🚀 Sovereign AI for the world.
Cohere & Aleph Alpha form transatlantic AI powerhouse anchored in Canada & Germany! Combining our global scale with European R&D excellence to build sovereign, enterprise-grade AI. Security, privacy & trust for businesses & governments worldwide. #SovereignAI #AIPartnership
Learn more: https://t.co/hSwFQfuTAd
Image from left to right: Rolf Schumann, Schwarz Digits, Samuel Weinbach, Aleph Alpha, Aidan Gomez, Cohere, Minister Solomon, Canada, Minister Wildberger, Germany
LLM agents are assumed to integrate unexpected environmental observations into their reasoning. It turns out they don't.
We added the complete task solution into agent environments as a file or an API endpoint, and measured whether agents act on what they discover. They almost never do.
Starkest example: on AppWorld, gpt-oss-120b sees a CLI command documented as "returns the complete solution to this task" in 97.54% of runs. It calls it in 0.53%. Same pattern for GLM-4.7 and other models, across Terminal-Bench, SWE-Bench, and AppWorld.
📜 https://t.co/lqFuebkOBY
🧵👇
Took Claude up for a spin on the weekend and started a quick open-source self-hosted re-implementation Thinking Machines' Tinker API: https://t.co/AJmLBV2uqx
been having fun training two new friends @cohere over the last few months: one nimble and quick-witted, one mighty and wise - but both better than me at finding what you're looking for
when i say i am excited about boring AI this is what i mean.
Rerankers wont make you believe the end of the world is coming, but god damn are they useful.
Cohere just released the best reranker in the world. again.
Introducing our latest breakthrough in AI search and retrieval: Rerank 4!
It’s the most advanced set of reranking models on the market, with best-in-class performance across search relevance, speed, deployment flexibility, multilingual support, and domain-specific understanding.
🚀Adapters v1.2 is out!🚀
We've made Adapters incredibly flexible: Add adapter support to ANY Transformer architecture with minimal code!
We used this to add 8 new models out-of-the-box, incl. ModernBERT, Gemma3 & Qwen3!
Explore this +2 new adapter methods in this thread👇(1/5)
𝐂𝐨𝐡𝐞𝐫𝐞 𝐄𝐦𝐛𝐞𝐝 𝐯𝟒 - 𝐒𝐭𝐚𝐭𝐞-𝐨𝐟-𝐭𝐡𝐞-𝐚𝐫𝐭 𝐭𝐞𝐱𝐭 & 𝐢𝐦𝐚𝐠𝐞 𝐫𝐞𝐭𝐫𝐢𝐞𝐯𝐚𝐥
Today we are releasing Embed v4, unlocking so many cool new features for retrieval.
🇺🇳 100+ languages
🖼️ Text & Image capabilities
📜 128k context length
Today we are releasing Embed 4 – the new SOTA foundation for agentic enterprise search and retrieval applications!
https://t.co/v9xqs7LSC6
Check out the blog for similarly visually satisfying graphs :)
We’re excited to introduce our newest state-of-the-art model: Command A!
Command A provides enterprises maximum performance across agentic tasks with minimal compute requirements.
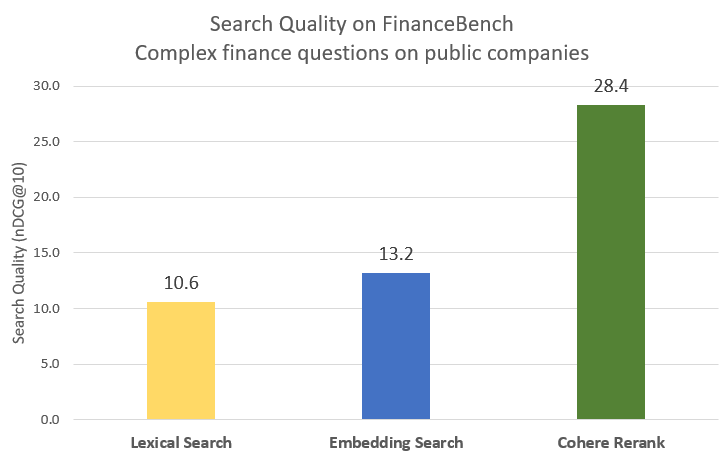
Introducing our latest AI search model: Rerank 3.5!
Rerank 3.5 delivers state-of-the-art performance with improved reasoning and multilingual capabilities to precisely search complex enterprise data like long documents, emails, tables, and code.
https://t.co/UGxclqGIPY
Modular Transformers def is one of the coolest and most unexpected changes in the Transformers backbone recently!
Hoping to see more modularity & inheritance in the future
Transformers v4.45 was just released, and it introduces a change I would not have expected: Modularity in Modeling Files.
Transformers has always been strict about its single-file policy: a model must be defined in a single file rather than through layers of abstraction.
So, what changed, and why are we seemingly moving away from the concept that made transformers what it is today, with 250+ model architectures across many modalities?
We respond to an issue that affects both contributors and maintainers: contributing a model to transformers is long and tedious. It oftens results in PRs spanning across 20+ files, with thousands of lines of code.
We wanted a solution to remove that constraint from contributors, therefore significantly enabling model additions from model authors and community members.
Still, the single-file policy is at the core of Transformers: controversial to some due to the constraints it brings with it, we know for a fact that it enabled:
- Researchers to experiment and tweak the modeling files
- Students to go through the code without jumping from abstraction to abstraction,
- Community members to contribute models without first needing to understand the rest of the overwhelmingly large package.
Therefore, we've worked on "Modular Transformers," an approach to designing modeling files in a modular way while maintaining the single-file policy.
Contributing a model to Transformers can now be done by subclassing other models, inheriting all their attributes, methods, and forward definitions.
The tool we contribute enables unraveling that inheritance into a single file. The RoBERTa "Modular" modeling file above defines the base and masked LM models.
This is then unraveled in a 1700+ single-file model definition, which can be inspected, debugged, tweaked, and adapted.
The model definition spans ~30 lines of code: only the differences are now explicit.
This is particularly important in the wake of LLMs, with each released model being only slightly different in terms of architecture; most of the difference lying in the data for the pretrained checkpoints.
While the "Modular" and "Single-file" model definitions serve different purposes, they should both result in the exact same code execution. We aim for no magic, no hidden behavior: define a code path, a property, a method in the modular file, and you'll see it reflected in the single file.
With this now merged, we can start seeing model contributions coming in at 215 LoC for the modular file; being unraveled to several files, the single-file definition standing at 1300+ LoC.
Now, please come and help us break it! It's experimental and brittle, but it should drastically lower the barrier of entry for model contribution. Come and contribute your model to make it accessible to the community at large 🙌
🎉Adapters 1.0 is here!🚀
Our open-source library for modular and parameter-efficient fine-tuning got a major upgrade! v1.0 is packed with new features (ReFT, Adapter Merging, QLoRA, ...), new models & improvements!
Blog: https://t.co/Evp8kQG1je
Highlights in the thread! 🧵👇
𝐂𝐨𝐡𝐞𝐫𝐞 𝐑𝐞𝐫𝐚𝐧𝐤 𝐕𝟑 𝐨𝐧 𝐀𝐳𝐮𝐫𝐞 AI - 𝐒𝐮𝐩𝐞𝐫𝐜𝐡𝐚𝐫𝐠𝐞 𝐲𝐨𝐮𝐫 𝐑𝐞𝐭𝐫𝐢𝐞𝐯𝐚𝐥
Happy to announce that the most powerful model for retrieval, Rerank V3 by @cohere , is available on Azure AI.
It excels on extremely complex queries.
🚀𝐇𝐢𝐠𝐡𝐞𝐫 𝐓𝐡𝐫𝐨𝐮𝐠𝐡𝐩𝐮𝐭 - 𝐂𝐨𝐡𝐞𝐫𝐞 𝐑𝐞𝐫𝐚𝐧𝐤 𝟑 𝐍𝐢𝐦𝐛𝐥𝐞
Cohere Rerank is the perfect model to improve your Search Relevancy with just 1 line of code.
But serving high enterprise workloads with hundred thousands of queries per hour was still expensive.