Engineer. Love backend(python, node.js, go, rust and other), microservices and architecture of neural models( NLP and more specific themes). Conference speaker.
HarnessX: a harness that compiles itself.
every harness improvement so far has come from a human editing code by hand.
Anthropic strips planning steps out of Claude Code when a stronger model ships. Manus rebuilt its agent five times in six months, removing complexity each round.
the craft runs on human judgment about what to change and when. HarnessX is what happens when a system makes those edits itself.
the trick is to treat the harness as a first-class object, the way we already treat model weights.
once it's a typed, editable artifact, it can be optimized from its own execution traces.
the framing they use is an operational mirror. evolving a harness maps cleanly onto reinforcement learning.
the harness is the state. an edit is the action. the trace plus a score is the feedback. a new version is the update.
once you see it that way, the failure modes come for free. reward hacking, catastrophic forgetting, under-exploration.
the same problems that break model training show up when a system edits its own scaffolding.
so edits never ship blind. each round, a loop reads the traces, plans a change, writes the edit, then critiques it.
a gate keeps the new version only if it beats the current one on tasks it hasn't seen.
what makes this safe is the structure underneath. the harness is built from typed components the system can swap without breaking the rest.
that is what compiles really means here. every candidate harness is type-checked before it runs.
here is the result that matters. the weakest model improved the most. the strongest barely moved.
an evolved harness closes the gaps a weak model cannot fix on its own. the weights never changed. the environment around them got smarter.
this is the natural next phase of harness engineering. we moved from weights, to context, to hand-built harnesses.
the harness was the last piece we still tuned by hand.
i wrote a deep dive on agent harness engineering a while back, covering the orchestration loop, tools, memory, context management, and everything that turns a stateless LLM into a capable agent. the article is below.
paper: HarnessX: A Composable, Adaptive, and Evolvable Agent Harness Foundry: https://t.co/L0GeUKCgef
This SkillOpt paper from Microsoft is a must-read!
(bookmark it)
I was a bit skeptical of the results reported in the paper when I shared it a few days ago.
However, I managed to integrate it into my agent orchestrator and ran a few experiments.
The results are mindblowing.
Essentially, all my agent skills now have a proper testing framework and a way to self-evolve. I have started to improve all my agent skills with this.
One exciting result was when I applied it to my paper-figure-extraction skill, which requires an agent to do multimodal analysis. In particular, it improved quality by +20 points (0.73 → 0.93). I went to see the extracted tables and figures, and I was absolutely stunned by how much better my skill got at the task.
Self-improving AI is in the early days, but I think this work is a clear example of the current ability of agents to self-improve.
In this case, it was skills, but it's not hard to imagine how this scales to optimizing agent patterns, tool use, context engineering efforts, agentic search, workflows, evals, and even the harness itself. I already started with a few of these ideas inspired by SkillOpt.
Stay tuned!
Boris Cherny, the creator of Claude Code at Anthropic, just explained why single-agent workflows are already dead
in this talk he breaks down exactly how the future is teams of agents, not better prompts:
- the 14% you lose to CLAUDE.md before typing a word
- one agent researching. one building. one reviewing. one orchestrating
- the architecture that separates hobbyists from real builders
- the 3 properties every agent team needs to actually survive
if you've been using Claude for more than a month and never left the chat window, you've been using one agent when you could be running a team of them
instead of another show tonight, watch this
make sure to bookmark it before it gets lost in your feed
the guide is in the article below
Anthropic AI engineer just showed how to give AI agents real memory in 4 steps - and it changes everything
in 28 minutes he shows exactly how agents can remember across sessions, completely free
worth more than any $500 AI engineering course
here's what he covers:
• why agents forget everything between sessions
• memory stores - agents read, write across sessions
• dreaming - agents that improve their own memory
• 95% cache hit rate, so it stays cheap
most people are still copy-pasting context into every new chat - while the people who figured this out are building agents that get smarter every single night
watch full video then read article below
arXiv Papers → LLM Artifacts
This is how I keep up with AI research now.
It's like having access to the most personalized arXiv feed.
Automations run everyday to curate papers based a set of rules and insights.
Curated papers are indexed and power the artifacts.
Agent convert papers to LLM wikis (based on @karpathy idea), which means insights are indexed and easily searchable and reusable.
I feel like LLM Artifacts is the natural evolution to LLM Wikis. It's about making that knowledge actionable.
Artifacts are customizable via agents. Artifacts can interact with agents and are dynamic in nature. Anything can be injected into the artifact as needed (insights, components, suggested experiments, action items, etc).
I can take action on Artifact items with my agent orchestrator (Electron app).
So I can ask questions about any paper and automate experiments in the background right from within the artifact.
This is more than a visual. It's not a single prompt. It's several proactive agents coordinating to surface interesting facts, knowledge, and insights that I can act on a researcher.
Agents are not just for generating useful artifacts, they are useful to keep learning and staying on the cutting edge of knowledge. Stay tuned for more.
Banger paper from Meta FAIR.
They introduce Autodata, an agentic data scientist that builds high-quality training and evaluation data autonomously.
The headline result: on a CS research QA task, an Agentic Self-Instruct loop produces a 34-point gap between weak and strong solvers (43.7% vs 77.8%), while standard CoT Self-Instruct on the same setup produces a 1.9-point gap (71.4% vs 73.3%).
The agent generates questions that actually discriminate between models.
The method:
An orchestrator LLM directs a challenger agent to generate examples grounded in domain documents. A weak and a strong solver attempt them, a judge scores the outputs, and the orchestrator analyzes the failures and prompts the challenger to regenerate from new angles until quality thresholds are met.
The system also meta-optimizes itself.
An outer loop tunes the agent's instructions based on which harness changes lift validation pass rate. Over 126 accepted iterations, validation pass rate climbed from 12.8% to 42.4%. They processed 10,000+ CS papers and produced 2,117 quality-filtered QA pairs.
Existing self-instruct pipelines do not control data quality. Autodata reframes data generation as an agent loop, spend more inference compute and the data gets harder, which gives downstream RL a real lift.
Blog: https://t.co/41coXidxRI
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
// Agentic Harness Engineering //
Pay attention to this one, AI devs.
(bookmark it)
Most coding-agent harnesses are still tuned by hand or brittle trial-and-error self-evolution.
This new work introduces Agentic Harness Engineering, a framework that makes harness evolution observable. They do this through three layers: components as revertible files, experience as condensed evidence from millions of trajectory tokens, and decisions as falsifiable predictions checked against task outcomes.
Each edit becomes a contract you can verify or revert.
Results: pass@1 on Terminal-Bench 2 climbs from 69.7% to 77.0% in ten iterations, beating human-designed Codex-CLI (71.9%) and self-evolving baselines like ACE and TF-GRPO.
The evolved harness also transfers across model families with +5.1 to +10.1 point gains, while using 12% fewer tokens than the seed on SWE-bench-verified.
Harness work is the biggest hidden cost in most agent systems. This is the first credible recipe for letting the harness improve itself without drifting into noise.
Paper: https://t.co/9fEgqwlTSf
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
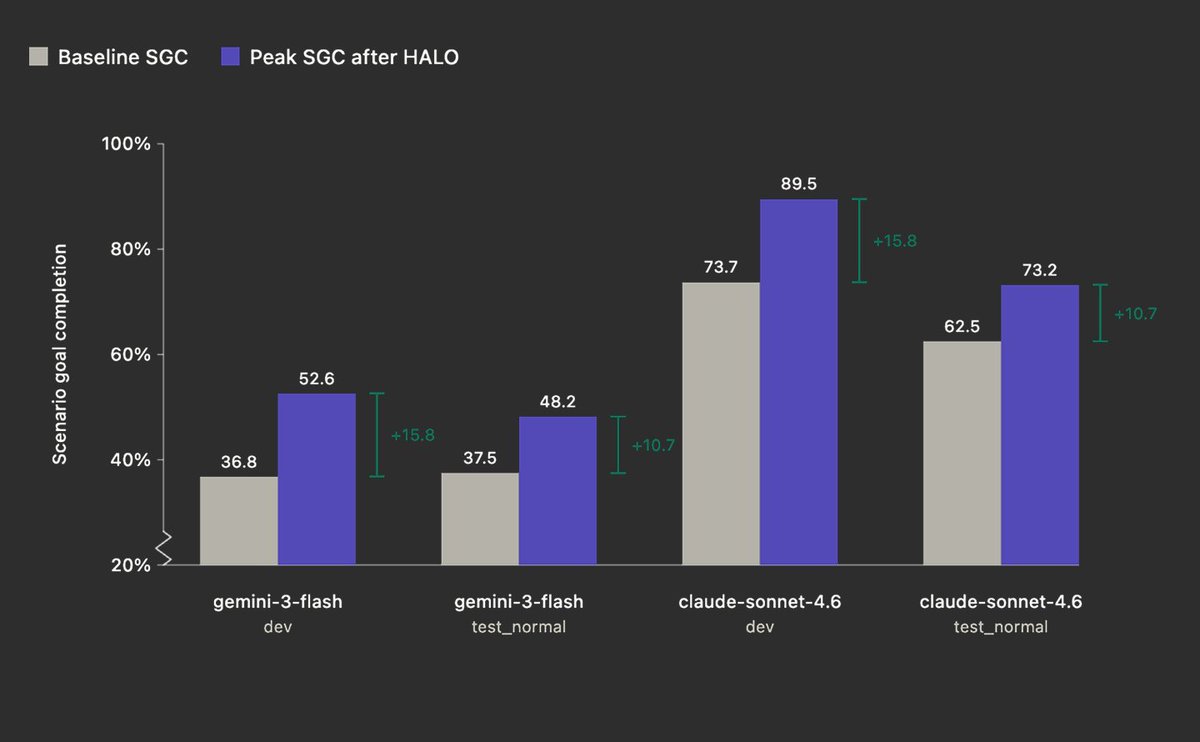
We’re introducing HALO 😇
Hierarchal Agent Loop Optimizer
HALO is an RLM-based agent optimization technique capable of recursively self-improving agents by analyzing their execution traces and suggesting changes.
This work is inspired by the Mismanaged Genius Hypothesis proposed by @a1zhang and @lateinteraction earlier this month.
tldr; we improved performance on AppWorld (Sonnet 4.6) from 73.7 --> 89.5 (+15.8) by giving HALO-RLM access to harness trace data and asking it to identify issues.
The feedback from HALO surfaced failures in the harness such as hallucinated tool calls, redundant arguments in tools, refusal loops, and semantic correctness issues. Each issue mapped cleanly to a direct prompt update.
We then fed these finding into Cursor (Opus 4.6), and asked the coding agent to update the underlying harness.
We repeated this trace -> HALO-RLM analysis -> code update loop until the score plateaued.
Today we’re open-sourcing the core HALO-RLM framework, evals, and data for further review.
This 30-minute speech by the Head of Anthropic "Coding Agents" researcher will teach you more about vibe coding than 100 paid courses.
Bookmark it & give it 30 minutes today. This video will change the way you use AI forever,
Agent evals are drifting away from production reality.
Most benchmarks use clean tasks, well-specified requirements, deterministic metrics, and retrospective curation. Production work is messier, with implicit constraints, fragmented multimodal inputs, undeclared domain knowledge, long-horizon deliverables, and expert judgment that evolves over time.
This paper introduces AlphaEval, a production-grounded benchmark for evaluating agents as complete products.
AlphaEval contains 94 tasks sourced from seven companies deploying AI agents in core business workflows, spanning six O*NET domains. It evaluates systems like Claude Code and Codex as commercial agent products, not just model APIs.
The benchmark combines multiple evaluation paradigms: LLM-as-a-Judge, reference-driven metrics, formal verification, rubric-based assessment, automated UI testing, and domain-specific checks.
Why it matters: organizations need benchmarks that start from real production requirements, then become executable evals with minimal friction.
Paper: https://t.co/cbTGgTWoNl
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
Agent memory is three-dimensional.
Most agent memory systems use a single store. Usually a vector database. It handles semantic similarity well, but it captures only one dimension of knowledge.
Here's the gap. Store these three facts:
→ Alice is the tech lead on Project Atlas
→ Project Atlas uses PostgreSQL for its primary datastore
→ The PostgreSQL cluster went down on Tuesday
Now ask: was Alice's project affected by Tuesday's outage?
Vector search finds fact 1 (mentions Alice) and fact 3 (mentions Tuesday). But the bridge between them, fact 2, mentions neither. It connects Project Atlas to PostgreSQL, and that's exactly what gets missed.
This is the normal shape of business knowledge. People belong to teams, teams own projects, projects depend on systems, systems have incidents. Any question crossing two hops breaks flat retrieval.
The three dimensions that actually cover agent memory:
→ A relational store for provenance (where data came from, when, who has access)
→ A vector store for semantics (what content means, what it's similar to)
→ A graph store for relationships (how entities connect across hops)
Each captures something the other two can't. Vectors find meaning. Graphs trace connections. Relational tables track lineage and permissions.
The real unlock is combining them: enter through vectors (find semantically relevant content), then traverse the graph (follow edges to connected entities), with provenance grounding every result back to its source.
Cognee is an open-source project that unifies all three behind four async calls. The default stack is fully embedded (SQLite + LanceDB + Kuzu), so a pip install gets you running locally. For production, swap in Postgres, Qdrant, or Neo4j without changing your agent code.
Check it out on GitHub: https://t.co/GmVimnGMdx
The article below is a first-principle deep dive on building agents that never forget. This will give you a clear picture of how memory for agents is evolving.
NEW research on improving memory for AI Agents.
(bookmark it)
As context windows scale to millions of tokens, the bottleneck shifts from raw capacity to cognitive control. Knowing what you know, knowing what's missing, and knowing when to stop matters more than processing every token.
Longer context windows don't guarantee better reasoning. This is largely because the way devs handle ultra-long documents today remains expanding the context window or compressing everything into a single pass.
But when decisive evidence is sparse and scattered across a million tokens, passive memory strategies silently discard the bridging facts needed for multi-hop reasoning.
This new research introduces InfMem, a bounded-memory agent that applies System-2-style cognitive control to long-document question answering through a structured PRETHINK–RETRIEVE–WRITE protocol.
Instead of passively compressing each segment as it streams through, InfMem actively monitors whether its memory is sufficient to answer the question. Is the current evidence enough? What's missing? Where in the document should I look?
PRETHINK acts as a cognitive controller, deciding whether to stop or retrieve more evidence. When evidence gaps exist, it synthesizes a targeted retrieval query and fetches relevant passages from anywhere in the document, including earlier sections it already passed. WRITE then performs joint compression, integrating retrieved evidence with the current segment into a bounded memory under a fixed budget.
The training recipe uses an SFT warmup to teach protocol mechanics through distillation from Qwen3-32B, then reinforcement learning aligns retrieval, writing, and stopping decisions with end-task correctness using outcome-based rewards and early-stop shaping.
On ultra-long QA benchmarks from 32k to 1M tokens, InfMem outperforms MemAgent by +10.17, +11.84, and +8.23 average absolute accuracy points on Qwen3-1.7B, Qwen3-4B, and Qwen2.5-7B, respectively.
A 4B parameter InfMem agent maintains consistent accuracy up to 1M tokens, where standard baselines like YaRN collapse to single-digit performance. Inference latency drops by 3.9x on average (up to 5.1x) via adaptive early stopping.
These gains also transfer to LongBench QA, where InfMem+RL achieves up to +31.38 absolute improvement on individual tasks over the YaRN baseline.
Paper: https://t.co/4wxeCua7a7
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
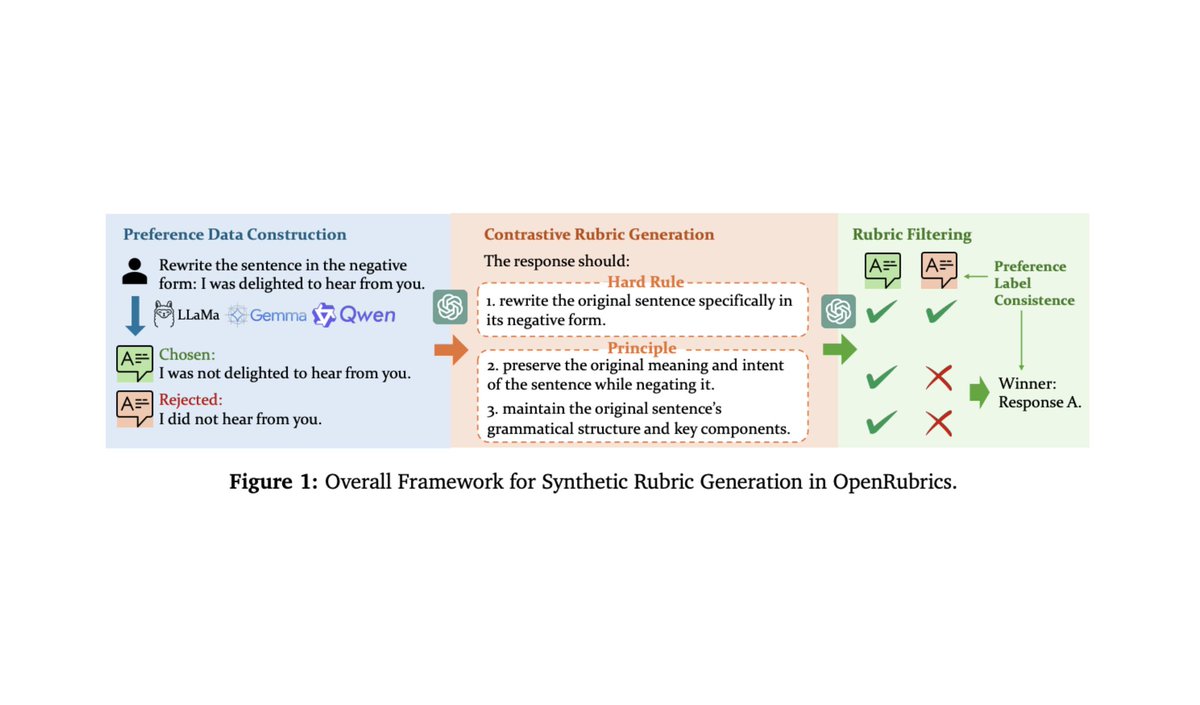
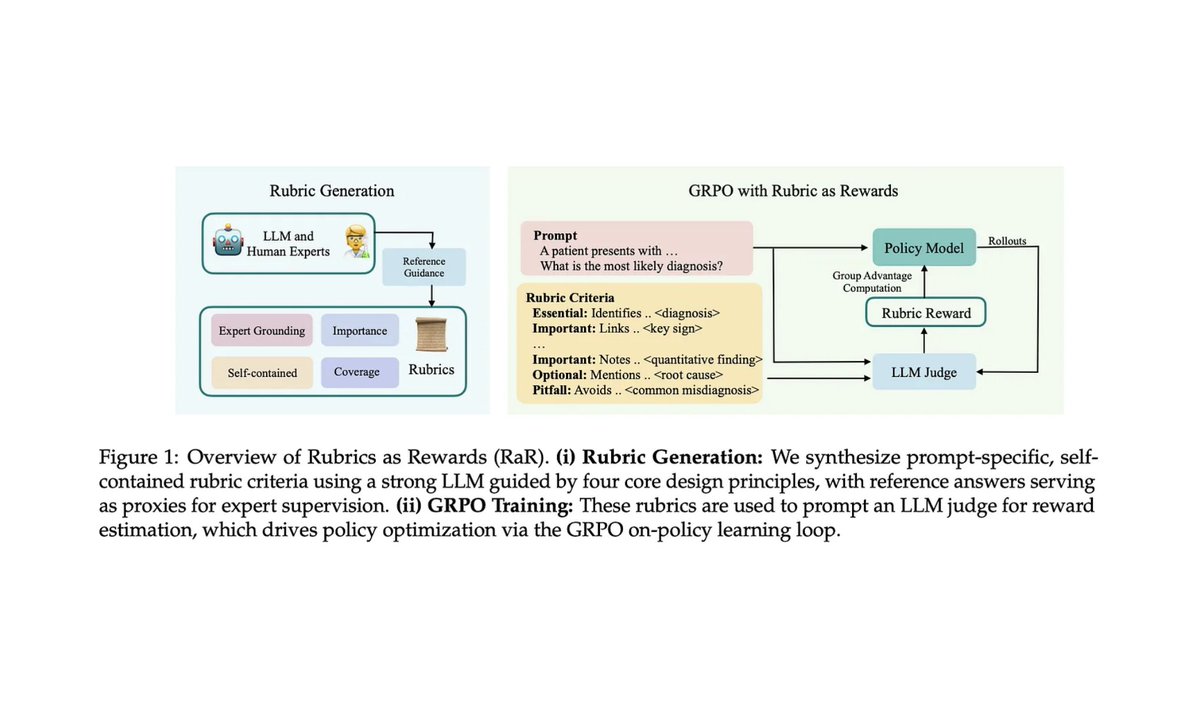
I've been reading a lot about rubrics-as-rewards (RaR) for RL. Some of my favorite papers (so far):
1. https://t.co/oFI2ihpV6e
2. https://t.co/3z3ZSgEN3j
3. https://t.co/L16SWVhrMx
4. https://t.co/c6KFHVJ0hK
5. https://t.co/6Ky9UlBTGh
Most of the added technical complexity of RaR is less related to RL and more related to reward modeling. If we can get a reliable reward signal, RaR works well, but teaching a model to perform granular / instance-level evaluation is tough. Generalizing these evaluation capabilities across arbitrary domains is even tougher (especially those that are highly subjective). Our reward model also needs to avoid hacking in large-scale RL runs.
In my opinion, new developments in this space are likely to come from advancing the frontier of (generative) reward models rather than RL. So much to be done.