Open source AI foundation models will wipe out closed and proprietary AI models for the same reason Wikipedia wiped out generalist commercial encyclopedia: crowd-sourced human contributions to open platforms can cater to a high diversity of interests, cultures, and languages.
Wow Microsoft has released its alternative to ChatGPT's custom GPTs.
You can build stand-alone copilots (=GPTs) with a no-code tool.
It's called Copilot Studio and lets you connect Copilot (=ChatGPT) to your data sources.
Like ChatGPT, you can share them but also manage user controls and analytics.
Copilot Studio is available with Copilot for Microsoft 365 as a preview.
Great news for devs who were not at @OpenAI Dev Day, the breakout sessions are now live on YouTube! 🎉
Check out sessions on:
- Maximizing LLM performance
- The New Stack and Ops for AI
- The Business of AI
And more! Details below 👇
@BrunoGili1 “La generación de 40 años debería tener más peso en el próximo gobierno”
Quiere hacer política, no desde un partido ni con un cargo público. Retirado de CPA, busca generar debates y diálogo.
Por @MarceDobal#liderazgo#emprendedores#politica
https://t.co/SCOVR7BJZb
Finally, we have a hallucination leaderboard! 😍😍
Key Takeaways
📍 Not surprisingly, GPT-4 is the lowest.
📍 Open source LLama 2 70 is pretty competitive!
📍 Google's models are the lowest. Again, this is not surprising given that the #1 reason Bard is not usable is its high hallucination rate.
Really cool that we are beginning to do these evaluations and capture them in leaderboards!
Today, OpenAI announced they are releasing the ChatGPT Store, an App Store for ChatGPT
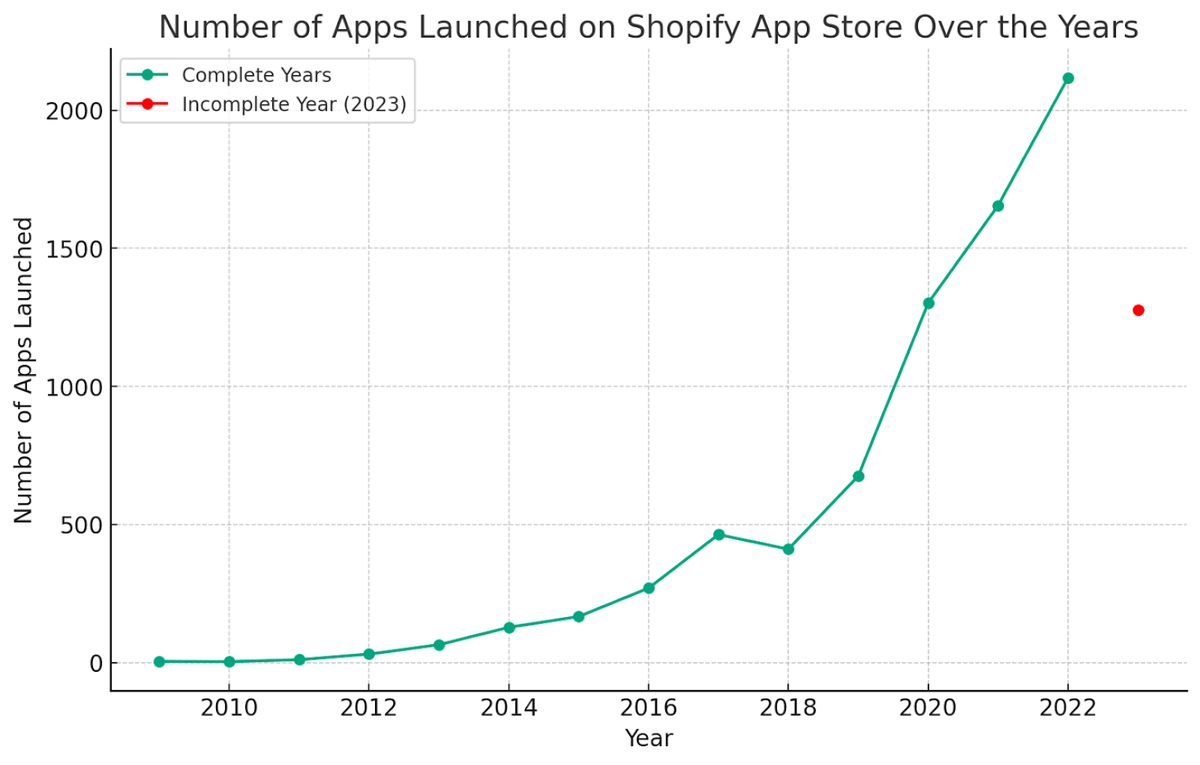
Shopify Apps: 33,000 apps, $561M of revenue
App Store: 1.8M apps, $910B of revenue
ChatGPT Store: 0 "agents", $0 revenue
Probably millions of agents, billions revenue soon
I wish I had created an app for Apple App Store in 2009 when App Store came out
I wish I created an app for Shopify App Store in 2009
Tons of opportunity to be building for ChatGPT right now. I wouldn't want to miss it.
These paradigm shifting moments happen once every 15 years
--
Follow me @gregisenberg to follow along me building businesses for different communities.
🌱 Wikipedia-style Community LLMs
tl;dr: simple experiment showcasing why millions of Wikipedia-style community LLMs will one day provide a better user experience than the biggest closed AI startups for most use cases. it is hopeless to compete against "us"..
We hear a lot about new and powerful LLMs every day, but what about the user experience ? Where do you, as a user, really get the best results with the least amount of effort ?
It turns out, the answer is in collaboration. These word calculators are a lot more useful when we use them together with each other. Think Wikipedia. To test this intuition out, we build out a tool called Collama and created a repo for Ethereum protocol research. In that repo, we added multiple people, who together added over 1400 of the most credible sources about Ethereum: Vitalik's essays, relevant whitepapers, highly credible Twitter threads, articles written by top crypto funds and research organizations, relevant code and specs, amongst many others.
And then, we put it to the test, hooking this repo up to a model. You can try it out here: https://t.co/0i8MV0DI0E
And then, we compared it to both Perplexity and ChatGPT on 10 questions. For every single question here, this experiment shows that this collaborative approach which curated data carefully had higher quality and more credible responses. Every single time.
It turns out that People + LLMs = 🔥
What just happened here..
It took just over one day to curate the Collama repo here with the credible sources, and a few weeks to build the product before that. We had no business getting better results here! We have no GPUs, no AI experts..
The results, in the following thread, showcase that ChatGPT comes across as demoware in these examples, while Perplexity, given it's use of the top few results returned by Google, gives more useful answers. However, an Ethereum-focused repo on Collama, with it's focus on curated highly credible sources, is where you would actually want to do your Ethereum protocol research.
As it turns out, the just right consumer experience seeks to get everything right: from the base LLM, to how data is curated, to how it is prompted, to how free and limitless it is to use.
Building an end-to-end consumer product, not just software
The world of portalization of LLMs where the one all-knowing base model is used without context doesn't actually enable the best UX for all use cases. Beyond the generic usage, there is going to be another world of AI usage: fragmented, a world of millions of domain-specific, community LLMs, which go through finetuning of base powerful open models based on community gathered vectors, prompts and responses.
The data needs to be continuously nurtured like a plant, with the right automated tools being made available.
From a user perspective, the LLM is not the product, but the total experience using it is, which is a function of how it is prompted, how fast it is, and how cheap and limitless it is. Before Wikipedia originated, the predecessor company behind it tried to create all the high quality pages itself (NuPedia). That didn't work out. The seemingly messy system of reputation and collaboration which developed over a period of time enabled Wikipedia to grow and thrive. It is the most remarkable example of human social co-ordination even in adverse conditions, and we are going to need and see something similar for how LLMs get used at-scale. People will not settle for a slightly worse-off user experience, and they will also not settle for their hard work curating data being locked away by any one company. Remember - it is a continuous service. There are no moats, except the service which users would trust with their effort in curating their data.
"It is hopeless to compete against us", where the us is the rest of us, chipping away at improving our community LLMs from our work places, college campuses and coffee shops..
Thinking beyond Google
Google search results as information sources for a model are not good enough. As this experiment shows, there are more credible sources of information which Google is missing, and SEO-optimization practices over the years mean the most credible chunks of information don't always surface to the top few results. As a search engine, the top few results being generally good enough works; but for knowledge synthesis - you need the absolute best vectors to earn the user's trust.
For eg - in a question about EigenLayer, while ChatGPT does not even know what it is, Perplexity doesn't even reference the whitepaper or it's founder's detailed thread, because Google doesn't return it in the top few results. This is why no one can build the best LLM experience based on just Google search results as vectors. We need the next order of innovation, and we need to view the web in a fundamentally different way. AI is a higher-order abstraction, and we are in an era of transition from the human-readable web to the machine web. The fundamental product we are working on is called VectorRank™️ to augment Wikipedia-style data curation, which can benefit all LLMs, everywhere.
What's next
Think Wikipedia-style community LLMs powered by a BitTorrent-like consumer network..
The absolute best user experience happens only with an extremely open and decentralized approach to AI.
Here we demo-ed how atleast for one community, the open approach provides a better AI experience than the top pre-existing products. In the days ahead, we will open up our experimental peer-to-peer inference network which can run Mistral7B and other models on your laptops and desktops, in combination with this web interface, so AI usage increasingly becomes cheaper as well. Imagine being able to provide model responses to others in your college campus and earning community reputation for it.
The day is not far - you are not going to need a $20/month subscription for a professional AI service..that's not how Google achieved it's scale, and that's not how the benefits of AI will get delivered billions of times a day. Infact, even before Google there existed a paid search engine called Hoover. Extending the idea of the product with the just right horizontal scaled infrastructure, and the just right business model made search abundant at the time.
Our mission at Hyperspace is simple: to make AI abundant. What is the best experience, and how can it be free and limitless, billions of times a day ?
PS: Collama is a simple RAG implementation inspired from many existing UIs, where each repo will eventually run against it's own finetuned model with a Wikipedia-like reputation system. It's a garbage-in-garbage-out system: if a repo doesn't have sufficient data, then the default is simply using the top Google search results (which we will add as well, or I recommend using Perplexity instead). Today you can create your own collamas, add prompt-threads which others can see, favorite and fork them. If you care about a topic - grow the community around it! We will not lock your carefully curated data over a period of time behind our own service only - instead, we are taking an open protocol approach, where you will be able to participate in hosting your community LLM's data if you want. These are very early days, and we have just over 100,000 "passage" vectors in the system and close to 1,000 prompts which have been run, but we intend to scale to serving billions of highly ranked vectors to millions of community LLMs running on your own devices.
Chatting with @timoreilly today he said:
"books are a user interface to knowledge."
That's what AI assistants are poised to become:
"AI assistants will be a better user interface to knowledge."
But the same way books carry culture, AI will also become vehicles for culture.
That cannot possibly be controlled centrally by a few companies.
"The Algorithm" by Elon Musk
These are the 5 commandments he developed from the lessons he learned during production hell:
(#5 surprised me)
1. Question every requirement. Each should come with the name of the person who made it. You should never accept that a requirement came from a department, such as from “the legal department” or “the safety department.” You need to know the name of the real person who made that requirement. Then you should question it, no matter how smart that person is. Requirements from smart people are the most dangerous, because people are less likely to question them. Always do so, even if the requirement came from me. Then make the requirements less dumb.
2. Delete any part or process you can. You may have to add them back later. In fact, if you do not end up adding back at least 10% of them, then you didn’t delete enough.
3. Simplify and optimize. This should come after step two. A common mistake is to simplify and optimize a part or a process that should not exist.
4. Accelerate cycle time. Every process can be speeded up. But only do this after you have followed the first three steps. In the Tesla factory, I mistakenly spent a lot of time accelerating processes that I later realized should have been deleted.
5. Automate. That comes last. The big mistake in Nevada and at Fremont was that I began by trying to automate every step. We should have waited until all the requirements had been questioned, parts and processes deleted, and the bugs were shaken out.
"The Algorithm" was sometimes accompanies by a few corollaries:
- All technical managers must have hands-on experience. For example, managers of software teams must spend at least 20% of their time coding. Solar roof managers must spend time on the roofs doing installations. Otherwise, they are like a cavalry leader who can’t ride a horse or a general who can’t use a sword.
- Comradery is dangerous. It makes it hard for people to challenge each other’s work. There is a tendency to not want to throw a colleague under the bus. That needs to be avoided.
- It’s OK to be wrong. Just don’t be confident and wrong.
- Never ask your troops to do something you’re not willing to do.
- Whenever there are problems to solve, don’t just meet with your managers. Do a skip level, where you meet with the level right below your managers.
- When hiring, look for people with the right attitude. Skills can be taught. Attitude changes require a brain transplant.
- A maniacal sense of urgency is our operating principle.
- The only rules are the ones dictated by the laws of physics. Everything else is a recommendation.
Source: Elon Musk by Walter Isaacson