✨ Excited to share that our paper "RefEdit: A Benchmark and Method for Improving Instruction-based Image Editing on Referring Expressions" has been accepted at ICCV 2025! 🌺📍See you in Hawaii!
🧵 Here's what we did, why it matters, and what we’re releasing ⬇️ (1/8)
Needed to generate ~50 videos. Veo3 rate per day is 10 for Tier 1.🤦♂️
Started using Grok - cheaper than Veo3, even cheaper with batch processing, faster than Veo3, supports 480p, supports varying time lengths and apparently better quality.
We are not without our flaws, yet Sri Lanka has much to be proud of.
Our universal, free healthcare system places us among the world’s best, one of the many achievements of our nation over the past 76 years.
If you’re an "ML Engineer" and you think “Transformer” just means stacking encoder–decoder blocks and calling it a day, you’re missing the actual mechanism that makes modern AI work.
Concept 16: The Transformer Is a Math Engine, Not a “Model Architecture
"Most people can implement a Transformer pipeline. Very few can explain why the Transformer works."
Let’s break it down properly.
1. The core idea, Transformers = Vector Field Manipulation
Every layer of a Transformer applies three mathematical operations:
1. Projection
2. Attention as weighted integration
3. Update via residual fields
The Transformer is basically a learned vector field processor.
Not a sequence model.
Not an architecture choice.
It could be called a mathematical engine that maps token representations through a series of controlled linear and nonlinear transformations.
2. Attention is not magic, it is a quadratic form. (Take a minute while reading this part)
Self-attention computes:
Attention(Q, K, V) = softmax(QKᵀ / √d) V
This means:
• QKᵀ is a similarity matrix
• softmax turns similarities into probability weights
• multiplying by V computes a weighted expectation over token values
Attention = learnable, data-dependent kernel smoothing.
It is a kernel machine inside your neural network.
3. Multi-head attention = multiple kernels in parallel
Each head learns a different geometry of similarity. One head may focus on local patterns, another on long-range dependencies, another on syntax, another on semantics.
When people say “transformers understand context,” this is what they mean:
each head builds a different function approximator.
4. Residual connections are the true backbone
Forget attention. Residuals are the reason Transformers train at all if you look at it properly.
xₜ₊₁ = xₜ + f(xₜ)
This means every layer learns a correction to the current representation. Gradient flow stays stable. Representations evolve smoothly.
Without residuals, Transformers collapse.
5. LayerNorm = curvature control
Norms scale the Jacobian of each layer.
This keeps the singular values of the mapping from blowing up or collapsing.
LayerNorm is not cosmetic. It is what ensures the model doesn’t EXPLODE internally.
6. Feedforward layers = feature expansion and contraction
The FFN block:
FFN(x) = W₂ σ(W₁ x)
expands dimension, applies a nonlinearity, then compresses.
This lets the model create new features that attention alone cannot express.
It acts as a learned universal approximator inside each layer.
7. Why people can code Transformers but not explain them
Because coding a transformer is wiring blocks together. Understanding a transformer requires knowing:
• attention as kernel regression
• softmax as a probability normalizer
• LayerNorm as Jacobian control
• residuals as stable integration
• FFN as feature synthesis
• positional encodings as geometric priors
• multi-head structure as an ensemble of learned kernels
Most people never go beyond surface-level implementation is something I realised when I caught myself trying to work on advanced papers without actually understanding the fundamentals.
TL;DR
The Transformer works because its math is designed to stabilize gradients, amplify structure, and integrate information the way a continuous dynamical system would.
It is not “just an architecture.”
It is the most efficient numerical method we’ve found for learning functions over sequences, graphs, and basically anything with structure.
@ScottEdwar33859@karpathy Get the answer script from Gemini run that in the challenge interface and paste the terminal output as the next input to Gemini. There was no help or guiding from my side. Both Gemini and GPT-5 Pro received same initial prompt and challenge files.
@karpathy Another main difference is the compute time. Altogether Gemini took like 3 mins and GPT-5 Pro spent close to 2 hours. Even when I provided the correct script from Gemini, GPT-5 Pro said that solution is wrong.
@karpathy Tried a software vulnerability challenge from one of the graduate courses (stack buffer overflow challenge) and Gemini 3 Pro was able to complete in around 3-4 iterations. GPT-5 Pro couldn't solve even after 10 iterations.
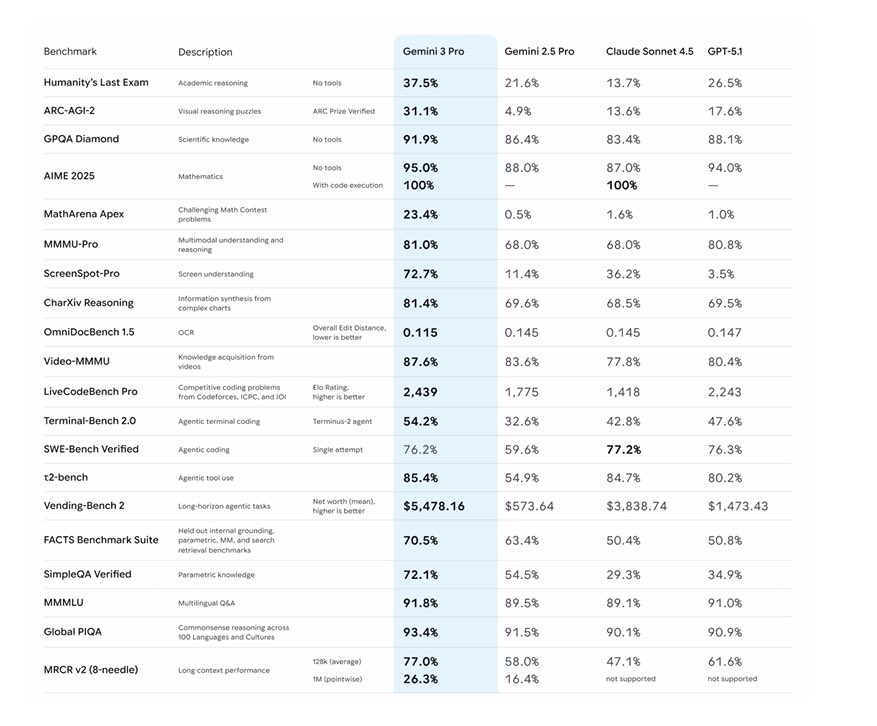
Gemini 3 leak - some crazy improvements on math, screen understanding, and simpleqa.. somehow beaten by sonnet on swebench but winning on terminalbench
Lower context length than 2.5 pro too 🫣
https://t.co/qQah8GPDIV
We’re presenting our RefEdit paper at ICCV 2025 — Booth #71!
Come chat with us about challenging cases in image editing and see how RefEdit pushes the limits of image editing. #iccv25
Our @ApgAsu crew @SCAI_ASU kicked off the Fall 2025 semester with a board game night 🎲✨
When the timing is right, in the right context, make the right move. Just like in board games, in research, and in life 🤠
Huge thanks to my amazing co-authors: @patelmaitreya, Shivam Singh, @prof_yz, and @cbaral — couldn’t have done this without you! We would also like to thank the @SCAI_ASU, ASU Research Computing, and @cr8dlcloud for generous support w.r.t. GPUs. Onward! 🚀
✨ Excited to share that our paper "RefEdit: A Benchmark and Method for Improving Instruction-based Image Editing on Referring Expressions" has been accepted at ICCV 2025! 🌺📍See you in Hawaii!
🧵 Here's what we did, why it matters, and what we’re releasing ⬇️ (1/8)