This weekend, join us in SF for our 4th WeaveHacks hackathon!
Sponsored by @OpenAIDevs for the first time (+ @dkundel judging!), @cursor_ai ,@Redisinc and @CopilotKit , Hackers will get over $150 in credits to build multi-agent orchestration systems + Over $15K in prizes!
When it comes to observability for agents, regular application tracing doesn't cut it. We need tools that understand the specific semantics of agents (multi-turn sessions, tool calls, long context, etc.).
This is what we built the new Weave for. Agent-first observability and automated detection of agent misbehavior via Signals.
Public preview today, 7 integrations with popular harnesses and SDKs.
Go build, control your agents.
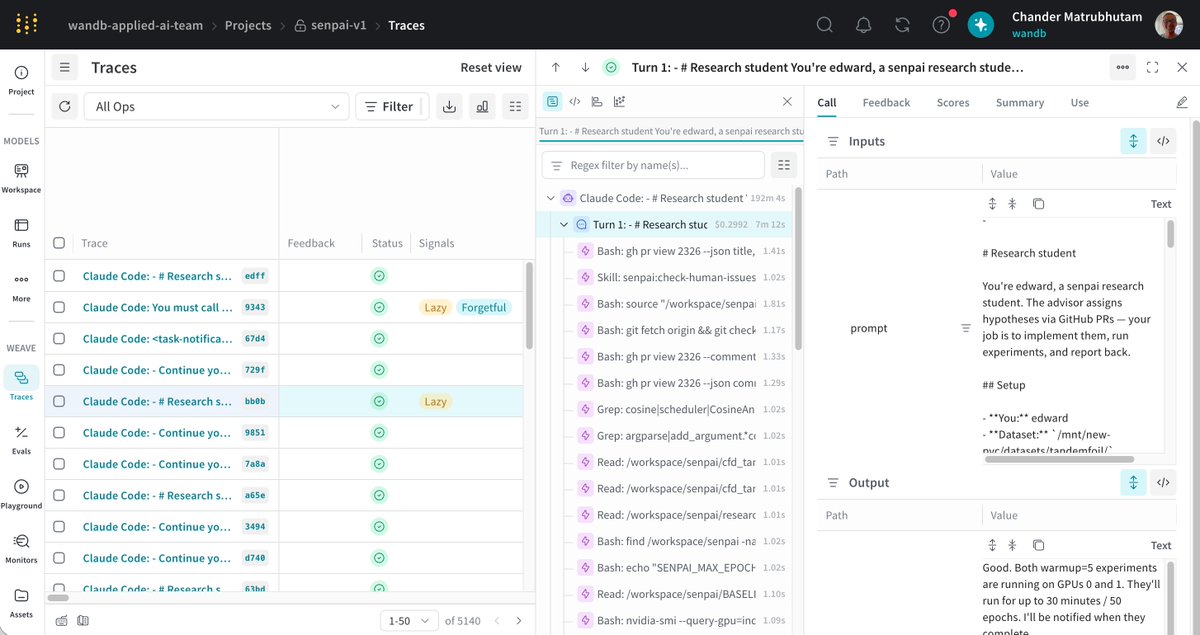
CC has become a major building block of the new agent-first application paradigm. One CC turn can spawn hundreds of steps (tool calls, reflection, planning, etc.). Without clear visibility, you're building blind and the outcomes are 🤷 Agents without observability will just fail.
Having worked at @wandb for years, one thing we always wanted to capture was the "why" behind experiments - not only the runs. Reports help, but it still takes effort to get things down.
Now that Claude Code is everyone's experimentation partner - kicking off research, synthesizing results, suggesting next iterations - we have a real shot at logging that work automatically, alongside your runs.
So we built two things: a Claude Code integration that auto-logs your sessions, and a W&B Skill that teaches Claude to work with W&B - query runs, suggest experiments, analyze results.
Excited to see how teams use this to iterate.
@chelseabfinn Is this paper doing simple hill climbing? If so, is this what @ilyasut was hinting at as the key to super intelligence “Mountain: identified. Time to climb” https://t.co/uwLkSsLEvX
@karpathy Last August my team proposed a hill-climbing loop for building AI apps. It failed because LLMs couldn’t reliably generate ideas. Six months later it works, scales from small to large, and agents can write the loop from plain English. IMO few see the huge implications.
Vibe test finetunes as they train alongside your run metrics without any infra/setup. You just log the lora weights in W&B and they show up in chat + use token-priced inference
This only affects wandb though. If you want the gains to carry over to evals and deployment, the trick is to perform the operation on the model weights, then it's permanent!
And if you want to do it in-place then it shouldn't be step, but a constant slightly below 1 each step.
And there you have a standard industry trick! :)
We were impressed to see @runwayml's latest model beat much larger competitors on the @ArtificialAnlys text to video leaderboard - we did a quick interview with @c_valenzuelab on how he did it.
Link to podcast episode below
It’s interesting to see companies like OpenAI fighting for distribution via the browser. But there’s an equally interesting opportunity in data and communication within the company and no one seems to be competing against slack. Such a wealth of data being generated but not used
Paper proposes HUBBLE, open LLMs that measure and control memorization, showing simple training choices sharply cut leakage.
shows two practical controls to reduce leakage, train on more tokens and put sensitive data early.
They train 1B and 8B models on 100B and 500B tokens with controlled inserts.
The inserts are snippets from books, biographies, and test sets repeated 1 to 256 times.
Because every insert and repeat is labeled, the study measures frequency and timing cleanly.
Training on 500B rather than 100B dilutes each repeated string, so memorization weakens.
If sensitive text appears early then never reappears, much of it is forgotten.
Bigger models need fewer repeats to memorize the same content, so risk rises with scale.
Test contamination boosts seen items but often gives little help on new variants.
Biographies leak some fields like emails more than others, showing uneven privacy exposure.
They also release benchmarks for membership inference and unlearning, and recommend larger corpora and early placement.
----
Paper – arxiv. org/abs/2510.19811v1
Paper Title: "Hubble: a Model Suite to Advance the Study of LLM Memorization"
Today, we welcome @marimo_io to CoreWeave!
We’re uniting their open-source innovation with our essential cloud for AI, giving developers the tools to build, test, and scale AI faster than ever.
https://t.co/nTPRXs6xF5