I got curious how big pharmas today grew from once fledging biotechs.
Here’s 7 of the times it happened and the iconic blockbuster drugs that came along for the ride 👇
IT'S TIME FOR OFFENSE. We’re on the cusp of a Great Reawakening for startups. Companies that survived the Mass Extinction need to move decisively or risk being beaten by competitors. Here’s what’s changed & how to get *responsibly* aggressive.🧵/1
https://t.co/uVjXLYJY9N
This morning, Nature published two papers on bridge editing, the new genome engineering technology from @ArcInstitute: https://t.co/IL23V7nYoW, https://t.co/tOE10YZakn. I'm quite excited about its potential!
Since the whole thing is pretty arcane, I fed the blog post (https://t.co/tZZWNRUBdU) to Claude 3.5, and asked it to write an introduction. Below is the rather impressive (unedited) result.
Genome Design: The Bridge to Our Biological Future
I.
Imagine you're trying to edit a document, but instead of a cursor, you have a pair of scissors. You can cut out words you don't like, maybe paste in a few new ones, but precise editing? Forget about it. Now imagine someone hands you a pen. Suddenly, you can write whatever you want, wherever you want. This is the kind of leap we're seeing in the world of genome editing.
For the past few decades, we've been snipping away at genomes with tools like CRISPR, making impressive progress but always constrained by the fundamental nature of our tools: they cut DNA. But what if we could write directly into the genome, inserting whatever we want, wherever we want, without ever making a single cut?
This isn't just a "wouldn't it be nice" daydream anymore. Researchers at the Arc Institute have discovered a new system that does exactly that. They're calling it "bridge recombination," and it might just be the biggest revolution in genetic engineering since CRISPR.
II.
To understand why this is such a big deal, we need to take a quick tour through the history of genetic manipulation.
In the late 1990s, we discovered RNA interference (RNAi). This was our first real taste of programmable biology. We could use short RNA sequences to target and shut down specific genes. It was like having a universal remote control for gene expression. Cool, right?
Then came CRISPR in the early 2010s. Suddenly, we could not just turn genes off, but edit them directly. It was like upgrading from a remote control to a basic text editor. We could cut out bad genes and paste in good ones. But there was always a catch: CRISPR works by cutting DNA, and cells don't always repair those cuts exactly the way we want them to.
Both of these systems were revolutionary, but they shared a common limitation: they were destructive. They worked by breaking things – either the RNA transcripts of genes (in the case of RNAi) or the DNA itself (in the case of CRISPR).
III.
Enter the bridge recombination system.
The researchers at Arc Institute, led by Dr. Patrick Hsu, were poking around in the genomes of bacteria, looking at transposable elements. These are sometimes called "jumping genes" because they can cut themselves out of one part of a genome and paste themselves into another.
They were particularly interested in a group called IS110 elements. These are about as minimalist as you can get while still being functional – just a gene for the enzyme that does the cutting and pasting, plus some mysterious flanking DNA segments.
What they found was surprising. When an IS110 element cuts itself out of a genome, those mysterious flanking segments join up to form an RNA molecule. This RNA folds into two loops, one that binds to the IS110 element itself, and another that binds to the target DNA where the element will insert itself.
This RNA – which they've dubbed "bridge RNA" – is the key to the whole system. It's like a set of instructions, telling the enzyme exactly where to insert the DNA and what DNA to insert.
IV.
Now, you might be thinking, "Okay, that's neat, but how is this different from CRISPR?" The key is in how the insertion happens.
CRISPR works by making a cut in the DNA and then relying on the cell's repair mechanisms to insert the new DNA. It's effective, but it's also a bit like performing surgery with a chainsaw. Sometimes you get exactly what you want, but often you end up with small errors or unwanted insertions or deletions.
The bridge recombination system, on the other hand, doesn't cut the DNA at all. It unzips a small section, inserts the new DNA, and zips it back up again. No broken DNA strands, no relying on error-prone repair mechanisms. It's precise in a way that CRISPR can only dream of.
But the real magic is in the programmability. Remember those two loops in the bridge RNA? They can be programmed to recognize any DNA sequence. This means you can tell the system to insert any piece of DNA into any location in the genome. It's like having a word processor for DNA.
V.
The implications of this are staggering. Here are just a few possibilities:
• Gene Therapy 2.0: Current gene therapy approaches often rely on somewhat random insertion of therapeutic genes. With bridge recombination, we could insert corrective genes exactly where they need to go, without risking disruption of other important genes.
• Synthetic Biology: Want to give an organism a completely new capability? Just design the gene and insert it precisely where you want it.
• Evolutionary Biology: We could insert reporter genes at specific locations across the genome, allowing us to watch evolution happen in real time.
• Agricultural Improvements: We could insert beneficial genes into crops with unprecedented precision, potentially revolutionizing our ability to create drought-resistant or nutrient-enhanced plants.
• Bioengineering: Imagine being able to design and build entire genetic circuits, inserting each component exactly where it needs to be for optimal function.
VI.
In the grand scheme of things, the discovery of bridge recombination feels like a pivotal moment. It's as if we've been trying to write the book of life with a typewriter, and someone just handed us a word processor.
The researchers at Arc Institute have opened a door to a new era of genome design. As with any breakthrough of this magnitude, it's hard to predict exactly where it will lead. But one thing is certain: the future of biology just got a lot more interesting.
As we stand on the brink of this new frontier, I'm reminded of a quote from Arthur C. Clarke: "Any sufficiently advanced technology is indistinguishable from magic." With bridge recombination, we're not just editing the genome anymore. We're writing it. And that, my friends, is pretty close to magic.
What if we could universally recombine, insert, delete, or invert any two pieces of DNA?
In back-to-back @Nature papers, we report the discovery of bridge RNAs and 3 atomic structures of the first natural RNA-guided recombinase - a new mechanism for programmable genome design
2 months ago I wrote this thread on single cell GPT:
"Just as text is made of words, cells are characterized by genes"
scGPT sparked fascinating discussions about deep learning & mechanism in biology: where we stand & what lies ahead.
Now an improved version of this deep learning model just came out, incorporating feedback from the community!
Some thoughts below:
1. Main message: the main idea of this work is to draw a parallel between natural language processing (NLP) and single cell genomics. Biology has its own language. Even if complex and mysterious, this language does exist, and, most importantly, it can be learned.
Transformers applied on single cell data follow NLP methodology: pre-train universally, fine-tune on demand. Here, pre-training on a large corpus of single cells can provide a strong foundation to different downstream tasks.
2. Data: The scGPT model is pre-trained on 33 Million normal human cells from 51 tissues and 441 studies, available from CELLxGENE (https://t.co/LBgoL8cuUx). Fine-tuning happens on smaller datasets. The paper confirms what was intuitively obvious, and previously observed: larger pre-training data leads to significant improves in performance. This means that the potential for improvement and discoveries is huge with more and more sequencing data available.
3. Tasks: scGPT 2.0 is employed on the following tasks
A. Cell type annotation
This is community's favorite task (sarcasm). Lots has been said (and done) on cell type annotation and tens of great models are out there. Still, no matter what you do or how you do it, it's never perfect, and all models are meant to fail on annotating cell types, one way or another. Some things to note about scGPT2.0:
-- performance is generally great (as with other tools, s.a. scBERT)
-- rare cell types are a real problem (by definition, no training data means no way to predict). I believe we should leave rare cell types prediction/validation to experimentalists.
-- pre-training on normal cells + fine-tuning on tumor-infilitrating immune cells in cancer data leads to good immune cell type annotation in unseen cancer types. this is an encouraging start and definitely a relevant direction, but its utility on cancer applications is still marginal and far from clinical relevance.
B. Genetic perturbation prediction
The game here is to learn from known gene perturbation experiments and generalize to predicting responses in unseen scenarios. scGPT2.0 was fine-tuned on a subset of perturbations and tested on perturbations of unseen genes.
-- its performance is very good & similar to other tools (GEARS and CPA)
-- reverse perturbation prediction is interesting: given unseen perturbed cell states, scGPT can predict the genes which are the source of perturbation. this can have applications for understanding disease causality, even though real-life causality is much more complex than PerturbSeq-type experiments.
C. ScRNAq data integration
Another community favorite (another sarcasm). No matter how you do it, and whether you do it or not, it's meant to be wrong. By definition, integration strips away biological variability for many real-life scenarios (especially disease-related). Still, integration has great utility for building reference atlases of normal cells. Conceptually, integration is best meant to properly utilize the large corpus of existing data and remove technical batch effects.
-- scGPT2.0 does well here also, when compared to scVI, Seurat and Harmony (all 3 very popular single cell integration tools). It is applied on immune, Covid, and brain data.
D. Multi-omics integration
In the genomics field, there has long existed the hope that querying a biological system across different facets (omics) can provide complementary information, and build a more profound understanding of the system than single facets (omics) alone.
-- scGPT does integration of joint expression & chromatin accessibility (PBMC) and performs well
-- while multi-omics integration is the natural way forward for understanding biology, the data is still noisy & limited. transformers-like models are ideally suited to make use of multi-modal data. in my view, this is a main direction of future improvement & insights.
E. Gene Regulatory Networks
Inferring such networks is relevant for understanding complex biological processes that are perturbed in disease, and knowing where (and how) to intervene. When fed in with the expression of millions of cells during pre-training, scGPT inherently learns the relationships between transcription factors, enhancers and gene targets. Attention masks also naturally further improve the learning of gene-gene interactions.
-- scGPT2.0 is validated on this task by comparing the gene networks it extracts with known biology, both qualitatively as well as quantitatively (e.g. pathway analysis). its results are biologically relevant.
-- it's interesting to note that transformers attention mechanisms are particularly important here and well-suited on gene regulatory network prediction tasks.
-- predicting cell type-specific or perturbation-specific maps has great future potential.
scGPT2.0 is a great read, here's the preprint if you want to dive deeper:
https://t.co/R3rSOaeUxI
Congrats to @BoWang87 for this awesome work, for making the models and code available, and for iterating so quickly on an important problem.
Multi-agent collaboration has emerged as a key AI agentic design pattern. Given a complex task like writing software, a multi-agent approach would break down the task into subtasks to be executed by different roles -- such as a software engineer, product manager, designer, QA (quality assurance) engineer, and so on -- and have different agents accomplish different subtasks.
Different agents might be built by prompting one LLM (or, if you prefer, different LLMs) to carry out different tasks. For example, to build a software engineer agent, we might prompt the LLM: "You are an expert in writing clear, efficient code. Write code to perform the task …".
It might seem counterintuitive that, although we are making multiple calls to the same LLM, we apply the programming abstraction of using multiple agents. I'd like to offer a few reasons:
- It works! Many teams are getting good results with this method, and there's nothing like results! Further, ablation studies (for example, in the AutoGen paper cited below) show that multiple agents give superior performance to a single agent.
- Even though some LLMs today can accept very long input contexts (for instance, Gemini 1.5 Pro accepts 1 million tokens), their ability to truly understand long, complex inputs is mixed. An agentic workflow in which the LLM is prompted to focus on one thing at a time can give better performance. By telling it when it should play software engineer, we can also specify what is important in that subtask: For example, the prompt above emphasized clear, efficient code as opposed to, say, scalable and highly secure code. By decomposing the overall task into subtasks, we can optimize the subtasks better.
- Perhaps most important, the multi-agent design pattern gives us, as developers, a framework for breaking down complex tasks into subtasks. When writing code to run on a single CPU, we often break our program up into different processes or threads. This is a useful abstraction that lets us decompose a task -- like implementing a web browser -- into subtasks that are easier to code. I find thinking through multi-agents roles to be a useful abstraction.
In many companies, managers routinely decide what roles to hire, and then how to split complex projects -- like writing a large piece of software or preparing a research report -- into smaller tasks to assign to employees with different specialties. Using multiple agents is analogous. Each agent implements its own workflow, has its own memory (itself a rapidly evolving area in agentic technologies -- how can an agent remember enough of its past interactions to perform better on upcoming ones?), and may ask other agents for help. Agents themselves can also engage in Planning and Tool Use. This results in a cacophony of LLM calls and message passing between agents that can result in very complex workflows.
While managing people is hard, it's a sufficiently familiar idea that it gives us a mental framework for how to "hire" and assign tasks to our AI agents. Fortunately, the damage from mismanaging an AI agent is much lower than that from mismanaging humans!
Emerging frameworks like AutoGen, Crew AI, and LangGraph, provide rich ways to build multi-agent solutions to problems. If you're interested in playing with a fun multi-agent system, also check out ChatDev, an open source implementation of a set of agents that run a virtual software company. I encourage you to check out their github repo and perhaps even clone the repo and run the system yourself. While it may not always produce what you want, you might be amazed at how well it does!
Like the design pattern of Planning, I find the output quality of multi-agent collaboration hard to predict. The more mature patterns of Reflection and Tool use are more reliable. I hope you enjoy playing with these agentic design patterns and that they produce amazing results for you!
If you're interested in learning more, I recommend:
- Communicative Agents for Software Development, Qian et al. (2023) (the ChatDev paper)
- AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation, Wu et al. (2023)
- MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework, Hong et al. (2023)
[Original text: https://t.co/4gTbcQfikx ]
Rubrik, a Palo Alto-based data security company, filed their S-1 yesterday. At $784m in ARR, growing 47% with 130% net revenue retention across 6100 customers, the company should be one of top 10 fastest growing software companies alongside Klaviyo, ZScaler, & Crowdstrike - in ARR terms.
Half of new customers are over $100,000 in size & contract values have grown 19% from $101k to $120k in a year. 41% of new bookings derives from those new customers.
But overall revenue is growing 4.5% y/y, estimated sales efficiency is 0.11, & contribution margins are negative : Rubrik sells $1 of subscription software for $0.88.
How can ARR grow so quickly while overall revenue is much slower? & why would a software company run negative contribution margins?
It’s a strategic imperative to metamorphose from an on-premises perpetual-license company to a subscription-software company as fast as possible.
In fiscal 2023, we began transitioning customers from our legacy CDM (Cloud Data Management) capabilities to our subscription-based RSC offerings. As a result of differing revenue recognition treatment between CDM and RSC (Rubrik Security Cloud), this business transition will cause fluctuations to our total revenue growth and limit the comparability of our revenue with past performance.
The company’s subscription revenue increased from $385 to $538 million with a gross margin of 81-83%. The legacy business fell by 58%. Note the substantially lower margins of 44-47%.
However, the most curious part of the business is the margin structure.
The tldr : Rubrik is a top 10 growth software company with higher-than-average gross margins, lower-than-average profitability, on-par cash-flow-from-ops margins, & negative contribution margins.
It’s the contribution margin that sticks out.
Contribution margin is the unit profit generated from a marginal license sold : it’s -12%. This means the more software sold, the more money the company loses. The contribution margin has improved from -117% in 2022, to -38% in 2023, to -12% in 2024.
For most software companies, contribution margin is typically very high, around 80-90%.
This is a burn-the-boats strategy which requires a lot of courage, a phenomenal commitment to the long term, & a big balance sheet to sustain the short-term losses & invest in a new product & new sales & marketing strategy to transform a massive caterpillar into an even bigger butterfly.1
The company is well on its way to becoming a pure software business & with the margin trends improving, the big bet may come to fruition.
Congratulations to the entire team at Rubrik on building a massive business with a daring strategy!
I know, I know. I’m mixing metaphors.
How 9 months of building without success, 2 difficult pivots, and dozens of rejections resulted in @loom:
In reflecting back on the last 8 years, and investing in 40+ companies, I've become convinced that the most common pitfall for founders is investing too much time on finding the ‘perfect’ solution to their idea.
This thread covers the story of Loom—and why you'll likely start with an imperfect idea before landing on your winner:
Loom didn’t begin as Loom.
It started around a whiteboard with Vinay, Joe, and myself. We wrote down six ideas, and went with the solution we thought was perfect:
A user testing marketplace. We began building.
7 months in, we only made $600, but learned an important lesson:
Companies generally cared less about advice from experts (what we were selling). Instead, they wanted to hear directly from their own users.
We pivoted. The new idea?
Build a SaaS offering that’d let companies get direct feedback from *their own users*.
As Vinay started to rebuild the product, Joe and I spent weeks cold emailing 300 different companies offering a free trial...
Soon after—we heard back from a research team at Harvard.
They used our product (called OpenTest at the time) to gather insights from 7 students for a campaign.
As a result—they received 7 different videos with various insights.
Instead of sharing these videos back with the entire research team...
Someone at Harvard used the same Chrome extension (built originally for the user testers themselves)
to record a 1-minute summary of the 7 videos.
This 1-minute video was shared back with their team.
This wasn’t how our product was supposed to be used.
Yet it was a valuable insight: We realized that people were more interested in using Loom as a communication tool.
When we were able to realize that...
We took the screen and video recording extension, launched it on Product Hunt in June 2016, and had 3,000 people sign up on the same day.
Which was 2,990 more users than we’d had in the 9 months prior.
A couple things one can take away from our experience:
First, de-stress yourself from “finding the perfect idea”.
It’s impossible to predict how things will go once you start—and it’s better to start and adapt than never launch because you’re worried something won’t work.
Just like baking, playing guitar, or learning a sport, coming up with the perfect startup idea is something you likely won't get right on your first attempt.
Second, the four traits that got us to Loom were:
1) Timing of the market
2) Camaraderie
3) Intense focus
4) Pure luck
We were in a period where remote work was early, but not a foreign concept.
We enabled a ‘trust by default’ mentality amongst the team. With a common goal, we celebrated outputs that drove real results. This contained our own bias and ego.
We limited distractions, even the shiny ones (investor meetings, meetups, high-value dinners in SF, etc) and chipped away at finding product-market fit.
Lastly, with all this effort, we were fortunate to find some luck along the way that made things a bit easier for us.
That’s the story of how we came up with Loom: An idea that worked, after a couple that didn’t.
For the past few weeks, I’ve been spending more time with founders on getting their V1 out, helping discover growth opportunities, fundraising, and advising as founders go from 0-1 as well as those scaling from 1-2.
I'm opening a few slots to work with me 1:1 for the next 3-4 months.
Criteria:
- You're a Founder or CEO
- You're building in B2B SaaS or Consumer
Reply below and I'll share my booking link.
Frank Slootman really is the business version of a Navy Seal.
And when a CEOs retirement prompts a $17 billion loss in market cap, it's worth understanding.
I reread his original 2018 Amp It Up essay & these were my favorite passages:
Claude 3 gets ~60% accuracy on GPQA. It's hard for me to understate how hard these questions are—literal PhDs (in different domains from the questions) with access to the internet get 34%.
PhDs *in the same domain* (also with internet access!) get 65% - 75% accuracy.
Anthropic is so back. Two things I like the most about Claude-3's release:
1. Domain expert benchmarks. I'm much less interested in the saturated MMLU & HumanEval. Claude specifically picks Finance, Medicine, and Philosophy as expert domains and report performance. I recommend all LLM model cards to follow this, so that the different downstream applications know what to expect.
2. Refusal rate analysis. LLMs' overly cautious answers to innocent questions are becoming a pandemic. Anthropic is typically on the ultra safe end of the spectrum, but they recognize the problem and highlight their efforts on it. Bravo!
I love that Claude dials up heat in the arena that GPT and Gemini dominate. Though keep in mind that GPT-4V, the high water mark that everyone desperately tries to beat, finished training in 2022. It's the calm before the storm.
If you don't have 1-2 hours to listen to a podcast episode, I'm now adding some key takeaways from my conversations inside the show notes.
You'll find them below the episode description.
Here's an example from my chat with @geoffreyamoore:
There are some important changes underfoot in private markets:
1. Returns are compressing - few funds are able to consistently achieve the necessary spread over the risk-free rate to justify fees and illiquidity.
2. LPs are segregating bi-modally: 1) a growing group of smaller family offices, Fund of Funds and Endowments (<$10B) and 2) a group of massive investors (> $50B) but each with much more money than ever imagined.
This is creating a situation where the leverage is shifting to LPs. This is on top of an existing trend where, at the same time, leverage has been shifting away from GPs to founders/entrepreneurs already.
This is catching GPs in an increasingly hard game where their historical value capture is eroding. This is seen through their deals with LPs and Founders:
1. Lower fees
2. Lower carry
3. Higher hurdle rates
4. Lower ownership in winning companies
5. Lower terminal value of their enterprise when the sell a share to secondary firms
In short, the edge is leaking away.
This will be least felt in two areas of the market. 1) Early stage venture capital where despite the deflationary nature of tech investing, deal flow is still somewhat proprietary and some GPs have a brand of adding differentiated value such that they are consistently sought out (@vkhosla, @DavidSacks, @laserlikemike are good examples). 2) capital intensive areas where there is a NEED (vs desire) to raise ever increasing funds because of the scale of the project (infrastructure funds are the most obvious example of this).
But for the rest, including venture growth, traditional private equity, hedge funds, credit funds etc LPs will slowly turn the screws on GPs to extract better and better terms for themselves in return for them to subscribe to new funds.
Side note 1: Secondary firms used to buy GP shares of all kinds of firms at a premium. These deals never made sense except to inaccurately inflate the ego and the balance sheet of the GP. Said differently, like many of the companies GPs have invested in over the years, these valuations are neither real nor realizable in real life.
Side note 2: GIP selling themselves this week to BlackRock for $12.5B (or 12% of NAV) is a great example of where value can still being created.
Side note 3: The long term antidote for GPs is for more of them to invest their own balance sheet with increasingly limited outside capital in the areas that are working. In VC, Sequoia’s early stage fund and Sutter Hills fund are two good examples.
1⃣. Inference Speed of Protein Structure Models 🐎
Usually, the accuracy of #protein structure prediction models (e.g. AlphaFold, ESM) is the central concern (for good reason).
Model speed can be just as critical a parameter, though.
It's all to do with throughput and cost.
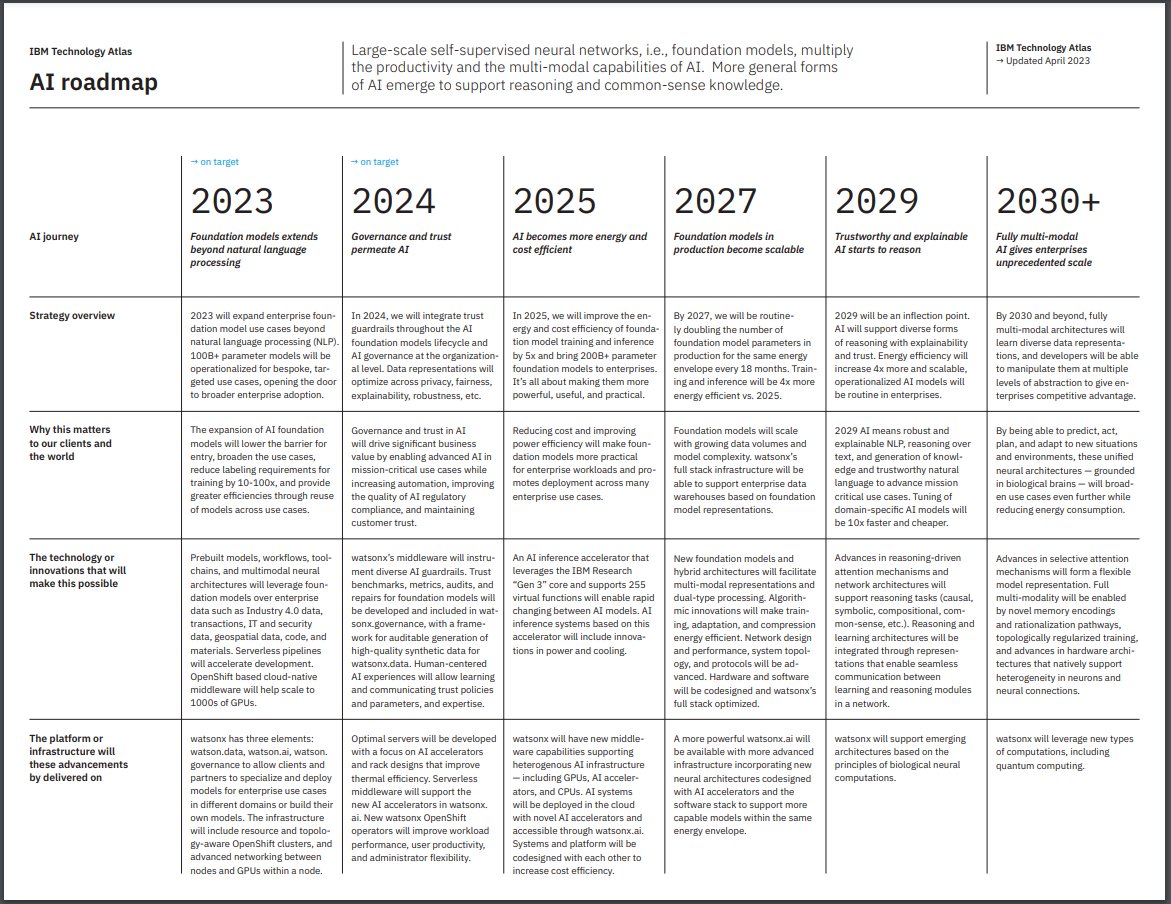
At IBM we created an AI Roadmap for the next few years. Folks... check what is coming:
𝟮𝟬𝟮𝟯: 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗺𝗼𝗱𝗲𝗹𝘀 𝗲𝘅𝘁𝗲𝗻𝗱𝘀 𝗯𝗲𝘆𝗼𝗻𝗱 𝗻𝗮𝘁𝘂𝗿𝗮𝗹 𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗽𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴.
In 2023, it will expand enterprise foundation model use cases beyond natural language processing (NLP). 100B+ parameter models will be operationalized for bespoke, targeted use cases, opening the door to broader enterprise adoption.
𝟮𝟬𝟮𝟰: 𝗚𝗼𝘃𝗲𝗿𝗻𝗮𝗻𝗰𝗲 𝗮𝗻𝗱 𝘁𝗿𝘂𝘀𝘁 𝗽𝗲𝗿𝗺𝗲𝗮𝘁𝗲 𝗔𝗜
In 2024, we will integrate trust guardrails throughout the AI foundation models lifecycle and AI governance at the organizational level. Data representations will optimize across privacy, fairness, explainability, robustness, etc.
𝟮𝟬𝟮𝟱: 𝗔𝗜 𝗯𝗲𝗰𝗼𝗺𝗲𝘀 𝗺𝗼𝗿𝗲 𝗲𝗻𝗲𝗿𝗴𝘆 𝗮𝗻𝗱 𝗰𝗼𝘀𝘁 𝗲𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝘁
In 2025, we will improve the energy and cost efficiency of foundation model training and inference by 5x and bring 200B+ parameter foundation models to enterprises. It’s all about making them more powerful, useful, and practical.
𝟮𝟬𝟮𝟳: 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗺𝗼𝗱𝗲𝗹𝘀 𝗶𝗻 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗯𝗲𝗰𝗼𝗺𝗲 𝘀𝗰𝗮𝗹𝗮𝗯𝗹𝗲
By 2027, we will be routinely doubling the number of foundation model parameters in production for the same energy envelope every 18 months. Training and inference will be 4x more energy efficient vs. 2025.
𝟮𝟬𝟮𝟵: 𝗧𝗿𝘂𝘀𝘁𝘄𝗼𝗿𝘁𝗵𝘆 𝗮𝗻𝗱 𝗲𝘅𝗽𝗹𝗮𝗶𝗻𝗮𝗯𝗹𝗲 𝗔𝗜 𝘀𝘁𝗮𝗿𝘁𝘀 𝘁𝗼 𝗿𝗲𝗮𝘀𝗼𝗻
2029 will be an inflection point. AI will support diverse forms of reasoning with explainability and trust. Energy efficiency will increase 4x more and scalable, operationalized AI models will be routine in enterprises.
Large-scale self-supervised neural networks, i.e., foundation models, multiply the productivity and the multi-modal capabilities of AI. More general forms of AI emerge to support reasoning and common-sense knowledge.
Get ready, we are just getting started!
Tweetorial time! We @RecursionPharma mapped consequences of #CRISPR screening of >17K human genes, found a systematic bias confounding all CRISPR screens, traced its molecular cause, and propose a debiasing algorithm.
Two landmark publications came out today: one on the use of Google's Deep Mind to simulate millions of new possible materials, the other describes and autonomous self driving robotic laboratory to synthesize the materials prediction by DeepMinds simulations.
Just the beginning
“You have to decide what your highest priorities are and have the courage—pleasantly, smilingly, non apologetically, to say ‘no’ to other things. And the way you do that is by having a bigger ‘yes’ burning inside."
--Stephen Covey