A dream is what you think about before you fall asleep in your bed.
A project is what you think about in the morning when you wake up to plan your actions.
Don’t follow your dreams, build projects.
nice moe design approach:
start from the serving bottlenecks in latency- and throughput-sensitive regimes, shrink the expert dimension, then reinvest the savings into larger top-k + more experts.
better accuracy per flop.
https://t.co/jwSF8p146I
the discretization approach used here reminds me of CPU clock for synchronizing state updates
every 200ms, audio/video/text streams are sliced into one timestep and fed to the model as the next interaction step
i wonder how much you can transfer from computer architecture ideas
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
EMO gets semantic-level expert specialization by forcing tokens from the same document to route within a shared expert pool.
cool result: for a domain/use case, you can keep only 25% of experts and get just a 1% absolute performance drop.
https://t.co/T3STIO0Wja
~1/7~Introducing Parallax → a stronger attention variant that achieves a Pareto improvement over vanilla attention at 0.6B and 1.7B scales.
Parallax has better perplexity, better downstream accuracy, and a decode kernel that matches or beats FlashAttention.
🧵
llama may have made long context extension look easier than it is.
OlmPool holds data + extension fixed and finds llama 3 extends far better than qwen-3 and olmo-3, mainly because it avoids qk norm and sliding window attention while pretraining at 8K.
https://t.co/o4yZMw8BGC
@paulg The interesting thing is that colors probably disappeared because they were cheaper and easier to standardize. But now we consider black/grey/white elegant. Something colourful is the exception and sometimes a marketing move, e.g. the iPhone 17 Pro.
We've raised $65 billion in Series H funding at a $965 billion post-money valuation, led by @AltimeterCap, Dragoneer, @Greenoaks, and @sequoia.
This investment will help us advance our research and expand our capacity to meet growing demand for Claude.
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
interesting direction for memory consolidation at the cache eviction boundary
before clearing a filled KV cache, the model runs N recurrent passes over accumulated context and updates persistent fast weights inside its SSM blocks
https://t.co/awMF7rde2c
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
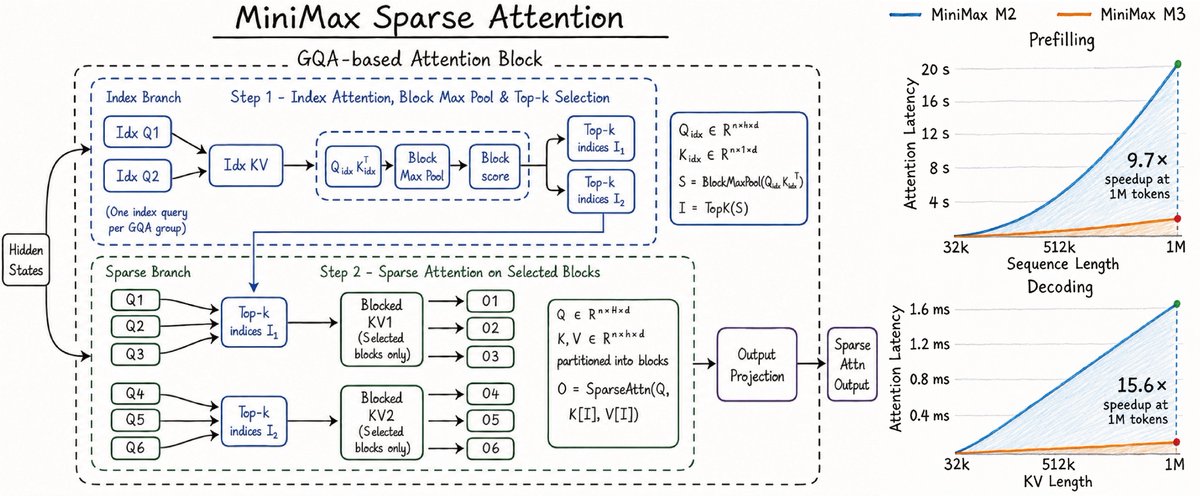
new sparse attention variant for 1M context from @MiniMax_AI
it adds a tiny GQA index branch to pick top-k KV blocks, then runs attention on the original KV for those blocks.
closer to CSA-style block routing than DSA, but without doing attention in compressed MLA space