OS framework to build applications that make decisions: chatbots, agents, simulations, etc. Monitor, trace, persist, & execute in #python. Run by @TheASF
Burr: build applications that make decisions: #chatbots, #agents, #simulations, etc.
Monitor, trace, persist (memory), & execute in #python. Lots of🔌. Comes with a UI. #opensource
https://t.co/knR9GVYRnF
https://t.co/6iEFUfrkqe
https://t.co/rywpb0cBQN
https://t.co/ITxkv81VhH
User spotlight: SRE Agent, Theodosia mounts a Burr Application as an MCP server — AI agents pick transitions through tool calls, illegal moves are refused with structured errors, and the full Burr observability stack comes free. Clean design by
@msradam 👏
https://t.co/d4uMBqveIY
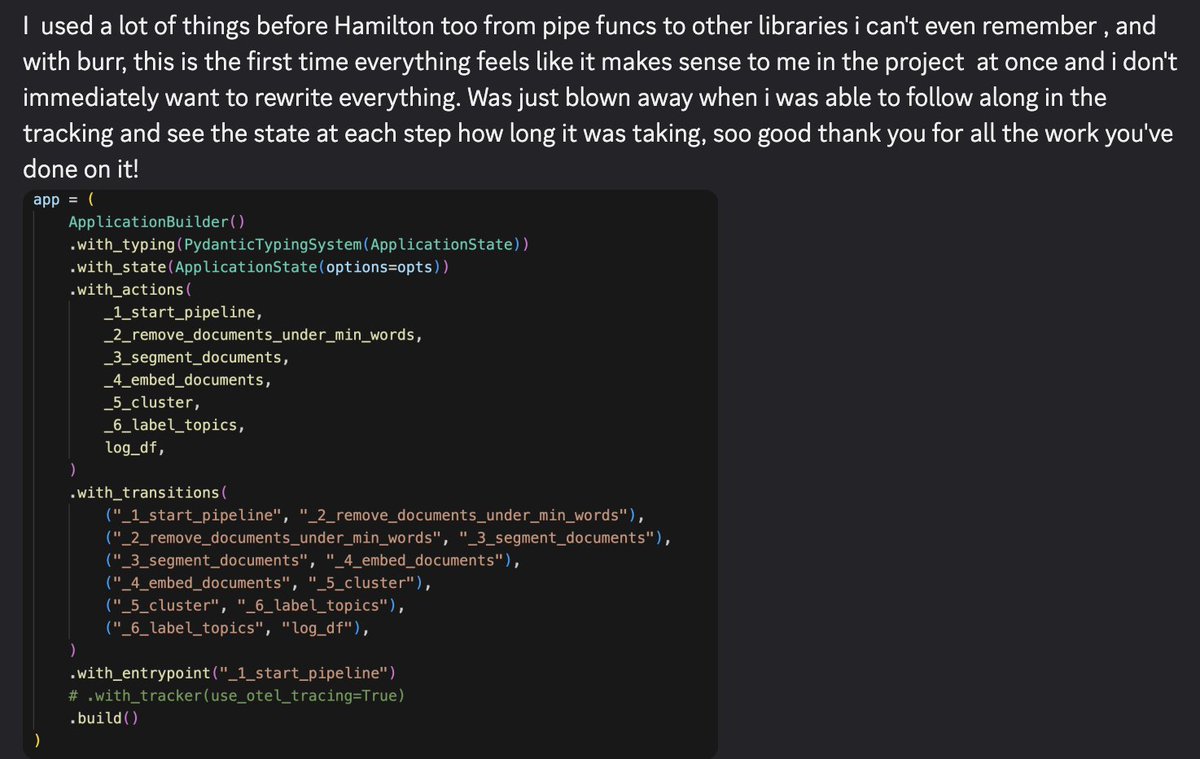
For once I actually agree with the constructive argument here. There are more approaches that allow you to own your own destiny. Memory is just context after all and you can provide that at many places of the agent while loop. Check out @burr_framework and of course @agentforce
Things I hear in private circles: "even the CEOs of @langchain and @llama_index say there is little value in abstracting over LLM API calls".
If you haven't been following Apache @hamilton_os or Apache @burr_framework that's exactly what we've been saying for years -- you need to own the LLM call -- why? because customization here is what is going to deliver value, not the POC you threw together with those overly abstract VC backed frameworks.
Plug (1): building on Apache Hamilton &/or Apache Burr is a better investment because you can drive the direction.
Plug (2): @hugobowne and I cover this our @MavenHQ course -https://t.co/7yDRzMlyrM
Check out the latest article in my newsletter: February Updates https://t.co/CH4viGqTl2 via @LinkedIn@hamilton_os:
- crosses 2K⭐️
- installs in @pyodide envs
- mutlithreaded parallel DAG execution
@burr_framework:
- crosses 1.5K ⭐️
- async persister implementations
- tag aliases for actions
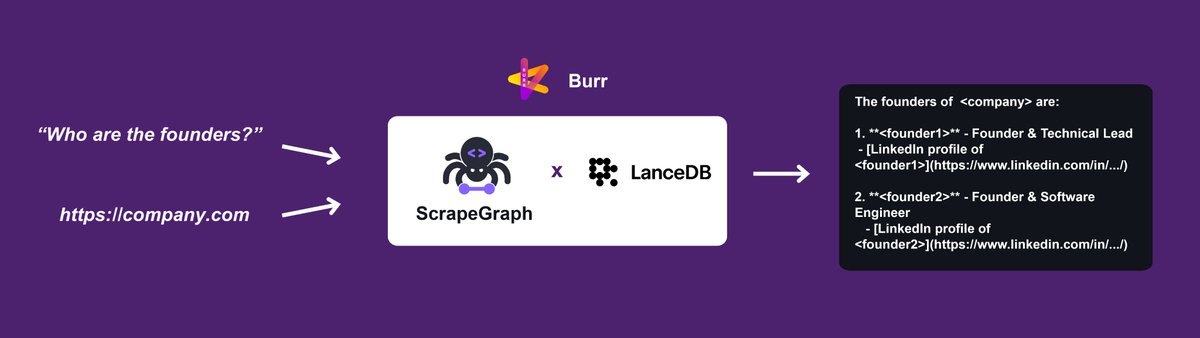
📣 New blog post! Chat with your webpage with
@scrapegraphai, @burr_framework and @lancedb
https://t.co/QtjBSEYixP
TL;DR: a great post showing the use of lightweight tools that are "orchestrated" and "observed" with Burr.
My 8000-word note on agents: https://t.co/uELWfPtS9N
Covering:
1. An overview of agents
2. How the capability of an AI-powered agent is determined by the set of tools it has access to and its capability for planning
3. How to select the best set of tools for your agent
4. Whether LLMs can plan and how to augment a model’s capability for planning
5. Agent’s failure modes
AI-powered agents are an emerging field with no established theoretical frameworks for defining, developing, and evaluating them. This post is a best-effort attempt to build a framework from the existing literature, but it will evolve as the field does.
As always, feedback is much appreciated!
@braelyn_ai Once you get into CI build systems, it's very easy to rack up downloads. E.g. someone puts in a PR, it triggers a CI run that downloads the library fresh. Boom lots of downloads.
Check out the latest article in my newsletter: Last week of 2024 / first week of 2025
@hamilton_os@burr_framework stats:
> 35M+ telemetry events (10x growth),
> 100K+ unique IPs (10x growth) from 1000+ companies,
> crossed 1M+ total downloads.
More in the newsletter!
https://t.co/mDj3VV62zk via @LinkedIn
Super excited to show @anyscalecompute 's @raydistributed integration with Burr.
What it is? It enables you to distribute "agents" (well sub-graphs) as tasks on Ray, along with fault tolerance!
Read more about it here:
https://t.co/rtTGVd3jse
Want some light reading? Well how about a post on how you might use @pytestdotorg for your LLM / Agent application work? Would love feedback / comments.
👉 Test Driven Development (TDD) of LLM / Agent Applications with @pytestdotorg & @burr_framework https://t.co/3WjAA5eaQL
💬Chat with your webpage cookbook is out! 💬
It uses @scrapegraphai to extract the webpage content, @lancedb to vector store it and retrieve the most relevant chunks and @DagWorks@burr_framework to orchestrate everything 🚀
Try it out: https://t.co/rOIpGIx7KB
New blog 📣: our write up on our approach to "parallelism" for Augmented LLMs through to Multi-agent workflows. For those curious, yes it differs from LangGraph's implementation methodology. Read on to find out more!
https://t.co/RUSlwSW69v
#AgentOps#LLMOps#Opensource#python
Tired of the deployment headaches with #LLM agents? #BentoML takes care of the heavy lifting - from REST endpoints to scaling. Great post by Thierry Jean from @DagWorks showing how to combine #Burr and BentoML for streamlined agent deployment! Read the blog post to learn more: https://t.co/LfcxcNsPpy
Check out the latest article in my newsletter - highlights:
@hamilton_os:
- async @datadoghq tracer for async Hamilton
- @pandas_dev@DataPolars with_columns support
@burr_framework:
- Persistence configurability for parallelism.
See more here:
https://t.co/n7qCSls5FI via @LinkedIn
Super excited for this post by @thierryjean that provides a well laid out golden path for folks iterating in the #GenAI space.
This follows up from my tweet yesterday about framework coupling. If the framework allows loose coupling, then graduating out of it isn't a thing you'll run into. In this post Thierry lays out to use Burr and how it doesn't get in your way as you build more complex and sophisticated workflows and agents.
https://t.co/I5QBgdMTZT
A @burr_framework user shared this video https://t.co/Nj1P3XO1DB with me on the "problem with frameworks". Worth a watch.
I 💯% agree with the take home. The "coupling problem" is the reason why people graduate out of frameworks like @langchain & @llama_index. You become overly coupled and then find yourself overtime asking why am I using this? It's not that the framework authors did this maliciously, it's just that they optimized for their needs, in this case for POCs, which is not the same as long lived maintainable code.
That's why we see people either build their own frameworks, or they hopefully discover @hamilton_os & @burr_framework and realize that there are frameworks that allow "loose coupling" that don't get in your way (as a platform person and framework author we optimize for maintainable code). A good example of this is @FastAPI - very easy to not couple your business logic and iterate quickly no matter the age of the code.
So how can you tell where a framework lies on the spectrum of tight coupling versus not? Some tests:
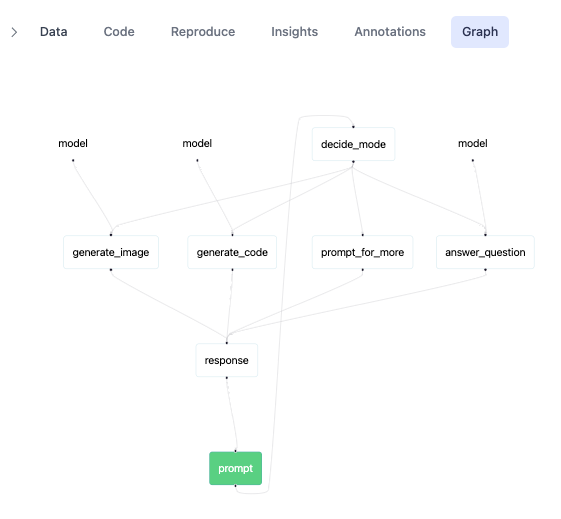
(1) How many "objects" do I need to use from the framework to couple the logic I want to happen? The fewer the better. E.g. with @hamilton_os by default it's 0. With @burr_framework it's just 1 and that's due to state for edge transitions, but that's easy to decouple from.
(2) How many framework imports do you need to get something to run? The less the better - consider @burr_framework vs @langchain using #langgraph (see images)
If you're feeling framework pains, or are curious on how it can be done right, checkout:
https://t.co/V2upxqMWIe (agents) https://t.co/URcmWGB3zX (pipelines/tools) or subscribe to our blog - https://t.co/DJOEf9vhli
#python #opensource #genai #llmops
💫 Humbled to have nearly 250 registrants for my free LLM Software Dev Lifecycle 30 min primer with @stefkrawczyk on @MavenHQ (and great to feel there's interest in what I currently want to teach!) 🤖
You can still register below and this is the lifecycle we'll be going through 👇
https://t.co/cF0rEQFwu8
@latentspacepod@_anshulr Yep that's why @hamilton_os and @burr_framework observability is built in & pluggable by design, so you can offer all the trappings for enterprise without having to engineer for it later; graph / flowchart mental models FTW!