📣We're calling for ambassadors!
Whether you're a developer with great technical taste or a local community leader who loves bringing people together, we'd love to have you join us.
Visit the website below for more details and to apply. In return, ambassadors will receive early access to Qwen models, API credits, annual merchandise, and more.
Come and check it out!👇
https://t.co/UqNQ8dAKUg
The single model era is over.
Plan with smarter/slower models (Kimi K2.6, DS4 Pro, GLM 5.1, Opus)
Execute with faster/cheaper models (DS4 Flash, Qwen 3.6+, MiniMax)
Review/bugfix with a third model (DS4 Pro, Opus)
This model routing strategy maximizes quality/cost ratio.
China just mogged everyone. Again.
They’ve dropped K2.6—an open‑source beast:
- GPT‑5.4–level coding
- 8× cheaper than Opus 4.7
- 100% open source
Here’s everything you need to know 👇
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
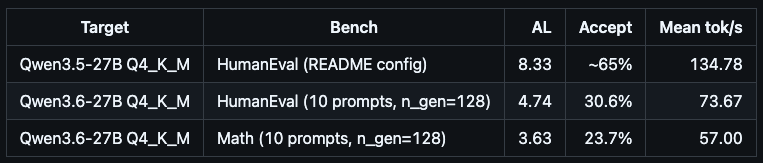
this guy just cracked 134 tok/s on qwen 3.5-27b dense and 73 on new qwen 3.6-27b on a single 3090. open source moves at godspeed in 2026.
weights ship in the evening, dynamic ggufs land by midnight, fused kernel + speculative decoding stack runs the new model 12 hours after release.
his dflash + ddtree stack loads qwen 3.6 asis because the architecture string matches 3.5. zero retraining of the draft model, zero waiting for upstream support. the same hand tuned consumer hardware kernel work that pushed 3.5 to 134 tok/s already eats 3.6 at 73, with a regression he is openly flagging because the draft model needs a dedicated pass for 3.6.
this is the lane almost nobody is working on. major labs are stuck shipping framework abstractions optimized for h100 fleets. @pupposandro is hand tuning kernels for the silicon actual builders own. 3090 has 24 gigs of vram, mature cuda support, and almost zero kernel level optimization coming out of the big shops. it is the most underrated research platform in consumer ai right now.
i am running honest baseline q4_k_m on llama.cpp now to set the dense floor without tricks. then sandro's stack runs on the same gpu, same model, same prompt. generic inference vs hand tuned kernels with speculative decoding. that delta is where the next 5 years of consumer ai live.
receipts incoming.
Why is no one talking about this?
@nvidia is offering around 80 AI models via hosted APIs absolutely for free.
You get access to MiniMax M2.7, GLM 5.1, Kimi 2.5, DeepSeek 3.2, GPT-OSS-120B, Sarvam-M etc.
This plugs straight into OpenClaude, OpenCode, Zed IDE, Hermes agent and even with Cursor IDE.
Setup:
– Grab API key: https://t.co/Wfdclm0hY2
– base_url = "https://t.co/VOGC10LmGP"
– api_key = "$NVIDIA_API_KEY"
– select model (e.g. minimaxai/minimax-m2.7)
If you’re building or experimenting, this is basically free inference.
Lock in and start building today anon.
Thank me later.
BREAKING:🚨 NVIDIA just quantized Gemma 4 31B on Hugging Face 🔥
NVFP4 compression = 4x smaller weights with frontier-level accuracy.
✅99.7% of baseline on GPQA
(75.46% vs 75.71%).
📈256K context window.
🧐Multimodal (text + images + video).
vLLM-ready + Blackwell optimized.
VRAM requirements:
⚡️Weights only: ~16–21 GB
🚀Everyday use: Runs on 24 GB GPUs
📈Full 256K context = 32 GB VRAM sweet spot (RTX 5090-class consumer GPUs)
This is the 31B-class frontier model you can actually run locally on a high-end rig.
Try it today👉 https://t.co/0E6wO3PZN4
You can now enable Claude to use your computer to complete tasks.
It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk.
Research preview in Claude Cowork and Claude Code, macOS only.
After a little bit of testing, the Nemotron-3-nano:4b Q4 still fail the car wash reasoning.
"I want to wash my car. The car wash is 50 meters away. Should I walk or drive?"
NVIDIA just dropped Nemotron-3-Nano:4b — a tiny 2.8GB model. Guess whose hardware runs it the fastest?
- RTX 4090: 226 tok/s
- RTX 3090: 187 tok/s
- Mac Studio M2 Ultra: 86 tok/s
- Mac Mini M4: 25 tok/s
Home court advantage is real.
Also trying a new layout with live performance charts. Lmk what you think!
Introducing the new @stitchbygoogle, Google’s vibe design platform that transforms natural language into high-fidelity designs in one seamless flow.
🎨Create with a smarter design agent: Describe a new business concept or app vision and see it take shape on an AI-native canvas.
⚡️ Iterate quickly: Stitch screens together into interactive prototypes and manage your brand with a portable design system.
🎤 Collaborate with voice: Use hands-free voice interactions to update layouts and explore new variations in real-time.
Try it now (Age 18+ only. Currently available in English and in countries where Gemini is supported.) → https://t.co/pmT9iHEpZa
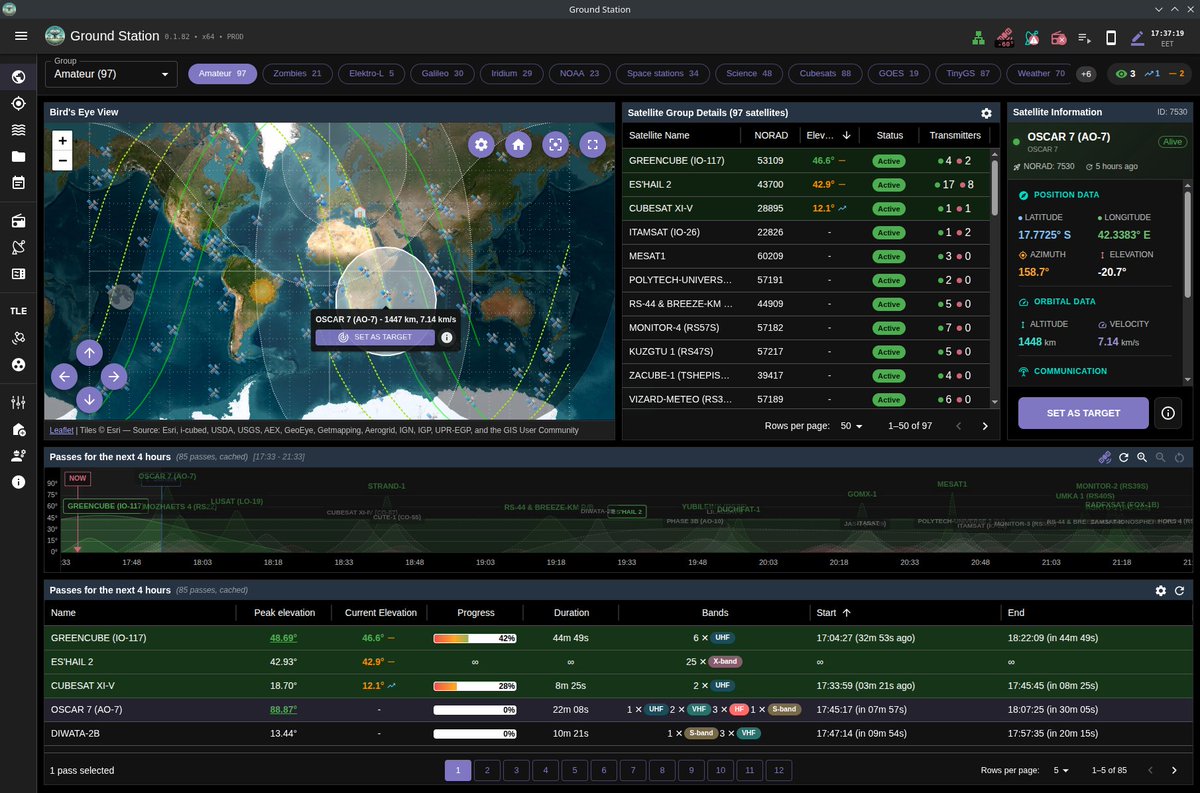
🚨 BREAKING: Someone just open-sourced a full suite for tracking satellites and decoding their radio signals locally.
You don't even need the internet. It uses an SDR to pull weather images and raw data straight from space to your hard drive.
100% Open Source.
🚨 BREAKING: A developer on GitHub just built a tool that turns any GitHub repo into an interactive knowledge graph and open sourced it for free.
It's called GitNexus. Think of it as a visual X-ray of your codebase but with an AI agent you can actually talk to.
No server. No subscription. No enterprise sales call.
Here's what it does inside your browser:
→ Parses your entire GitHub repo or ZIP file in seconds
→ Builds a live interactive knowledge graph with D3.js
→ Maps every function, class, import, and call relationship
→ Runs a 4-pass AST pipeline: structure → parsing → imports → call graph
→ Stores everything in an embedded KuzuDB graph database
→ Lets you query your codebase in plain English with an AI agent
Here's the wildest part:
It uses Web Workers to parallelize parsing across threads so a massive monorepo doesn't freeze your tab.
The Graph RAG agent traverses real graph relationships using Cypher queries not embeddings, not vector search. Actual graph logic.
Ask it things like "What functions call this module?" or "Find all classes that inherit from X" and it traces the answer through the graph.
This is the kind of code intelligence tool enterprise teams pay thousands per month for.
It runs entirely in your browser.
Works with TypeScript, JavaScript, and Python.
100% Open Source. MIT License.
Repo: https://t.co/RzIoLR2vAe