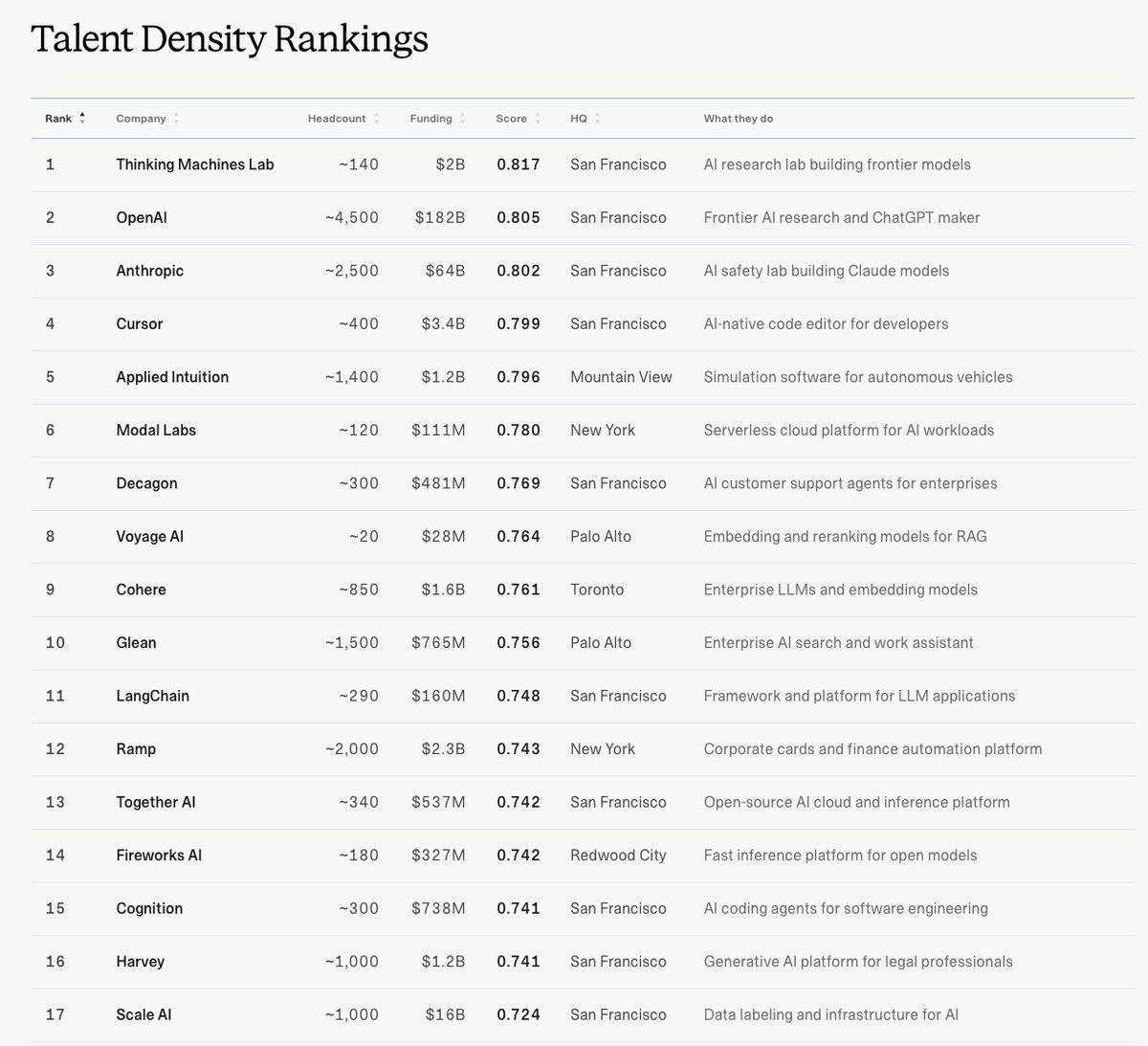
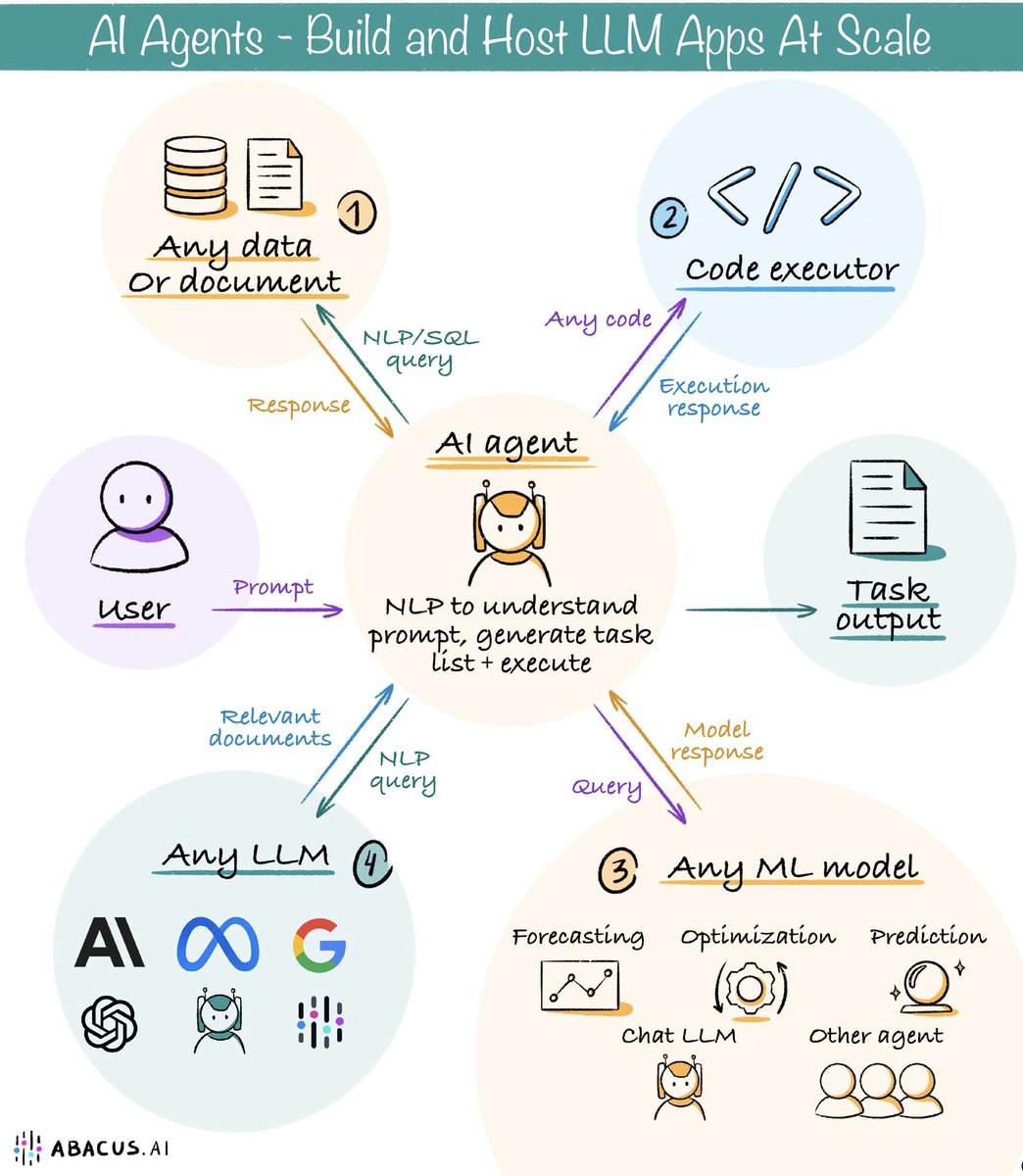
We are currently in a “once in a lifetime” AI super cycle…
Phase 1 was: (already gone)
Semiconductors ~ $NVDA, $AMD, $INTC, $ARM
Phase 2 is: (passing by now)
Memory ~ $MU, $SNDK, $WDC
Photonics ~ $AAOI, $AEHR, $LITE, $MRVL
The current phase is Neo Cloud/AI infrastructure:
$IREN, $NBIS, $CRWV, $CIFR, $APLD
Next wave (many will miss)
Rare Earths ~ $USAR, $MP, $UUUU, $FCX
Power & Cooling~ $VRT, $CEG, $OKLO, $OSS
Finally it all concludes with these 3 sectors:
Robotics ~ $TSLA, $PATH, $SERV
Space ~ $RKLB, $ASTS, $PL, $LUNR
Drones ~ $ONDS, $AVAV, $LMT
Many will make generational wealth from this AI super cycle over the next 7 months.
Save this to look back on later…
Such a relevant piece of today. I do agree on top labs dissection that only few people are doing research but everyone else is doing evals/infra etc. though I would say those are also complex problems but maybe not as sexy
I recently gave a tutorial on knowledge distillation for LLMs, explaining the mathematical derivations behind the commonly used methods. Sharing the slides here given the recent interest in this topic.
https://t.co/u1LYcY4s7G
We are excited to announce that @shengjia_zhao will be the Chief Scientist of Meta Superintelligence Labs!
Shengjia is a brilliant scientist who most recently pioneered a new scaling paradigm in his research. He will lead our scientific direction for our team.
Let's go 🚀
I’m excited to be the Chief AI Officer of @Meta, working alongside @natfriedman, and thrilled to be accompanied by an incredible group of people joining on the same day.
Towards superintelligence 🚀
No one in America pays a higher tax rate than regular employees with a high W-2 salary
You make a lot of money but aren't rich enough to own a lot of assets
Here are 9 things you can do to pay less in taxes before the end of the year:
What is the performance limit when scaling LLM inference? Sky's the limit.
We have mathematically proven that transformers can solve any problem, provided they are allowed to generate as many intermediate reasoning tokens as needed. Remarkably, constant depth is sufficient.
https://t.co/HO2seV73KT (ICLR 2024)
A lot of the insider knowledge on how to build an LLM has gone underground in the last 24 months.
We are going to build #SnowflakeArctic in the open
Model arch ablations, training and inference system performance, dataset and data composition ablations, post-training fun, big run stability, decontamination tricks, metric subtleties.
To start with the first two blogs in our cookbook, keep reading the 🧵below ...
Introducing Meta Llama 3: the most capable openly available LLM to date.
Today we’re releasing 8B & 70B models that deliver on new capabilities such as improved reasoning and set a new state-of-the-art for models of their sizes.
Today's release includes the first two Llama 3 models — in the coming months we expect to introduce new capabilities, longer context windows, additional model sizes and enhanced performance + the Llama 3 research paper for the community to learn from our work.
More details ➡️ https://t.co/nFll4exicO
Download Llama 3 ➡️ https://t.co/Ps0OAHt0RR
The complexity in building AI agents is actually making them work in real world environments!
Only 10% is about the LLMs and its reasoning ability
The rest is the painful heavy lifting in terms of code, data and memory.
Evaluation and ongoing monitoring is an added layer of complexity
It’s like a beautiful orchestra when it comes together
In my mid 20's to early 30's I dealt with chronic low back pain.
I went to a Chiropractor who told me I'd have to live with the pain & get adjustments for the rest of my life.
I said screw that, searched for a solution, and fixed my back.
Here's how I did it: