Barney Pell is an entrepreneur and VC. Barney Pell's Syndicate, Ecoation, Moon Express, Singularity U. Prev: Bing, Powerset, Mayfield, NASA, AI games pioneer.
Microsoft Copilot failed. Gemini failed. Grok failed.
Here's the AI that actually builds Excel (right):
I tested 11 different AIs to build one spreadsheet.
Most couldn't even open the file they made.
Claude Cowork built 6 tabs and 700+ formulas.
Most people use AI for spreadsheets like this:
"Make me a spreadsheet."
Then the AI invents numbers. Hardcodes & hides.
You can't find the error. So you rebuild it by hand.
Here's (exactly) how you do it instead:
1. Download Claude app (for free).
2. Click the "Cowork" tab (between Chat & Code)
3. Select your folder. Pick "Opus 4.8" + "Effort high"
4. Connect Google Drive with "+" → Connectors
5. Paste your data. Describe the sheets you need.
6. End every prompt with this one line:
"Before building, list your top 10 assumptions so I can sanity-check them, then execute."
That last line is the whole trick.
You control the AI. Not the other way around.
✦ These are the 3 things I didn't expect:
1. It defends its own numbers before it builds.
It lists 10 assumptions. You challenge them.
Every input lives on an "Assumptions". Editable.
Never buried inside a formula you can't trace.
2. It builds entire board-ready models from scratch.
"12-month revenue forecast. 4 service lines. Base/Bull/Bear toggle."
It doesn't explain what a forecast is.
It builds it. Funnel, P&L, Dashboard, Scenarios.
3. It opens straight into Google Sheets.
No "done" with a file you can't find.
Click Drive. The whole model opens. Live. Working.
41 years of Excel experience is no longer a moat.
Claude builds in 7 mins what used to take a day.
Get the full playbook here: https://t.co/ZgmUFXd0Iw
We've written about AI-induced physician deskilling that has already surfaced
https://t.co/iMy6zyWnhZ @tberzin
AI-induced never-skilling among newly trained doctors, while not yet proven, is a serious concern that needs to be addressed @NatureMedicine@nliulab
https://t.co/yov3YvsGti
Language models may not need to “build” hierarchies.
Hierarchies may fall out of the statistics of language.
A beautiful new paper by Andres Nava and Matthieu Wyart proposes a distributional theory for one of the most basic structures in meaning:
the “is-a” relation.
An owl is a bird.
A bird is an animal.
An animal is an organism.
This relation — hypernymy — looks like an ontology.
But the paper asks a sharper question:
Does hierarchical concept geometry in language models require a hierarchy-specific mechanism?
Or can it emerge from word co-occurrence alone?
Their answer is striking.
Start with a simple empirical fact:
words closer together in the WordNet hierarchy tend to co-occur more often.
“tree” and “plant” appear together more than “tree” and “organism.”
That decay in co-occurrence with semantic distance induces structure in the embedding Gram matrix.
Then the spectrum does the rest.
The leading eigenvectors first separate broad branches of the taxonomy, then progressively finer sub-branches.
This creates what the authors call hierarchical splitting geometry:
coarse-to-fine organization in representation space.
In the organism example, one principal direction separates plants from animals. Later directions split flowers from trees, birds from fish, and eventually finer distinctions like daisy vs. poppy.
That is the elegant part:
the geometry looks conceptual,
but the mechanism is spectral.
The authors prove this under mild positivity and decay assumptions on the co-occurrence kernel, confirm it across sampled WordNet subtrees in word2vec, and then show the same signature extends surprisingly well to Gemma 2B unembeddings.
This is not saying LLMs do not represent hierarchies.
They clearly do.
It is saying we should be careful about why that geometry exists.
Some elegant semantic structure may not be evidence of a specialized internal ontology.
It may be the mathematical shadow of pairwise word statistics.
That matters for interpretability.
If we find clean concept directions, orthogonal refinements, or taxonomic splits inside models, we should ask:
Is this a functional mechanism?
Or is it the spectrum of the data distribution made visible?
This paper pushes toward a more precise science of representation geometry.
Less mysticism.
More mechanism.
Less “the model learned an ontology.”
More “the co-occurrence kernel shaped an eigenspace.”
Full credit to the authors:
Andres Nava and Matthieu Wyart.
Paper:
Hierarchical Concept Geometry in Language Models Emerges from Word Co-occurrence
https://t.co/Le1EHAVqJP
I’m attaching the first page because Figure 1 is worth studying closely.
The deep lesson:
meaning may become geometry not because the model was taught a taxonomy,
but because language itself already contains one in its statistics.
#AIResearch #Interpretability #LLM #NLP #RepresentationLearning #MachineLearning
A Stanford psychologist spent 4 years proving that the simple act of walking generates 60% more creative ideas than sitting, and the experiment she designed to kill every alternative explanation is one of the most decisive findings in modern psychology.
Her name is Marily Oppezzo.
She got the idea for the study while walking with her advisor at Stanford to discuss her thesis topic, and the paper she eventually published in the Journal of Experimental Psychology in 2014 is sharp enough that it should have ended the seated meeting on the day it came out.
She ran 4 experiments on 176 people. Same person tested twice. Once sitting, once walking. The creativity tasks were the standard ones psychologists have used for decades to measure how good a brain is at generating novel useful ideas.
The result was almost too clean to publish.
81% of participants in the first experiment produced more creative ideas while walking than while sitting. In the second experiment, 88%. In the third, 100%. Every single person walked into a more creative version of themselves.
On average, people generated 60% more novel useful ideas the moment their legs started moving.
The skeptical question is the obvious one. Maybe it was the fresh air. Maybe it was the scenery passing by. Maybe it was the change of environment doing the work, not the walking itself.
Oppezzo killed every one of those explanations with one experimental decision.
She put people on a treadmill facing a blank wall. No scenery. No fresh air. No environmental change. Just legs moving in place while staring at white drywall. The 60% boost held.
Then she ran the experiment that closed the case completely. She took participants outside in two conditions. Half of them walked through a Stanford courtyard. The other half were pushed through the exact same courtyard in a wheelchair. Same outdoor stimulation. Same scenery passing at the same speed. The only difference was whether the legs were moving.
The walkers produced dramatically more novel high-quality ideas than the wheelchair group. The outdoors did almost nothing on its own. The walking did everything.
This is the part of the study that hit hardest when I read it the first time.
She also tested the opposite kind of thinking. Convergent thinking. The kind where there is one right answer and you have to narrow down to it.
Word puzzles where 3 words share a hidden fourth word that connects them. The seated participants did slightly better on these. Walkers got slightly worse.
Walking is not a general intelligence enhancer. It does one specific thing. It opens up the divergent search inside your brain. The part that generates options. The part that produces unexpected connections. The part that takes a problem and finds five ways into it instead of one.
When you need to converge on the single right answer, sit down. When you need to find the answer in the first place, get up.
The mechanism is now well understood. Walking selectively activates what neuroscientists call the default mode network, the system inside your brain that runs when you are not consciously focused on anything. The DMN is where mind-wandering happens. Where memories cross-reference each other. Where ideas that have been sitting in separate folders inside your head finally bump into each other.
When you sit at a desk and force yourself to concentrate, you suppress the DMN. When you walk at a natural pace, the executive part of your brain gets just busy enough handling the walking that the DMN comes online and starts doing the work that focus was blocking.
The most useful finding in the entire paper is the one almost nobody quotes.
The boost did not turn off the moment people stopped walking. Participants who walked first and then sat back down stayed elevated. Their next round of seated creativity work was still significantly better than people who had been sitting the whole time. The rest lingered for at least several minutes after the legs stopped moving.
You do not need to do creative work while walking. You need to walk before the creative work. The brain holds the state.
The history of this is the part that should haunt anyone who still does meetings in chairs.
Charles Darwin built a gravel loop behind his house in Kent called the Sandwalk and walked it 3 times a day for the rest of his life. The theory of evolution was developed one lap at a time on that path.
Nietzsche walked up to 10 hours a day during the years he wrote his most important books and openly said the work was conceived on his feet.
Beethoven composed for the morning and walked for 5 hours every afternoon with a pencil in his pocket for when something landed.
Kahneman said the best thinking of his Nobel Prize-winning career happened on leisurely walks with Amos Tversky. Steve Jobs refused to take important conversations sitting down. He held them on foot.
Every one of them was using the system Oppezzo would not measure until 2014. They just did not know what to call it.
The question worth sitting with is the one almost nobody asks.
Every meeting you have ever attended sitting around a table was a meeting held at a fraction of the brain power that was actually available to the people in the room. Every brainstorm that got stuck inside a conference room. Every problem you tried to solve at a desk and gave up on. Every idea you could not quite get to.
The intervention is the easiest one in modern science. No supplement. No app. No subscription. No training program. Just a pair of legs and 15 minutes.
The Stanford lab proved it. The philosophers knew it. The neuroscience explains it.
And almost everyone reading this is still trying to think their way out of problems sitting completely still.
New @AnnalsofIM
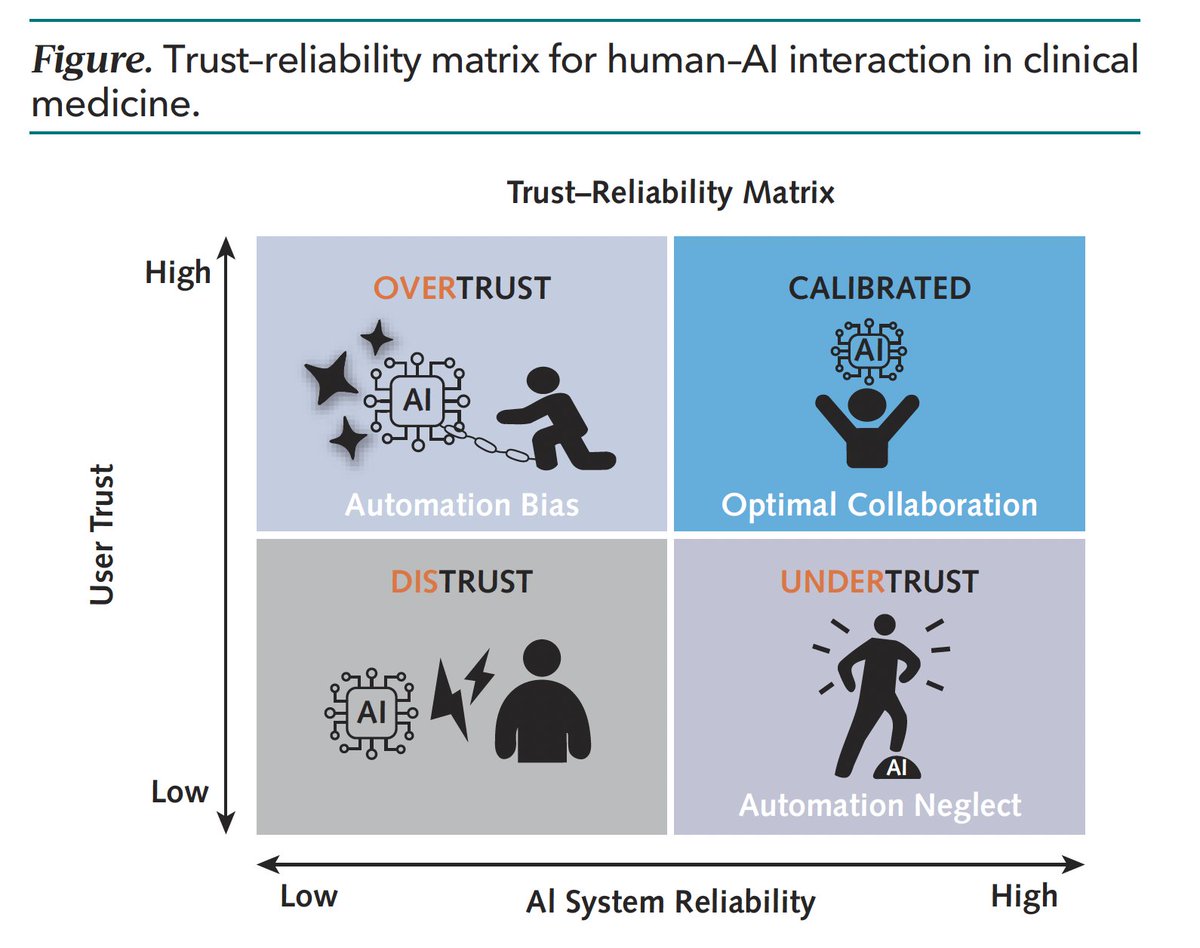
"The Human Factor in Clinical AI: Why Technology Alone is Not Enough"
Gets into the trust issue and concludes: 'The most important question in medical AI may not be “how accurate is the algorithm?” but rather “how do we calibrate the relationship between clinician and machine?'
https://t.co/n4ijxrm7o9
New research from Microsoft Research
I see a lot of AI engineers handwriting agent skill docs and hope they generalize.
Probably not optimal. This works show why.
It treats the skill doc as a trainable external state of a frozen agent instead.
It introduces SkillOpt, where an optimizer model makes validation-gated edits to the skill file. It adds, deletes, or replaces instructions, with a textual learning rate that controls how aggressively each round rewrites the doc. The agent itself never changes.
SkillOpt is best or tied on all 52 (model, benchmark, harness) cells.
On GPT-5.5 it adds 23.5 points in direct chat, 24.8 with Codex, and 19.1 with Claude Code over no skill. It beats human-written skills, TextGrad, GEPA, and EvoSkill, carries zero extra inference-time cost, and the learned skills transfer across models and harnesses.
Paper: https://t.co/mNgTmmT32U
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Judea Pearl spent decades proving that almost every "breakthrough" published in research is just correlation wearing a lab coat.
His book "The Book of Why" introduced the Ladder of Causation: a framework that separates what LOOKS like a finding from what IS one.
I turned his entire causal reasoning framework into a prompt that audits any research paper for you.
Feed it a study. It tells you whether the finding is real causation or dressed-up correlation. 👇
Looped Transformers: the dream was right. But there was trouble in paradise.
The loop made them unstable, expensive, and memory-hungry, with gains hard to scale. So we asked: 𝗖𝗮𝗻 𝘄𝗲 𝗿𝗲𝗮𝗽 𝘁𝗵𝗲 𝗿𝗲𝘄𝗮𝗿𝗱𝘀 𝘄𝗶𝘁𝗵𝗼𝘂𝘁 𝗽𝗮𝘆𝗶𝗻𝗴 𝘁𝗵𝗲 𝗹𝗼𝗼𝗽 𝘁𝗮𝘅?
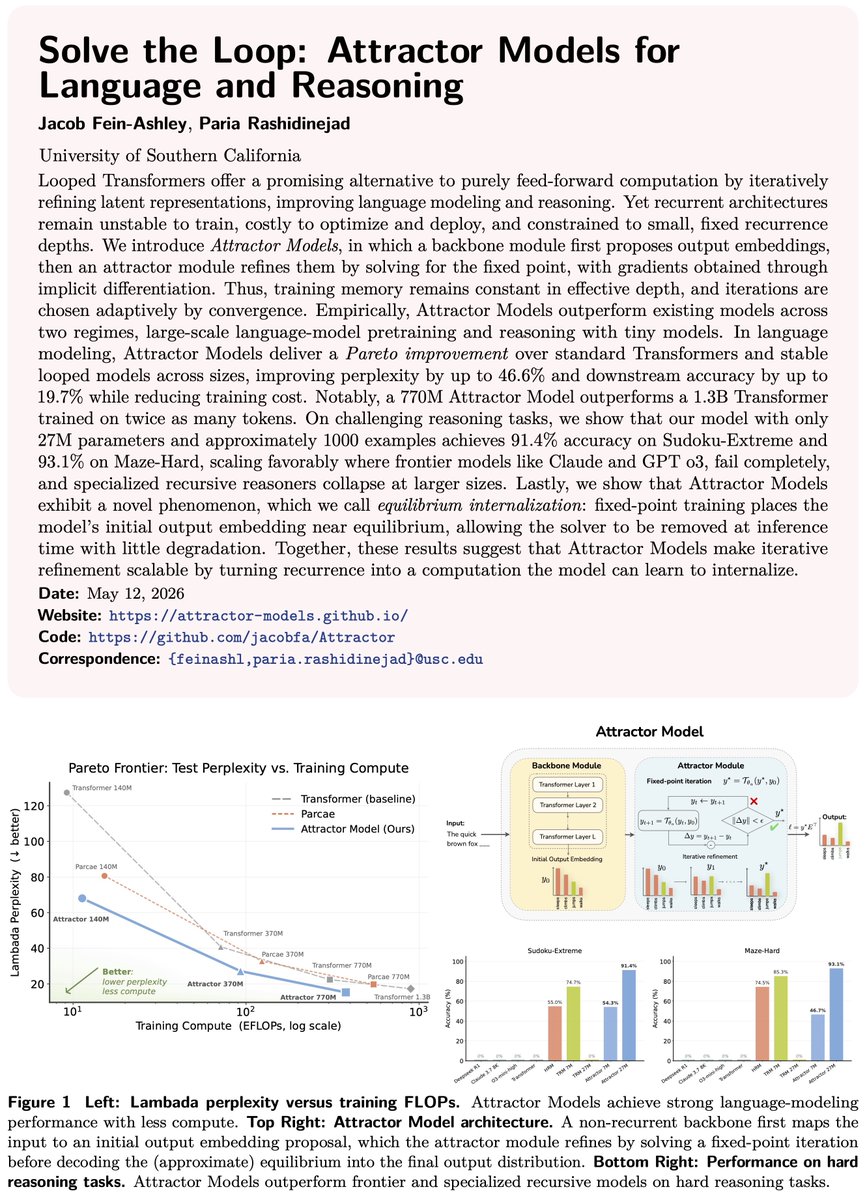
Introducing 𝗔𝘁𝘁𝗿𝗮𝗰𝘁𝗼𝗿 𝗠𝗼𝗱𝗲𝗹𝘀 𝗳𝗼𝗿 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗮𝗻𝗱 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴:
• A Backbone proposes an initial “guess” output embedding;
• An Attractor refines it: a fixed-point solver lets the model “think” before each token.
Implicit differentiation trains the model stably, with constant memory and without BPTT.
Training also revealed a surprising phenomenon: 𝗘𝗾𝘂𝗶𝗹𝗶𝗯𝗿𝗶𝘂𝗺 𝗜𝗻𝘁𝗲𝗿𝗻𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻
Over the course of training, the Backbone learns to propose latents close to the equilibrium itself, making the Attractor almost unnecessary at inference.
Results:
• 𝗣𝗮𝗿𝗲𝘁𝗼 𝗶𝗺𝗽𝗿𝗼𝘃𝗲𝗺𝗲𝗻𝘁 𝗼𝗻 𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗺𝗼𝗱𝗲𝗹𝗶𝗻𝗴: up to 𝟰𝟲.𝟲% lower perplexity and 𝟭𝟵.𝟳% better downstream accuracy. A 770M Attractor Model beats a 1.3B Transformer, despite being trained on half as many tokens.
• 𝗦𝗶𝗴𝗻𝗶𝗳𝗶𝗰𝗮𝗻𝘁 𝗴𝗮𝗶𝗻𝘀 𝗼𝗻 𝗵𝗮𝗿𝗱 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝘁𝗮𝘀𝗸𝘀: a 27M Attractor Model trained on only 1K examples achieves 𝟵𝟭.𝟰% 𝗼𝗻 𝗦𝘂𝗱𝗼𝗸𝘂-𝗘𝘅𝘁𝗿𝗲𝗺𝗲 and 𝟵𝟯.𝟭% 𝗼𝗻 𝗠𝗮𝘇𝗲-𝗛𝗮𝗿𝗱, while Transformers and frontier models like Claude and GPT o3 score 𝟬%.
📝 https://t.co/vjkDMxXLuD
🧵 1/10
1/ Many optimization problems are hard in theory.
But real OR and NP-hard instances often have exploitable structure.
Can an LLM agent discover that structure automatically and turn it into faster solver code?
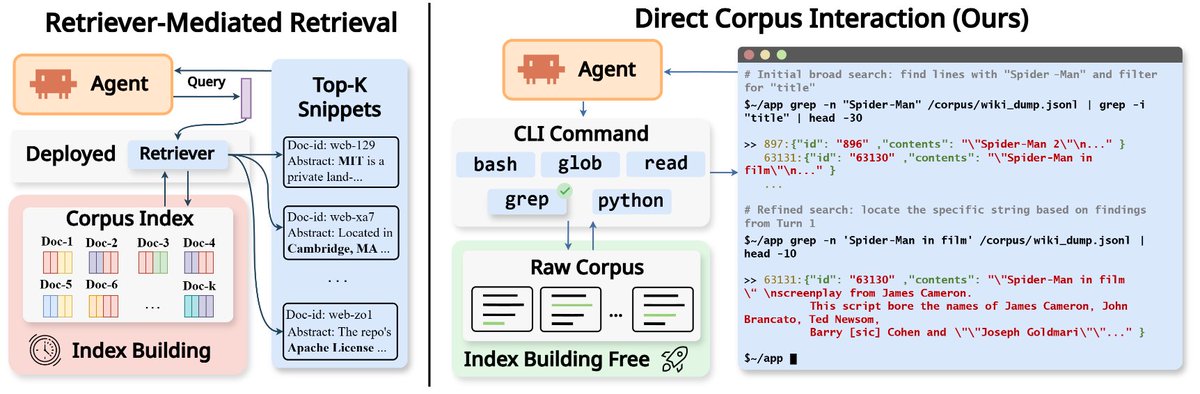
🔥 Introducing Direct Corpus Interaction (DCI)! The best retriever for agentic search is no retriever.
🚀 We replaced the entire agentic search pipeline — embedding model, vector index, top-k retrieval — with only `grep` and `bash`. 🔧
📄 Paper: https://t.co/9FVvrdLCRf
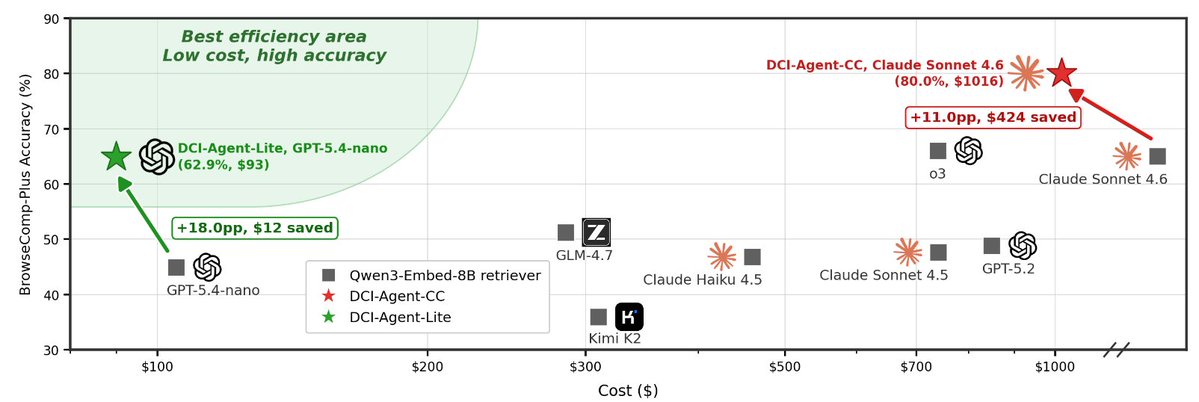
DCI unlocks the full agentic potential of any Claude Sonnet 4.6: 69.0% → 80.0% on BrowseComp-Plus (+11.0, −$424).
💡The Magic:
The agent searches the raw corpus directly — `grep`, `find`, `bash`, shell pipelines — exactly like a coding agent navigating a codebase. No preprocess. No embedding model. No vector index. No offline indexing.
📊The Results:
DCI outperforms top baselines across 13 benchmarks, with average gains of:
🔍 Agentic Search: +11.0%
🧠 Multi-hop QA: +30.7%
📈 IR Ranking: +21.5%
💡 Insights:
Beyond accuracy, we conduct a series of controlled ablation studies to pinpoint the sources of DCI’s gains. Specifically, we examine trajectory-level search, evidence utilization corpus, context management, and tool usage (RQ2-RQ6).
Try it yourself!
🛠️Code: https://t.co/A8ch5QM1E4
🤖 Demo: https://t.co/Y9H4abb2P6
🔎 Eval logs: https://t.co/4iM7u1M8mz
A foundation model trained on 1.5 billion years of evolution
Comparing cells across species is one of the oldest problems in biology, and one of the hardest. Different organisms share fewer and fewer genes the further apart they sit on the tree of life, so traditional methods relying on orthologous gene mapping quickly hit a wall. A frog and a coral, separated by hundreds of millions of years, simply don't have enough common vocabulary to compare their cell types directly.
James Pearce and coauthors tackle this with TranscriptFormer, a generative autoregressive transformer trained on up to 112 million single cells from 12 species spanning 1.53 billion years of evolution: humans, mice, zebrafish, fruit flies, sponges, yeast, even malaria parasites. The key trick is that genes are not represented as discrete tokens but as ESM-2 protein language model embeddings, projecting every species into a shared, evolution-aware space. The model treats each cell as a "sentence" of genes and learns the joint distribution of which genes are expressed and at what level, using an expression-aware attention mechanism where transcript counts modulate the attention weights themselves.
The results are remarkable. The model classifies cell types in stony coral (685 million years from humans, never seen in training) with F1 above 0.65, while previous state-of-the-art models drop below 0.5. It transfers immune perturbation labels across mouse, rat, rabbit, and pig with F1 of 0.92, and detects drug-induced transcriptional states in human cells with mean AUC of 0.88 across 95 compounds. Even more striking, phylogenetic relationships, developmental trajectories, and cell type hierarchies emerge in the embeddings without any supervision. Sponge choanocytes map to primary sensory neurons in worms and frogs, supporting old hypotheses about the origin of nervous systems.
Pharma teams running cross-species safety studies could transfer perturbation signatures from rodents to human-relevant contexts without retraining, and biotech groups working on cell therapies or model organism screens get a generative tool that can be prompted to predict transcription factor targets directly. It is a step toward foundation models that act as queryable cell atlases rather than static lookup tables.
Paper: Pearce et al., Science (2026) — journal license | https://t.co/RhqLMgzfVY
Superintelligent Retrieval Agent: The Next Frontier of Information Retrieval
Meta presents a training-free retrieval agent that compresses multi-round search to a single BM25 call by an LLM to enrich both corpus & query vocab.
📝https://t.co/zw3u54FB5J
👨🏽💻https://t.co/owVB68p1V1
Researchers just taught AI to think 12x faster without using words.
Reasoning chains are powerful but expensive.
Every token a model "thinks" costs time and money.
A new paper called Abstract Chain-of-Thought proposes a fix.
Instead of reasoning in full sentences, the model invents its own compressed language.
It uses reserved placeholder tokens like <TOKEN_X> as shorthand for entire thoughts.
The result is up to 11.6x fewer reasoning tokens with comparable accuracy.
Training happens in two stages:
1. A warm-up loop teaches the model what these abstract tokens mean using a teacher's verbal reasoning.
2. Reinforcement learning then refines how the tokens are sequenced for better answers.
Tested on math, instruction-following, and multi-hop benchmarks, performance held up against verbal chains.
Even stranger, the abstract vocabulary started forming patterns similar to real language.
Frequent tokens dominated like common words do.
Title:
Global genetic interaction network of a human cell
DOI: 10.1016/j.cell.2026.00345-4
A major bottleneck in human biology has been the inability to systematically map functional relationships between genes at scale. In this new Cell study, researchers construct a global genetic interaction network in human cells, providing one of the most comprehensive frameworks yet for decoding cellular function.
Using large-scale perturbation strategies, the study maps gene co-essentiality and genetic interactions across the genome, revealing how genes cooperate, buffer, or compensate for each other under physiological conditions. �
Cell
A key conceptual advance is the transition from single-gene essentiality to network-level functional architecture. Rather than asking “is this gene essential?”, the work asks:
👉 what genetic context makes a gene essential?
This enables identification of:
• Functional modules (protein complexes, pathways)
• Redundant buffering systems (synthetic rescue)
• Vulnerabilities (synthetic lethality candidates)
Importantly, the network reveals conserved interaction principles across evolution, suggesting that cellular organization follows reproducible design rules—not random complexity. �
Cell
From a translational perspective, this is highly actionable:
• Cancer therapy: pinpoint synthetic lethal targets in tumor-specific contexts
• Precision medicine: interpret variants through network position, not just mutation
• Drug discovery: prioritize pathway-level interventions over single targets
Conceptually, this work shifts biology toward a systems-level causality model, where phenotype emerges from interacting gene circuits, not isolated components.
This 2026 survey paper presents a unified roadmap for leveraging agentic reasoning to transform Large Language Models into autonomous agents capable of planning, acting, and learning in dynamic, real-world environments, bridging the gap between thought and action.
ChapterPal: https://t.co/uQhqHIKCHO
PDF: https://t.co/sWGups581J
// Contextual Agentic Memory is a Memo, not True Memory //
Most agent memory today isn't memory. They are more like memos.
A new paper argues that vector stores, RAG buffers, and scratchpads implement lookup, not consolidation.
Agents accumulate notes indefinitely without ever turning them into expertise. The framing draws from neuroscience's Complementary Learning Systems theory: biological intelligence pairs fast hippocampal storage with slow neocortical consolidation. Current AI agents only implement the first half which includes fast write, similarity recall, no abstraction step.
Why does it matter?
The paper proves a generalization ceiling on compositionally novel tasks.
As long as memory stays retrieval-only, your agent can't apply abstract rules to inputs that don't already look like something in the store. It also leaves the agent permanently exposed to memory poisoning.
If you're building long-running agents and treating "memory" as a vector index, this paper provides a good discussion of what you're actually missing.
Paper: https://t.co/2952BbErgE
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
Agentic AI for science featured in @naturemethods: https://t.co/sLu3EZZMks. We are still early, with many open challenges ahead, but it is exciting to see this direction continue to evolve, wonderful piece by @metricausa
ToolUniverse — an open platform enabling AI agents to use scientific tools and databases at scale, by @GaoShanghua
→ https://t.co/lWHESvXvIW
ClawInstitute — shared research boards for long-running collaborative discovery where agents co-develop ideas over time, by @GaoShanghua@AdaFang_
→ https://t.co/cIDf53yOsZ
Medea — an omics AI agent for large-scale biological reasoning and analysis, by Pengwei Sui
→ https://t.co/t2lut9nyJV
@HarvardDBMI@harvardmed@KempnerInst@broadinstitute
"We are about to see more scientific progress in the next 5 years than in the previous century."
Here's a glimpse of what we're seeing through building scientific superintelligence:
➡️Lila's AI has accumulated over 10 trillion tokens of scientific reasoning data, generated entirely by AI models reasoning through the scientific method against experimental results
➡️ For CAR-T cell therapy, one of the most promising frontiers in cancer treatment, Lila's AI explored 300,000 design variants. The traditional approach tested 13.
➡️ For mRNA therapeutics, Lila's AI achieved performance twice as effective as current technologies from leading pharmaceutical companies. Expression lasting 15 days versus the 1.5 days achieved by conventional approaches. A 10x improvement.
This is what happens when the scientific method compounds at machine speed. Read the full article by @PeterDiamandis: