My fellow code monkeys (@jordanjuravsky@ryansehrlich) and I are excited to release CodeMonkeys: a system for solving SWE-bench issues specifically designed to leverage test-time compute!
CodeMonkeys solves 57.4% of issues on SWE-bench Verified. A core component of our system involves repeatedly sampling then selecting over candidate solutions. Using our selection mechanism on an ensemble of our output and 4 of the top leaderboard submissions gets a score of 66.2% - only 5.5% below the reported score of o3.
We also think that there is a lot left to improve and want to make it easy for anyone to start exploring this area. To support this we are releasing all of our code, data and commands!
Joint work with @ronnieclark__ , @HazyResearch, and @Azaliamirh!
More details below:
Today we’re excited to release Muse Spark. It’s our first end-to-end test of the new stacks we’ve built at MSL, and a true testament to this incredible team. We’re eager to learn from your feedback!
https://t.co/PPWBgewWQx
Excited to share what we’ve been building at Meta Superintelligence Labs! We just released Muse Spark, our first AI model. It's a natively multimodal reasoning model and the first step on our path to personal superintelligence. We've overhauled our entire stack to support scaling, and this is just the beginning.
https://t.co/KNVjgMcch1
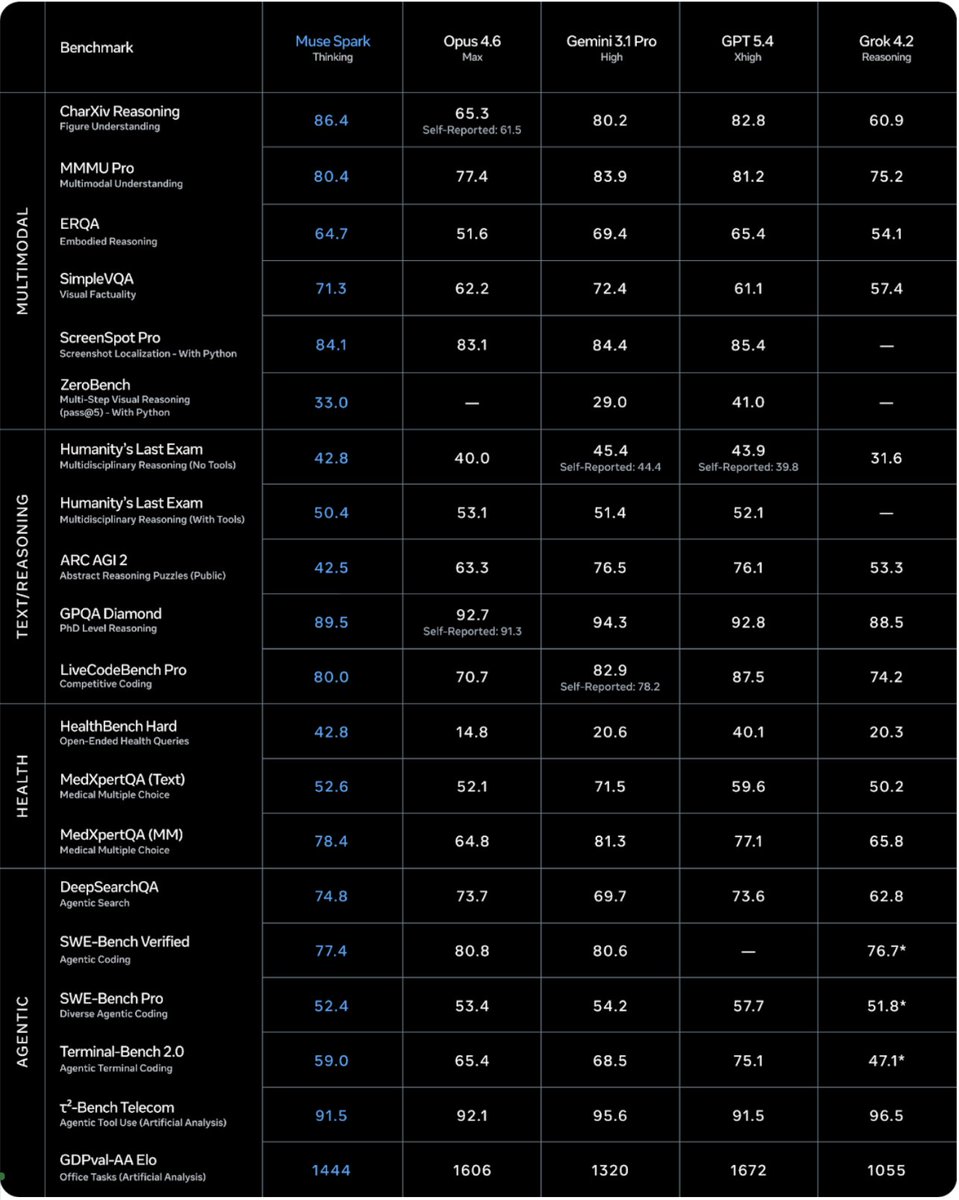
Meta is back! Muse Spark scores 52 on the Artificial Analysis Intelligence Index, behind only Gemini 3.1 Pro, GPT-5.4, and Claude Opus 4.6. Muse Spark is the first new release since Llama 4 in April 2025 and also Meta's first release that is not open weights
Muse Spark is a new model from @Meta evaluated on Artificial Analysis. We were given early access by Meta to independently benchmark the model. It is the first frontier-class model from Meta since Llama 4 Maverick was released in April 2025, and notably the first @AIatMeta model that is not being released as open weights. The release follows Meta's reorganization of its AI efforts under Meta Superintelligence Labs, and signals that Meta is re-entering the frontier race after roughly a year of relative quiet.
For context, Llama 4 Maverick and Scout scored 18 and 13 respectively on the Artificial Analysis Intelligence Index as non-reasoning models at the time of their release, while Muse Spark scores 52. Muse Spark essentially closes the gap between to the frontier in a single release.
The model is not open source and is not yet accessible via an API but Meta has shared they expect this to come soon. Meta is also integrating Muse Spark into their first party products including their Meta AI chat product, Facebook, Instagram and Threads.
Key takeaways from our benchmarks:
➤ Muse Spark scores 52 on the Artificial Analysis Intelligence Index, placing it within the top 5 models we have benchmarked. It sits ahead of Claude Sonnet 4.6, GLM-5.1, MiniMax-M2.7, Grok 4.20 and behind Gemini 3.1 Pro Preview, GPT-5.4 and Claude Opus 4.6
➤ Muse Spark is notably token efficient for its intelligence level. It used 58M output tokens to run the Intelligence Index, comparable to Gemini 3.1 Pro Preview (57M) and notably lower than Claude Opus 4.6 (Adaptive Reasoning, max effort, 157M), GPT-5.4 (xhigh, 120M) and GLM-5 (110M)
➤ Muse Spark is the second-most capable vision model we have benchmarked. It scores 80.5% on MMMU-Pro, behind only Gemini 3.1 Pro Preview (82.4%)
➤ Muse Spark performs strongly on reasoning and instruction-following evaluations. It scores 39.9% on HLE, trailing only Gemini 3.1 Pro Preview (44.7%) and GPT-5.4 (xhigh, 41.6%). The model also achieved 5th highest in CritPT with a score of 11%, an eval that is focused on difficult physics research questions. This is substantially above above Gemini 3 Flash (9%) and Claude 4.6 Sonnet (3%)
➤ Agentic performance does not stand out. On GDPval-AA, our evalaution focused on real world work tasks, Muse Spark scores 1427, behind both Claude Sonnet 4.6 at 1648 and GPT-5.4 at 1676, but ahead of Gemini 3.1 Pro Preview at 1320. On On TerminalBench Hard, Muse Spark trails Claude Sonnet 4.6, GPT-5.4, and Gemini 3.1 Pro. Muse Spark joins others in achieving a high τ²-Bench Telecom score of 92%
Key model details:
➤ Modalities: Multimodal including text and vision input, text output
➤ License: Proprietary, Meta's first frontier model not released as open weights
➤ Availability: No public API at the time of publishing. Meta expects to provide API access soon. Meta has started integration into their first party AI offering Meta AI and inside Facebook, Instagram, and Threads
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
Looking forward to attending ICML!
Here are some works on memory/long context, verification, kernel design, multi-model AI systems, and theoretical understanding of test-time scaling from my awesome students and collaborators!
✨ Test-Time Scaling for Robotics ✨
Excited to release 🤖 RoboMonkey, which characterizes test-time scaling laws for Vision-Language-Action (VLA) models and introduces a framework that significantly improves the generalization and robustness of VLAs!
🧵(1 / N)
🌐 Website: https://t.co/pYvytO8OmZ
💻 Code: https://t.co/bDhjWoNBim
🗂️ Datasets and Models: https://t.co/u97uiAFk9V
🚀 Serving Engine: https://t.co/JIuhS9xgUw
📄 Paper: https://t.co/q59LkD2iSV
1/10
ML can solve PDEs – but precision🔬is still a challenge. Towards high-precision methods for scientific problems, we introduce BWLer 🎳, a new architecture for physics-informed learning achieving (near-)machine-precision (up to 10⁻¹² RMSE) on benchmark PDEs.
🧵How it works:
How can we close the generation-verification gap when LLMs produce correct answers but fail to select them?
🧵 Introducing Weaver: a framework that combines multiple weak verifiers (reward models + LM judges) to achieve o3-mini-level accuracy with much cheaper non-reasoning models like Llama 3.3 70B Instruct!
🧵(1 / N)
Giving LLMs very large amounts of context can be really useful, but it can also be slow and expensive. Could scaling inference time compute help?
In our latest work, we show that allowing models to spend test time compute to “self-study” a large corpora can >20x decode throughput while maintaining downstream task performance.
Our approach is simple:
1. Use the LLM to sample synthetic conversations about the corpora.
2. Using gradient descent, train a small adapter (we term a Cartridge) on these synthetic conversations to “burn” the corpora into the adapter weights.
Surprisingly, parameterizing this adapter as a KV cache rather than a LoRA lead to both better in-domain task performance and less forgetting of unrelated facts.
There were a bunch of other interesting results like this: take a look at @EyubogluSabri's thread and the paper for more details about our methodology and results.
Joint work with @EyubogluSabri , @simran_s_arora, @NeelGuha, @dylan_zinsley, @james_y_zou, @Azaliamirh, @HazyResearch
& others!
When we put lots of text (eg a code repo) into LLM context, cost soars b/c of the KV cache’s size.
What if we trained a smaller KV cache for our documents offline? Using a test-time training recipe we call self-study, we find that this can reduce cache memory on avg 39x (enabling 26x higher tok/s and lower TTFT) while maintaining quality. These smaller KV caches, which we call cartridges, can be trained once and reused for different user requests!
Github: HazyResearch/cartridges
(1/5) We’ve never enjoyed watching people chop Llamas into tiny pieces.
So, we’re excited to be releasing our Low-Latency-Llama Megakernel! We run the whole forward pass in single kernel.
Megakernels are faster & more humane. Here’s how to treat your Llamas ethically:
(Joint with @jordanjuravsky, @stuart_sul, @OwenDugan, @dylan__lim, @realDanFu, @simran_s_arora, and @HazyResearch)
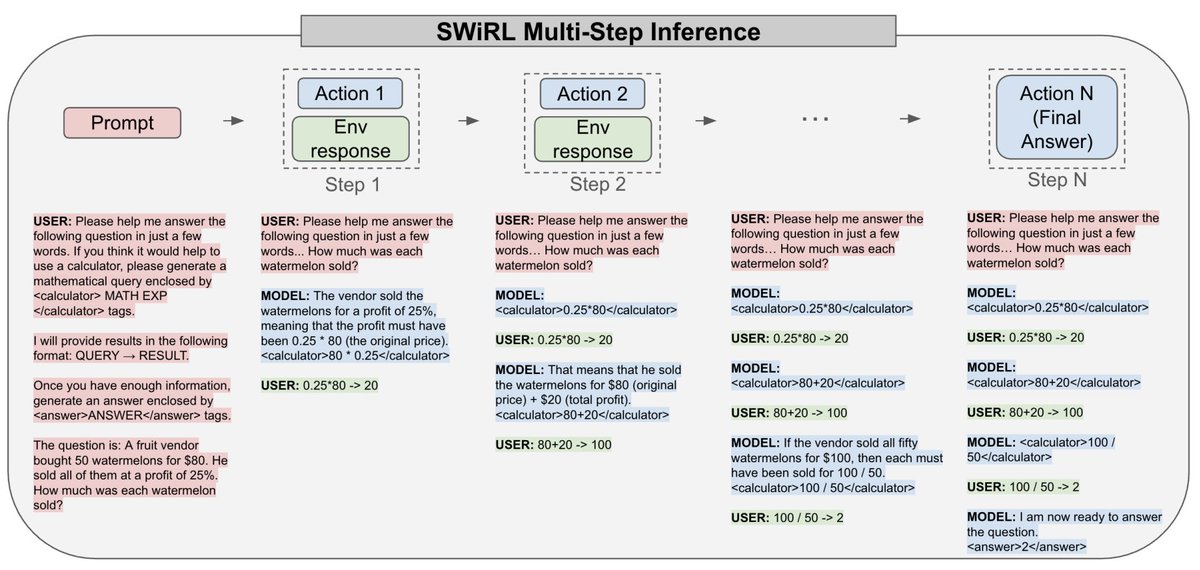
Excited to release SWiRL: A synthetic data generation and multi-step RL approach for reasoning and tool use!
With SWiRL, the model’s capability generalizes to new tasks and tools. For example, a model trained to use a retrieval tool to solve multi-hop knowledge-intensive question answering tasks becomes significantly better at using Python to solve math problems (and vice versa). As we scale the synthetic data size, the generalization gains continue to improve!
Excited to share our new paper on Step-Wise Reinforcement Learning (SWiRL), which uses reinforcement learning and synthetic trajectories to improve multi-step reasoning and tool use! (1/8)
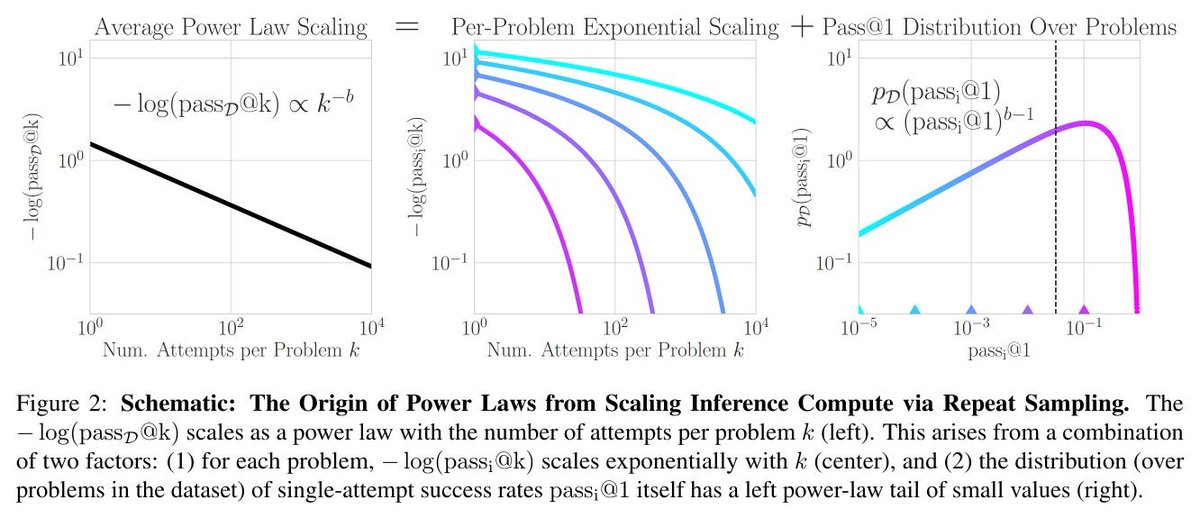
In Large Language Monkeys, we showed the scaling laws of inference-time compute with repeated sampling--the power law relationship between the number of repeated attempts and the fraction of problems solved!
The following amazing work theoretically proves the necessary and sufficient conditions for this property to hold, which is that the left tail of pass@1 must be a power law itself. It then introduces actionable insights into how to efficiently predict and scale inference capabilities!
Led by @RylanSchaeffer and in collaboration with a great team:
@JoshuaK92829, @jplhughes, @jordanjuravsky@sprice354_, @aengus_lynch1, @ErikJones313, @_robertkirk & @sanmikoyejo!
When studying repeated sampling in Large Language Monkeys, we found that the relationship between log(pass@k) and the number of samples often follows a power law. But *why* do we see this scaling law?
At first glance, this is surprising, since for a single problem pass@k and k are related by the CDF of the geometric distribution, not a power law. Why does a power law emerge when looking at pass@k over a dataset of many problems?
Check out this new preprint led by @RylanSchaeffer to find out!
The Great American AI Race. I wrote something about how we need a holistic AI effort from academia, industry, and the US government to have the best shot at a freer, better educated, and healthier world in AI. I’m a mega bull on the US and open source AI. Maybe we’re cooking something bigger… stay tuned or contact us.
(1/6) Joyously announcing ThunderKittens with real support on NVIDIA Blackwell! We've released BF16/FP8 GEMM and attention fwd+bwd kernels, up to 2x faster than cuBLAS GEMMs on H100. Blog: https://t.co/iadmRjj8II With @realDanFu, @AaryanSinghal4, and @hazyresearch!