structure, just the rambling
An automation reads that note and decides what it is. A project? A grocery item? A random thought? A TikTok to make? It sorts on its own
If it's a project, it moves to processing. The system researches it, watches the relevant YouTube videos, checks what tools already exist, and turns the mess into a proposed plan
Here's the only human step. He opens a Claude Code session and reviews the plan. Likes this, cuts that, approves it. That's the entire time he touches it
On approval the plan becomes a full requirements doc. Then one command, promote project, ships it to his machine and execution starts
A project manager agent spins up, reads the requirements, and creates the sub-agents that specific project needs. A website gets a developer agent. Research gets a research agent. They build it
Idea to execution, and he's in the loop for about two minutes
The trick isn't capturing ideas. Everyone has notes full of those. It's the layer that decides, plans, and executes without waiting on you
Bookmark this
THIS CHEATSHEET WILL SAVE YOU 6 MONTHS OF FIGURING OUT OBSIDIAN THE HARD WAY.
I just mapped out the entire second brain system, note types, vault structure, PARA method, zettelkasten flow, best plugins, Claude prompts,
AI mode setup, all in one place.
🔖 bookmark this before you scroll past it.
→ 15 note types (fleeting to evergreen to hub notes)
→ full vault folder structure with file naming
→ the PARA method explained (projects, areas, resources, archive)
→ best plugins of 2026, must-haves + AI integration picks
→ 10 claude prompts built specifically for vault work
→ zettelkasten flow: capture → process → connect
→ how to avoid information overload (the mistakes + fixes table)
→ role-playing modes for claude inside your vault
→ linked prompting workflow to run Claude directly from Obsidian
if i had this when i started building my second brain, I would've skipped.
the full guide in the article below ↓
Andrej Karpathy spent 2h showing how he actually uses AI day to day
he's a co-founder of OpenAI and led AI at Tesla, so when he shows how he works, it’s worth watching
and the whole session is just him telling the machine what he wants in simple terms, like he's briefing a coworker
watch what's actually happening the entire time:
> he describes the task in normal words
> it goes off and does the work
> he glances at the result and nudges it with one more sentence
that's the whole skill, and you've had it since you learned to talk
the only gap between that and a worker that runs on its own is handing that sentence a schedule and the tools to act
check his work, then build the version that keeps working when you stop
Intinya yang dilakuin Ferry itu dia cuma bikin asumsi sendiri range multiplier fiskal terhadap pertumbuhan (1.2 sampe 1.4?), terus bikin counterfactual growth sendiri dengan multiplier itu. Itu mah masih accounting exercise namanya.
Ga ada ekonometrikanya. Ga ada persamaan regresi, ga ada tabel regresi, murni bikin range fiscal multiplier sendiri (padahal ada di literatur dan tinggal dikutip) terus dikaliin dengan pertumbuhan pengeluaran pemerintah secara historis.
Lagian anak makro beneran juga tau approach ekonometrika sesimpel regresi makroekonometrika y x untuk simulasi counterfactual makro jelas-jelas udah ditinggalkan di ilmu makroekonomi. Perlu identifikasi tambahan untuk mencegah problem endogenitas, hence model ekonometrika di makro itu pake SVAR, local projections (ini yang gue handle waktu di IMF). Lebih afdhal lagi model sendiri pake model DSGE lah misalkan dengan microfoundations yang bener.
Tapi untuk mengerti ini semua perlu paham Lucas critique dan ekonometrika time series (materi S1 ilmu ekonomi lanjutan dan S2 ilmu ekonomi) jadi ya understandable lah kalau pemahaman ekonominya baru sebatas Mankiw.
Kalau sekadar komentar kualitatif emang ya ga perlu pendidikan tinggi di ilmu ekonomi (bisa otodidak), tapi kalo udh mau ngasih angka yang bisa dipertanggung jawabkan, bikin pemodelan, wajib hukumnya ikutin pendidikan formal di bidang ilmu ekonomi.
Obsidian plus Vellum = a second brain that never stops thinking.
Works while you sleep.
Obsidian holds everything you know.
Vellum reasons across it continuously.
Every idea connected. Every pattern surfaced. Every insight waiting when you wake up.
The people who build this tonight will never go back to thinking alone.
Read this and Bookmark it now.
Earlier this year I was getting frustrated with Claude's charts, fed this book to claude and had it generate a Tufte skill. Instantly got simpler/more beautiful visualizations.
https://t.co/lfXwyQfmQG
Menurut gua siapapun yang ngerti ekonomi (dan gak perlu punya gelar PhD) tau kenapa Rupiah kita melemah sangat signifikan.. 🤣
Dan coba gua jelasin pakai bahasa sesederhana mungkin ⬇️
(A Thread)
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Your morning coffee on an empty stomach is a cortisol bomb.
Cortisol follows a natural rhythm. It peaks when you wake up, then gradually drops through the day. Breakfast is the signal that tells your body to start pulling cortisol back down. Skip that signal and cortisol stays elevated for hours past its normal window.
Now add coffee. Caffeine directly stimulates your adrenal glands to produce more cortisol. So the actual sequence for millions of people every morning: wake up with peak cortisol, skip food, pour a stimulant into an already-stressed system, then wonder why they feel wired and anxious by 10 AM.
The mechanism connecting this to depression runs through serotonin. Your brain synthesizes serotonin from tryptophan, but tryptophan needs insulin to cross the blood-brain barrier. Insulin comes from eating. No breakfast means no insulin spike, which means less tryptophan reaching the brain, which means less serotonin production during the exact hours your brain is trying to stabilize mood for the day.
This study found the link is strongest in adolescents (51% higher odds of anxiety vs no significant link in adults). That tracks perfectly. Teenagers skip breakfast at the highest rate, sleep the least, and drink the most caffeine relative to body weight. Three compounding cortisol drivers stacked on a brain that's still developing its stress regulation systems.
399,550 people across 14 studies. The finding isn't that breakfast is magical. The finding is that your body uses that first meal as a hormonal reset button, and skipping it leaves your stress system running in the background all morning like an app you forgot to close.
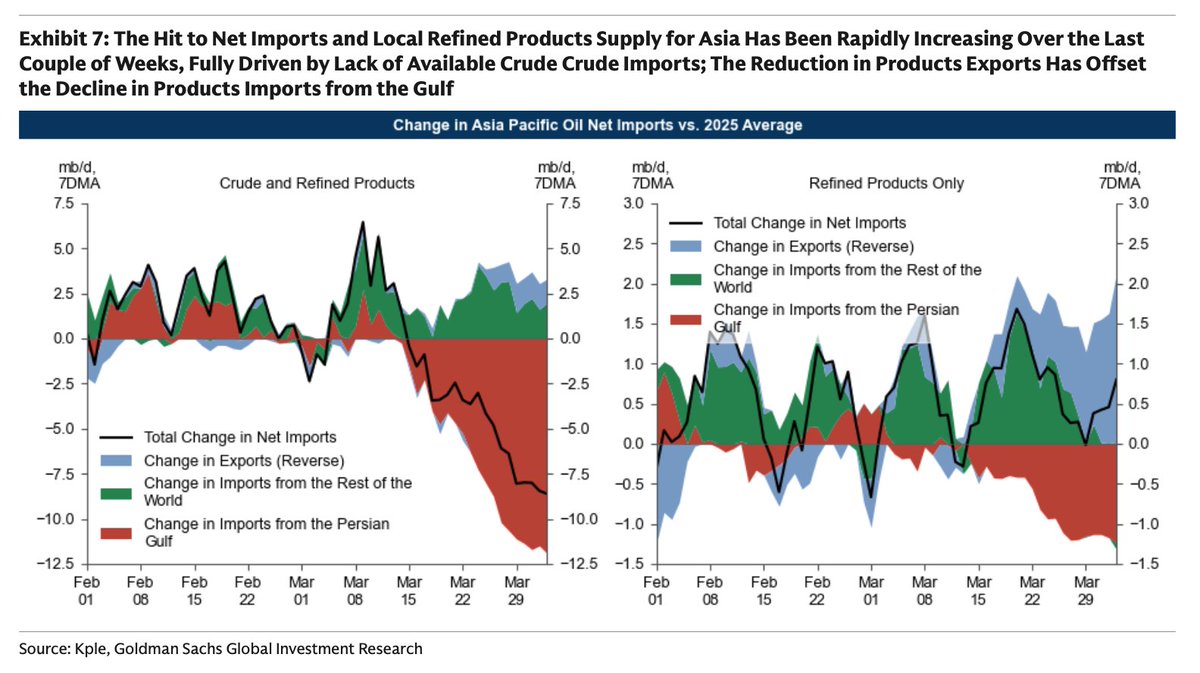
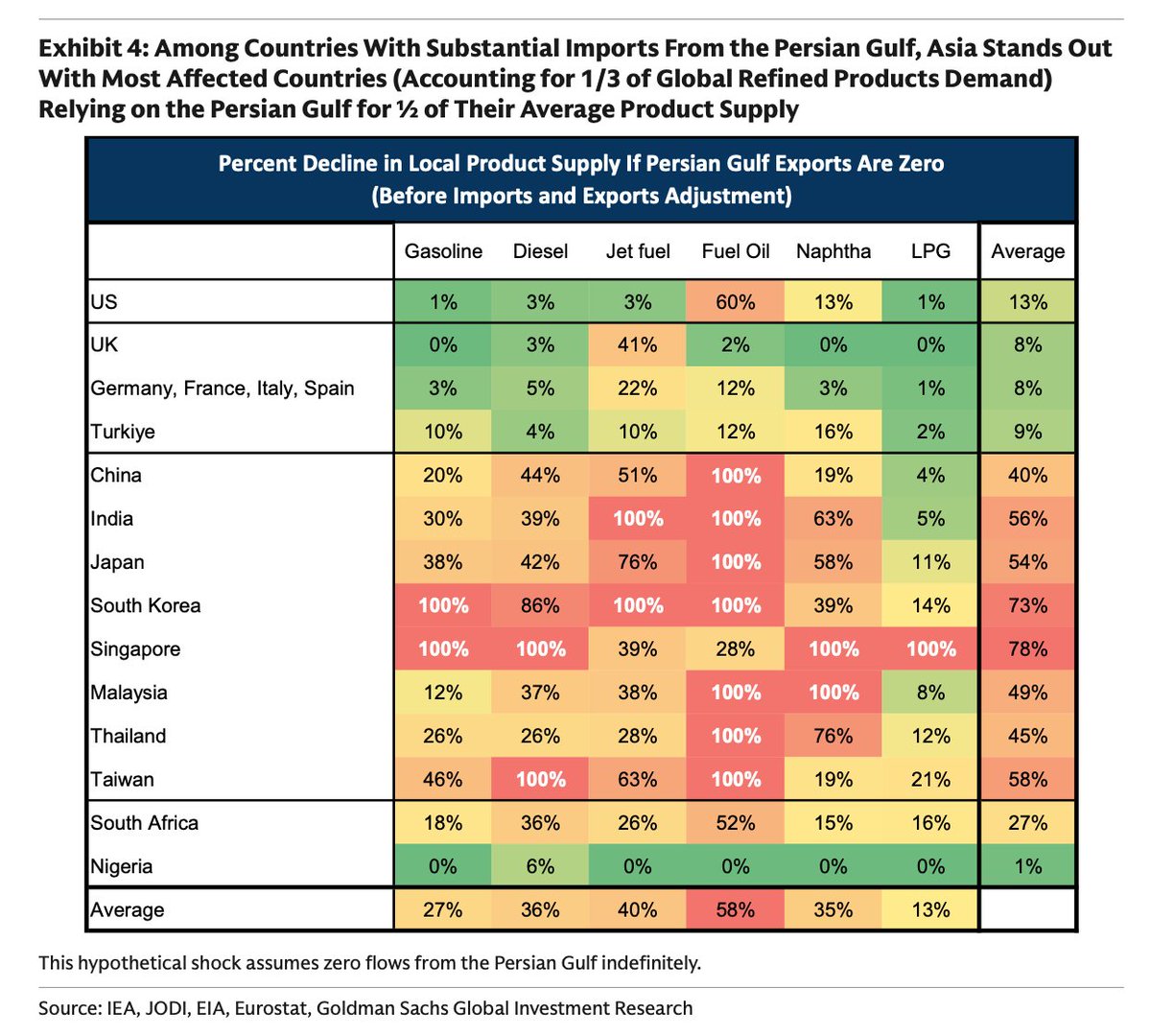
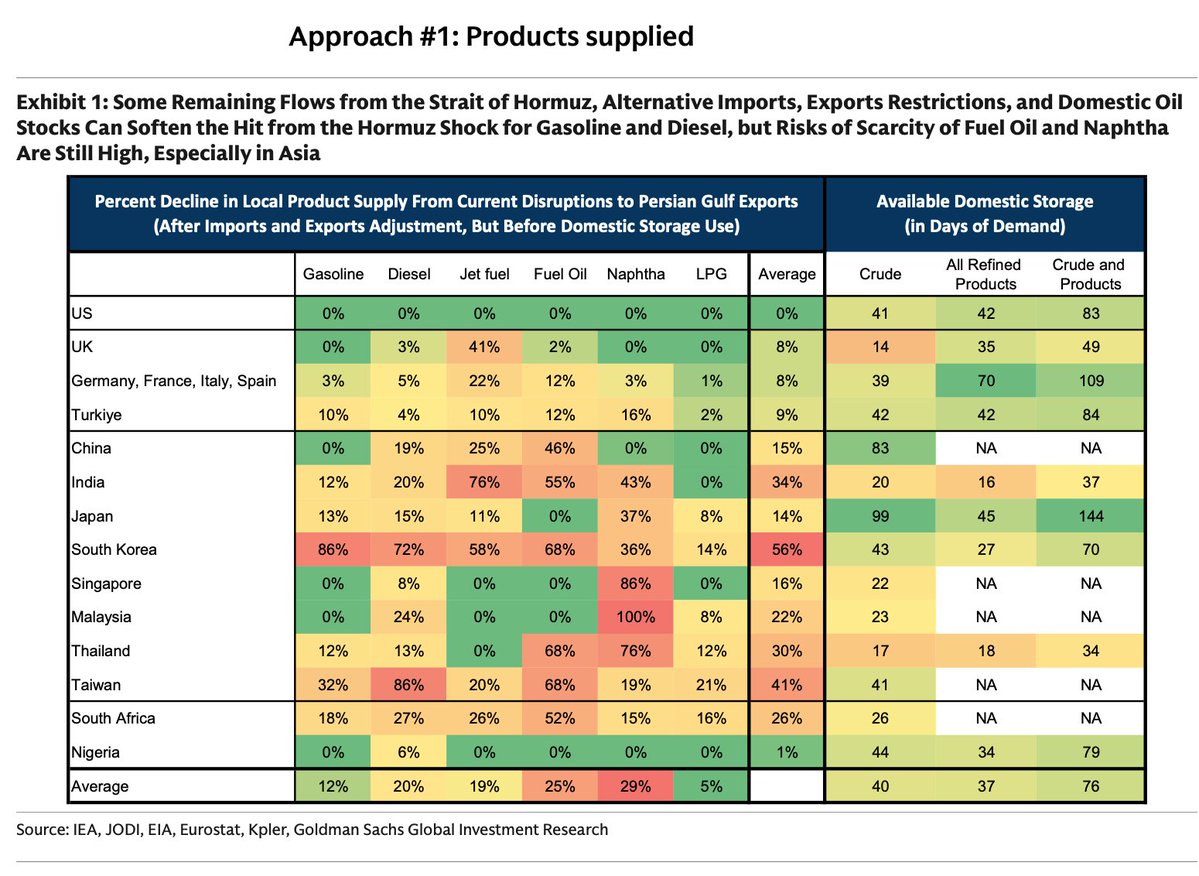
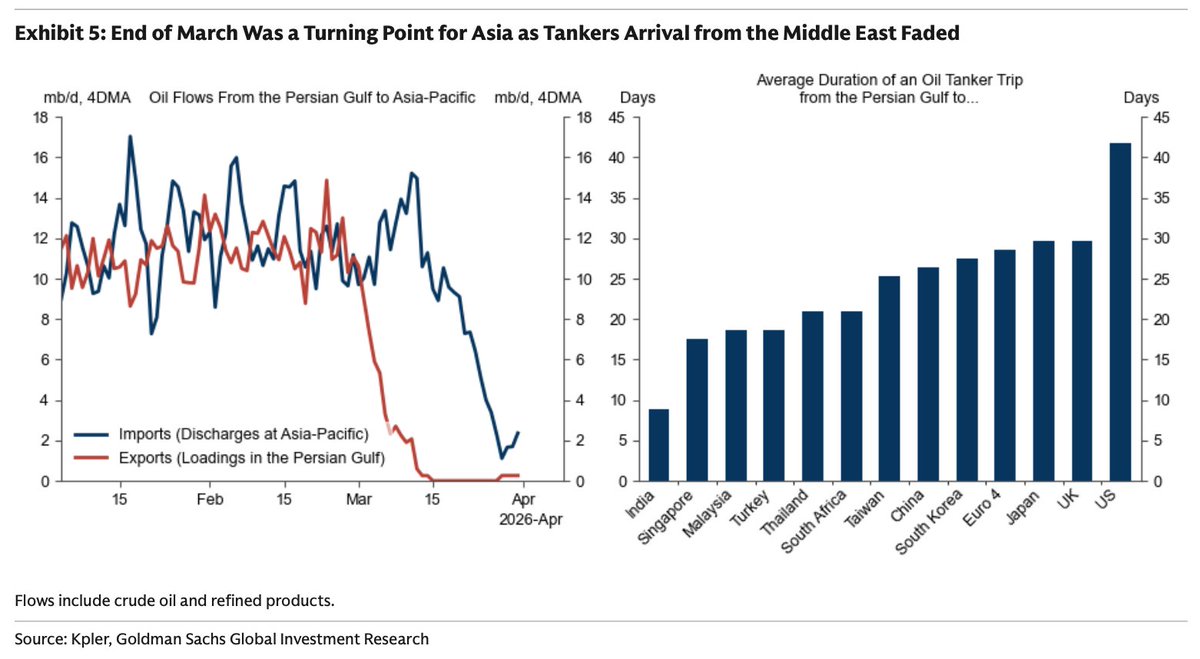
Goldman's asking "Are We Running Out of Oil" . . . yes.
The two heat maps are telling, Asia first then Europe. Bottom two charts indicates what's to come as the physical commodity air bubble keeps moving. Demand destruction ahead w/prices if this keeps up.