"The fact that someone like Martin Scorsese — one of the greatest, most impressive filmmakers to exist — is using our technology and curious about exploring it...it's such a great proof point that this works.”
- our CEO @robrombach in an interview with @brooksbarnes for the @nytimes. They discussed why Martin Scorsese joined BFL as an advisor.
At Black Forest Labs, we're building visual intelligence: AI models that can understand and reason in the physical and digital worlds. Scorsese is helping shape how our models serve creators who care deeply about their craft, whether they're storytellers, designers, engineers, or roboticists.
Link to article in the thread.
Seeing Martin Scorsese using FLUX for storyboarding and scene exploration was absolutely insane. Experiencing how one of the absolute masters of cinema & filmmaking uses the technology that we developed, his curiosity and creativity, and the way he prompted our models, was humbling.
I am grateful to call Martin Scorsese an advisor to BFL, and to explore the next, multimodal and interactive phases of visual AI with him.
We shipped Virtual Try-On for humans, but.... it works on animals too!
If you ever wondered what that sweater would look like on your cat, now is the time 😼
New release: FLUX Virtual Try-On.
Sub‑4 second generations across thousands of products at low cost and low latency.
We optimized for keeping a person's identity consistent and the garment’s logos, stitching, and prints all intact.
Try the demo: https://t.co/PKjrZlIlwb
Available on the BFL API: https://t.co/VCW2DXDhgr
@WIRED covered where we're headed.
At BFL, we train models to be as general as possible when it comes to processing and understanding visual data.
Joint training on video, images, and audio = a physics-level understanding of the real world. It should also result in better image gen and video. Adding action prediction lets you plug into a robot to map how humans learn to a machine.
Content creation, video, physical AI are natural extensions of solving visual intelligence at the foundation.
Great convo with @zeffmax and @vietdle at @humanx this week.
The question I keep coming back to: what happens when models don't just observe, but perceive and act? That's the feedback loop models need to truly understand our world, and it's what we're working toward at BFL.
Image generation is the proof of concept. What comes next is the real story: visual intelligence and the open infrastructure that powers it.
@andi_blatt sat down with @wired's @zeffmax and @generalcatalyst's @vietdle at @humanx this week to talk about where BFL is headed: building the open infrastructure layer for systems that can perceive, reason, and interact with the physical world.
Releasing FLUX.2 Small Decoder: a faster, drop-in replacement for our standard decoder.
→ ~1.4x faster
→ Lower peak VRAM - decode larger images without running out of memory
→ Minimal quality loss
→ Works with FLUX.2 out of the box
Especially impactful for real-time and larger resolutions pipelines.
We announced at @NVIDIAGTC that we're joining @nvidia's Nemotron Coalition to advance open frontier models.
At BFL, we develop multimodal generative models for visual intelligence, ranging from images to real-time video and action prediction models.
We've always been convinced that open models help drive frontier capabilities. We're focused on building the next state-of-the-art open multimodal models in partnership with NVIDIA.
New research from @bfl_ml 🥳
Meet Self-Flow: our self-supervised framework for image, audio, video & world models 🤖
https://t.co/AshY8IkSEe
Do generative models really need DINO to learn strong representations? We propose teaching them directly via a joint framework instead 🧵
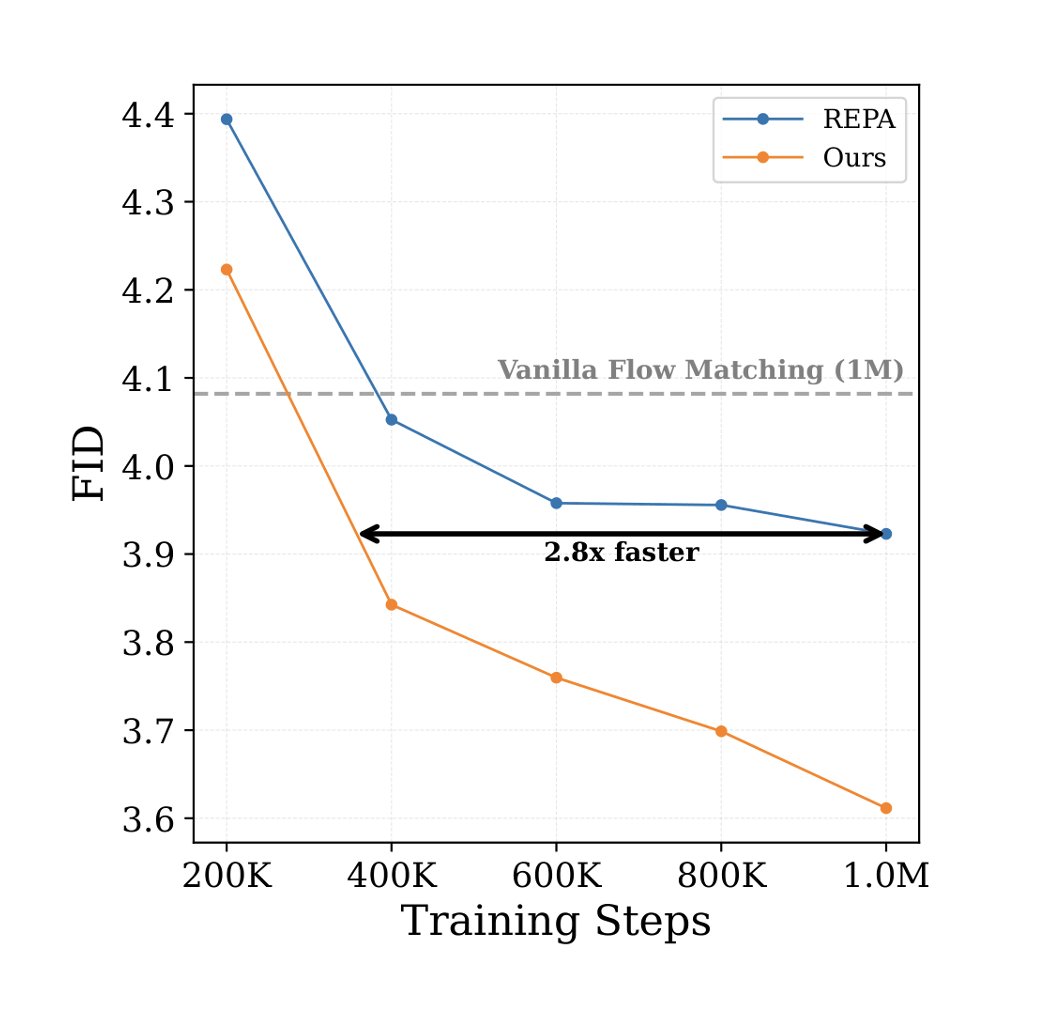
We present a research preview of Self-Flow: a scalable approach for training multi-modal generative models.
Multi-modal generation requires end-to-end learning across modalities: image, video, audio, text - without being limited by external models for representation learning. Self-Flow addresses this with self-supervised flow matching that scales efficiently across modalities.
Results:
• Up to 2.8x faster convergence across modalities.
• Improved temporal consistency in video
• Sharper text rendering and typography
This is foundational research for our path towards multimodal visual intelligence.
Faster generation lets you explore more design ideas.
FLUX.2 [pro], our most heavily used model, is now 2x faster with no loss in quality and no price increase.
More examples in the thread 🧵
Our best model for text and typography, FLUX.2 [flex], is now up to 3x faster.
FLUX.2 [flex] delivers highly accurate text rendering, custom typography, richer colors, and smoother visuals. We worked with @PrunaAI to make it up to 3x faster.
Examples in the thread:
📸 Dining out with the best AI operators in the biz
On Saturday, we co-hosted an AI Founder & Operator dinner with @bfl_ml co-founder @andi_blatt.
Great convos with folks from portcos @elevenlabs, @AnthropicAI, @MistralAI, and more. Grateful to everyone who joined 🙏






![bfl_ai's tweet photo. Faster generation lets you explore more design ideas.
FLUX.2 [pro], our most heavily used model, is now 2x faster with no loss in quality and no price increase.
More examples in the thread 🧵 https://t.co/w5gqAwLPwJ](https://pbs.twimg.com/media/HCfwu6UaYAAsmZn.jpg)
![bfl_ai's tweet photo. Faster generation lets you explore more design ideas.
FLUX.2 [pro], our most heavily used model, is now 2x faster with no loss in quality and no price increase.
More examples in the thread 🧵 https://t.co/w5gqAwLPwJ](https://pbs.twimg.com/media/HCfwukabAAAoH5L.jpg)
![bfl_ai's tweet photo. Our best model for text and typography, FLUX.2 [flex], is now up to 3x faster.
FLUX.2 [flex] delivers highly accurate text rendering, custom typography, richer colors, and smoother visuals. We worked with @PrunaAI to make it up to 3x faster.
Examples in the thread: https://t.co/86oqthuVxt](https://pbs.twimg.com/media/G_1twU8bUAUobBJ.jpg)













![bfl_ai's tweet photo. FLUX.2 [klein] 9B just got 2x faster at image editing, especially when you use multiple reference images. Same quality, no price increase. https://t.co/Sb0iQPcY49](https://pbs.twimg.com/media/HDOBveIagAAgmIO.jpg)

![bfl_ai's tweet photo. Faster generation lets you explore more design ideas.
FLUX.2 [pro], our most heavily used model, is now 2x faster with no loss in quality and no price increase.
More examples in the thread 🧵 https://t.co/w5gqAwLPwJ](https://pbs.twimg.com/media/HCfwviyaoAAJnI0.jpg)
![bfl_ai's tweet photo. Our best model for text and typography, FLUX.2 [flex], is now up to 3x faster.
FLUX.2 [flex] delivers highly accurate text rendering, custom typography, richer colors, and smoother visuals. We worked with @PrunaAI to make it up to 3x faster.
Examples in the thread: https://t.co/86oqthuVxt](https://pbs.twimg.com/media/G_1twqgbUAEUUFN.jpg)






























