long-lived species and humans living 100+ years are known to have increased DNA repair capacity
but how DNA repair could be boosted to extend human lifespan is largely unknown
our research in Nature Aging today proposes a target to enable such a boost: the DREAM complex
Today, we’re excited to share mRNAutilus, our experimentally-validated framework for multi-objective generation of full-length mRNAs, jointly optimizing coding sequences and UTRs for expression, stability, and translation!⚓️
📜: https://t.co/jld3bjXIOH
💻: https://t.co/z2K4l60THy
Today we're announcing ESMFold2, an open scientific engine to power prediction, design, and discovery across protein biology.
The new model delivers state of the art performance on protein interactions, especially antibodies, a critical modality for therapeutics.
We have designed and validated miniprotein binders and single chain antibodies across five therapeutic targets that are important in cancer and immunology. We are seeing very high success rates, and affinities at levels consistent with therapeutic activity.
We’re also releasing an atlas of 6.8 billion proteins, and 1.1 billion predicted structures.
ESMFold2 is built on a state of the art language model that has been trained on billions of protein sequences.
A world model of protein biology emerges through language modeling.
We’ve used the techniques of mechanistic interpretability developed to understand large language models to understand the concepts ESM uses to represent proteins.
The model’s representation space has a compositional organization of features across scales, levels of complexity, and abstraction, that reflects and mirrors the understanding of protein biology developed through a century of empirical science.
This understanding emerges without prior knowledge, just from language modeling of protein sequences.
Language models are becoming a powerful substrate to understand and program biology.
The design of protein interactions is one of the most fundamental problems in biophysics, and has critical implications for the discovery of new medicines. A simple gradient based search with the model was able to discover high-affinity protein binders.
I'm excited by the potential this has to accelerate basic science and the understanding of proteins. And especially for the new avenues it opens up for therapeutic design and medicine.
NEW preprint: Sparse autoencoders were trained on ESM-2 (650M, seq-only) and ESM-3 (1.4B, multimodal) to ask a simple question -- when two protein language models look at the same protein, do they "see" the same biology?
Answer: Yes, mostly
Foundation models come to mass spectrometry proteomics
Identifying proteins from their fragments is a foundational task in biology. A mass spectrometer breaks peptides into pieces, measures the masses, and software then tries to match each spectrum back to a peptide sequence. Two approaches have dominated for decades: database search (match against known proteomes) and de novo sequencing (infer the peptide directly from the spectrum). Both are bottlenecked by the same step, scoring how well a candidate peptide explains a spectrum.
Deep learning has been entering this field for years, mostly as feature extractors feeding traditional engines like MaxQuant or MSFragger.
Jiale Zhao and coauthors introduce pUniFind, is a multimodal foundation model trained on over 100 million peptide-spectrum matches from open database searches. Spectra and peptides get their own encoders, and the model is pretrained with cross-modality tasks: predict the spectrum from the peptide, predict the peptide from the spectrum, score peptide-spectrum pairs jointly. Database search and de novo sequencing become two views of the same model.
The numbers are remarkable. In immunopeptidomics, where peptides come from non-tryptic digestion and are very hard to identify, pUniFind finds 42.6% more peptides than Open-pFind. In modification-rich de novo sequencing, it identifies 60% more peptide-spectrum matches than existing methods, despite working in a 300 times larger search space. In regular de novo, it recovers 38.5% more peptides, including 1,891 that map to the human genome but are absent from reference proteomes. A deep learning quality control filter raises consistency with RNA-Seq evidence from 65.4% to 85.0%.
What makes this an ML story is the architecture choice. End-to-end scoring with a shared latent space replaces hand-crafted feature pipelines, and the same backbone serves both database search and de novo sequencing without retraining.
For drug discovery, immunotherapy, and antibody engineering, peptide identification is the bottleneck for neoantigen discovery and biomarker pipelines. Tools that find more peptides at the same FDR, especially in non-tryptic and modification-rich settings, expand what is detectable from existing data. That changes what is worth running in the lab.
Paper: Zhao et al., Nature Machine Intelligence (2026) — journal license | https://t.co/U05n5GbjZR
I just sequenced a human genome to 30× coverage entirely at home.
As far as I know, this is the first time this has been done.
I didn’t step foot in a lab once. Every step - from saliva collection, to running the sequencer - took place in a single room with a dining table + kitchenette.
Six weeks ago, I had never done wet lab biology before.
I used an Oxford Nanopore P2 Solo - the only commercially available sequencing device portable enough to do 30x human genome sequencing at home.
Biggest takeaway - I could build something that combined software, hardware, and molecular biology far faster than I thought was possible.
I can name >100 specific instances where AI helped me solve a technical problem that would previously have blocked me because I lacked access to a domain expert.
For example: how do I save my sequencing run when my DNA extraction yield is 4x lower than I need it to be, and I have this limited set of reagents to hand?
To make this work, I had to navigate multiple disciplines:
- writing software to monitor sequencing runs and orchestrate remote GPU infra for basecalling
- learning + executing 5 hour long molecular biology protocols
- building a hardware device to quantify DNA concentration
Apologies for the hyperbole, but I feel super lucky to be living in 2026.
A few weeks ago I decided to sequence a human genome to 30x at home.
Then I actually did it. And I did it really quickly.
A plasmid toolbox for the easy autodisplay of recombinant proteins and its optimization
"a toolbox of 81 plasmids, accessible by Addgene, facilitates tailor-made surface display of proteins in bacteria"
https://t.co/1cCKiDPA50
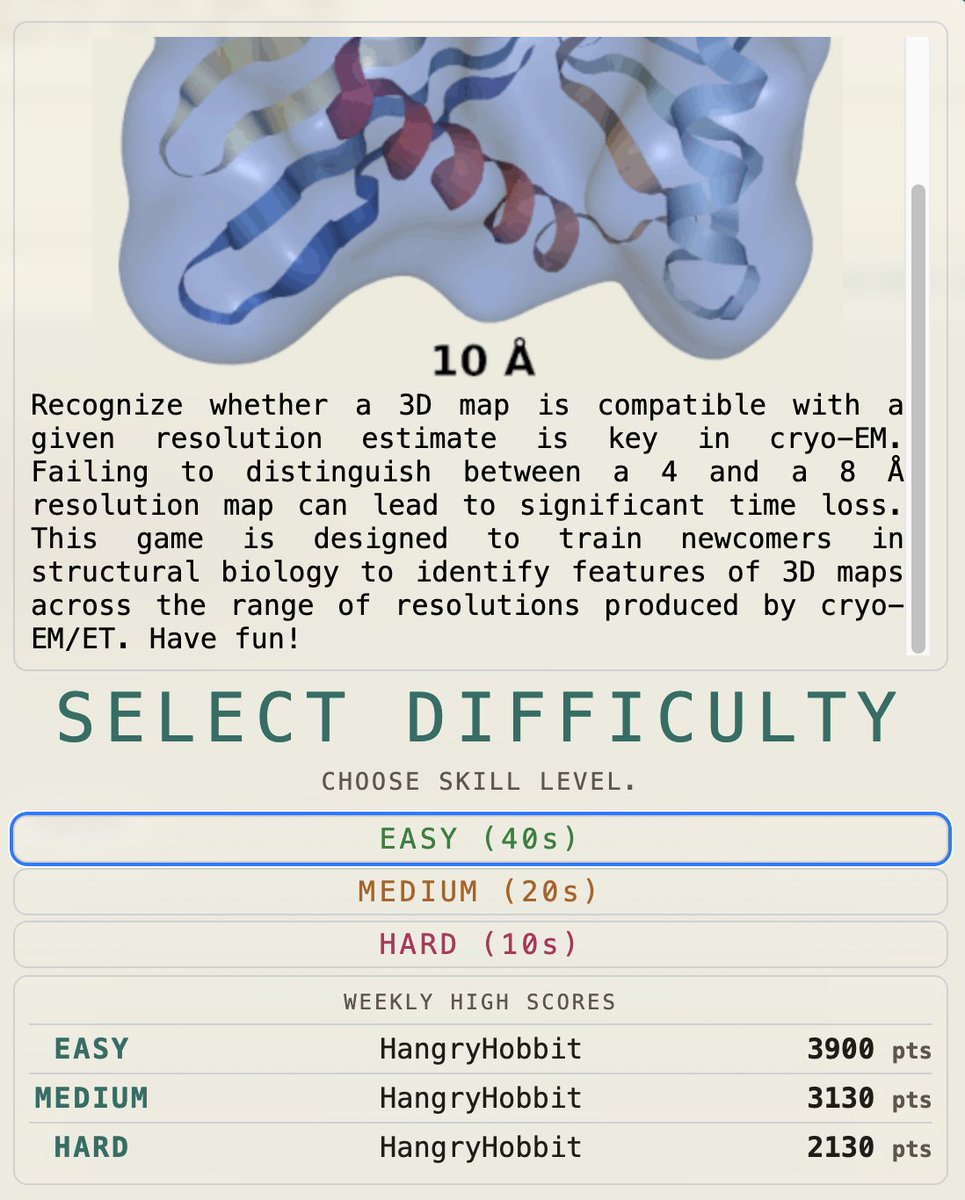
Try this new online training game from Leandro F. Estrozi designed for newcomers in structural biology, with a focus on cryo-EM and cryo-ET map interpretation: https://t.co/gxhQXmRPWL
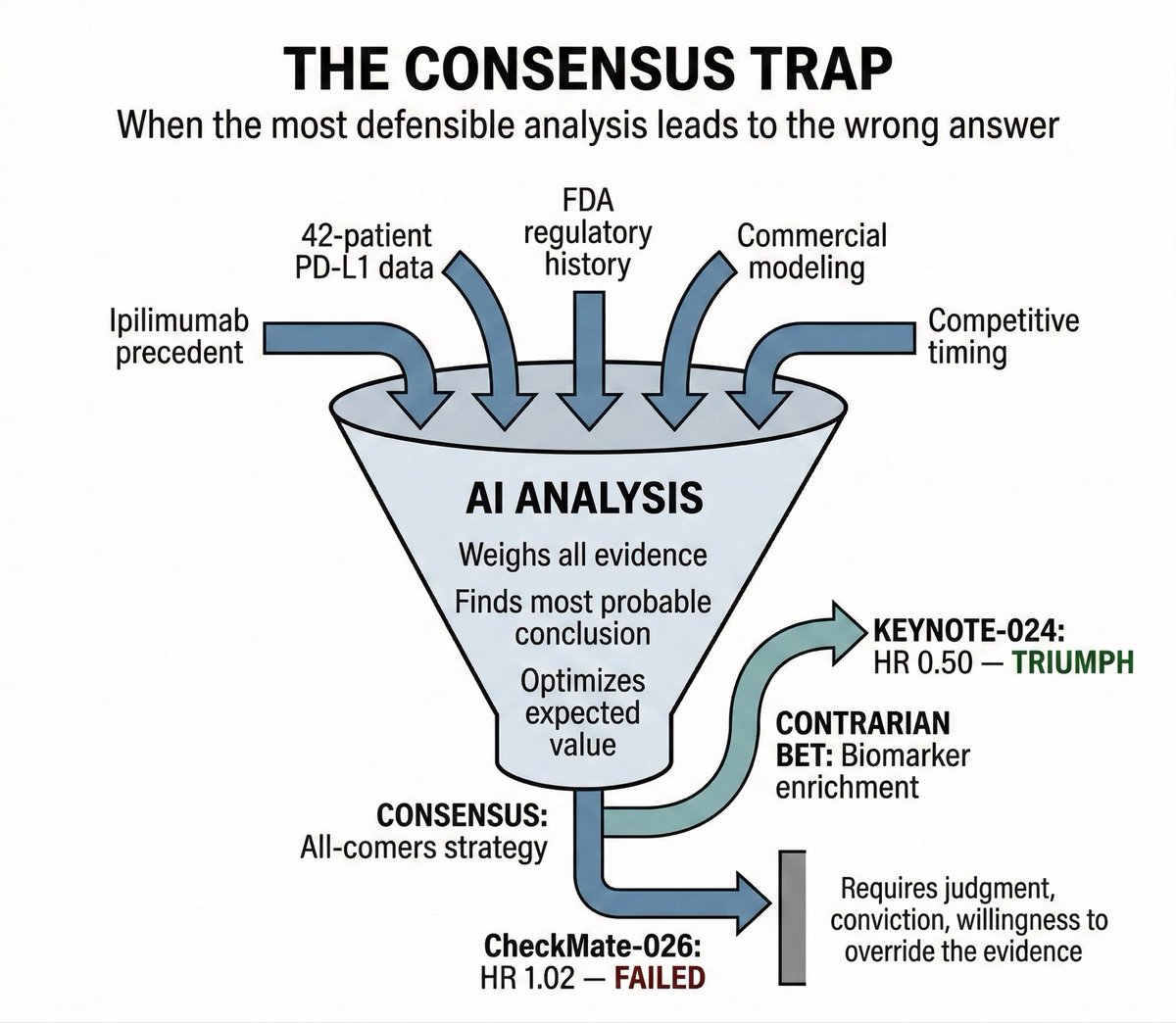
AI agents falling in the consensus trap: Just discovered this tweet from 2 months ago. 2 teams of LLM powered agents representing 2 Pharma C suites made the same $20B/yr mistake that BMS made in 2012 while developing their checkpoint inhibitor Opdivo : going for the broader patient population vs a narrower set of biomarker positive patients (what Merck did for Keytruda).
Cannot recommend @liangc_science’s piece enough. Methodology seems solid. Will think about how to re run this with a different setup and the newer models/harnesses. Super interesting model eval idea.
Generative AI models have transformed protein design, but have they helped us understand proteins better?
In our perspective, we review XAI for protein language models and ask how we can open these black boxes and extract scientific knowledge from them.
Read our manuscript now out at @NatMachIntell!:
https://t.co/d6YFJaY9nm
(with Twitter-less Andrea Hunklinger :))
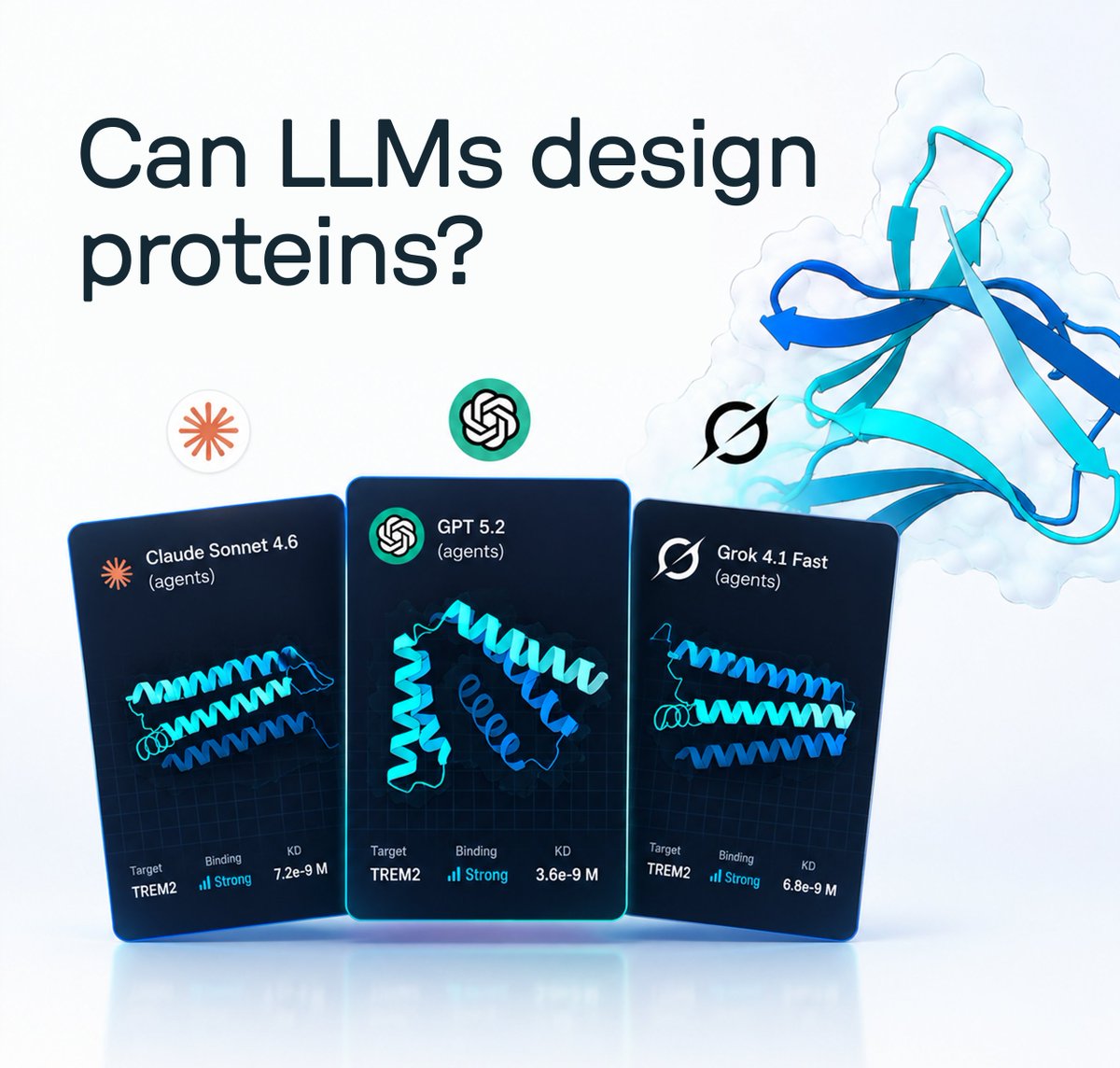
What happens when you let frontier LLMs design proteins, and then synthesize and test them in a wet lab?
We ran a protein design competition with @muni_bio where AI agents competed against humans to design molecules that bind TREM2, a key receptor linked to Alzheimer’s.
Results: GPT 5.2 and Grok 4.1 both placed in the top 5, with molecules showing strong binding to TREM2 when tested in our lab.
What if we could design ligands that not only bind a target, but functionally direct it toward activation or inhibition? In our #ICML2026 Spotlight, we present TD3B, a discrete diffusion framework for directional allosteric binder generation! 🦉
📜: https://t.co/EI8AOWChqY
🤗: https://t.co/kNC0ywflgQ
I've recently got in on the act of getting AI to solve open problems in mathematics. More precisely, I gave some questions asked by Melvyn Nathanson to ChatGPT 5.5 Pro, to which I have been given access, and it answered them. 🧵
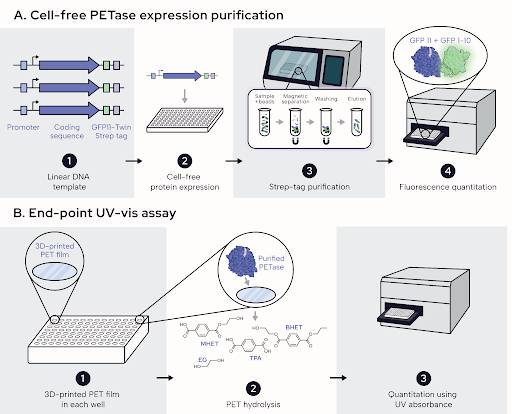
📊 Engineering better PETases isn’t just a modeling problem, it’s a data problem.
In the PETase Engineering Tournament, we partnered to develop three independent assay platforms to measure expression and activity across temperature and pH: cell-free systems, E. coli + Rapid Fire Mass Spec, and microfluidic droplets.
The takeaways:
→ High-throughput ≠ high-quality
→ Realistic assays ≠ scalable assays
→ Generating reliable, ML-ready data is still the bottleneck
Though challenging, this is the kind of groundwork needed to actually move the field forward.
🔗Full methods + learnings: https://t.co/IzCBunHrES
💪 Many thanks to our sponsor Twist Bioscience for DNA synthesis and to Adaptyv for their valuable collaboration on assay development.
#ProteinEngineering #SyntheticBiology #EnzymeEngineering #MachineLearning #Biotech #AssayDevelopment #DataScience #Bioengineering #Sustainability #PlasticRecycling
For more than 20 years, the entire Alzheimer's field chased one target: amyloid.
The next wave doesn't all chase amyloid. In 2026, the Alzheimer's pipeline has 11 readouts across 5 mechanism classes. The deepest year on record. Only three of the eight bets still target amyloid. The rest:
1. Remternetug (Lilly): next-gen anti-amyloid, self-injection. 100% plaque clearance in 3 months at top dose. Phase 3 data imminent.
2. Leqembi SC (Eisai/Biogen): at-home version of Leqembi. FDA decision May 24.
3. BIIB080 (Biogen/Ionis): first anti-tau drug to test efficacy in humans. ~60% CSF tau reduction. Q2/Q3 readout.
4. Sabirnetug (Acumen): targets soluble Aβ oligomers, not plaque. Zero ARIA in Phase 1.
5. ACI-24.060 (AC Immune/Takeda): anti-amyloid vaccine. 1-2 shots a year. Interim PET data 1H 2026.
6. AXS-05 (Axsome): oral, treats AD agitation without sedation. PDUFA late April.
7. Xanamem (Actinogen): first oral drug to lower brain cortisol. 60% slowing in high-pTau patients. November data.
8. AL101 (Alector/GSK): boosts progranulin, the brain's clean-up signal. Futility check 1H 2026.
One mechanism for two decades. Five in one year.
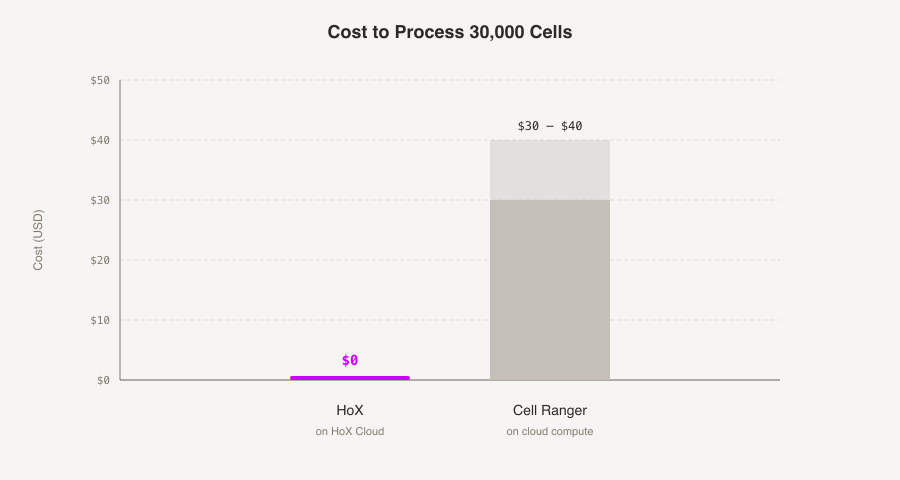
We wrote our own hyper-efficient version of the STAR aligner.
Typically it costs around $35 in cloud compute to process 30k cells with Cell Ranger. Ours costs so little that we don't charge for it. Also ours works with nanopore.
If you prefer pseudoalignments, then you can run it in pseudoalignment mode -- obviously we don't charge for that too.
All results instantly integrated with our other tools. As soon as a run finishes you can open alignments or expression matrices in our viewers without moving anything.
Let me know if you want to try it!
We benchmarked Arc Institute’s “MULTI-evolve” and found evidence that it learns a classical additive model, not epistasis.
Preprint: https://t.co/qYQxEXbJzM
Blog: https://t.co/BKCmRii3G1
🤗🤗🤗introducing Hugging Science -- the home of AI for science 🤗🤗🤗
open models and datasets are the powerhouse of science (see the PDB), but finding the models and data you actually need for your breakthrough is hard af
you shouldn't need to scrape arxiv, own your own wetlab, fight a custom HDF5 parser, build a fusion stellarator, and beg for compute before you've trained a single epoch
so we're changing that
we've put all the best science on @huggingface in one place:
- 78GB of genomics data
- 11TB of PDE simulations
- 100M cell profiles
- 9T DNA base pairs
- 13M molecular trajectories
- 400k medical QA pairs
and much more, all open, and all ready for training (+ you can also now filter and search by domain, task, and keyword)
we've put together all the biggest releases from our partners at NASA, Google, OpenAI, Meta FAIR, Arc Institute, Ginkgo, SandboxAQ, Proxima Fusion, NVIDIA, Ai2, OpenADMET, InstaDeep, Future House, Polymathic AI, LeMaterial, Earth Species Project, Merck, and Eve Bio
if you're not sure where you fit in -- work on open challenges for problems that matter: including fusion stellarator design, ADMET, antibody developability, multilingual medicine, catalysis and materials, and scientific reasoning.
we're already changing how science gets done:
a fusion startup needed a benchmark for stellarator plasma confinement that didn't exist. @proximafusion shipped ConStellaration on Hugging Science: a leaderboard, dataset, and eval metrics, all in one place.
a drug discovery team wanted to predict hPXR induction. OpenADMET put up a blind challenge: 11,000+ compounds assayed at Octant, 513 held out, two tracks (pEC50 + structure). Anyone in the world can train and submit.
an antibody team at @Ginkgo released GDPa1, a developability dataset for stability, manufacturability, and immunogenicity prediction, with a live leaderboard scoring every submission.
if you know a problem the ML community should be working on, let us know. make a challenge! this is about putting all the tools for solving science in one place. so we can hillclimb!
→ https://t.co/T4l4r1lDz0
We quietly launched the Symphony repo on Github last month, and it's already accumulated 15.5k stars!
Excited to share this post that dives into it even deeper: a library that lets you use Codex to orchestrate work normally done by teams of engineers.
https://t.co/aoqUvfrWS2