(he/him) sr. research software engineer @pwc & @cuboulder @gradbuffs student, focuses: type theory, programming languages, data science, distributed systems
@Jonathan_Blow Or to put it differently, category theory is only really useful at the interfaces between mathematical systems or paradigms, which is why it is so vapid; outside of those interfaces it’s not going to produce much, but at them it’s a powerful scientific tool.
@Jonathan_Blow Since CT is abstract as a foundational principle (which is weird), to me, the best way to approach it is to marry it with a concrete math you already care about like algebra, type theory, geometry etc. I like Bob Harper’s “computational trilogy” approach. https://t.co/MhK426IU5o.
@charles_irl It isn’t not programming, exactly but I have mostly used GPT to explore ideas in type theory (and sometimes I ask for code listings to illustrate our conversations). The most useful thing I have found is synthesizing/comparing/contrasting the content of papers or groups of papers
@dvassallo I’ve volunteered with the TEALS org for a while and the standard HS curriculum is MIT Scratch then onto Python or Java.
But personally I would start with Racket! It’s one IDE and place to learn and follows a well structured path with teaching languages: https://t.co/NsoFjBzab4
@steveklabnik Yes! In particular I love the description of .await as a composition operator.
Explained in a clear way like this, I find that thinking of async/await as a certain kind of state monad can make it easier to understand.
@ChShersh It would be a great thing! The more people learn about it, the better. With 5.0, OCaml is the only ~ mainstream language I know of that embraces algebraic effects & handlers as a first class construct.
@luckymanML @FriedFryingPan@toncijukic@bgolus@bmcnett The more I use LLMs when writing software, the more I agree with @RaeHaskell’s take that it won’t be that AI models will write *all* the code; rather it will change the role of human programmers to one of reviewing/pair programming using rich, expressive specification languages.
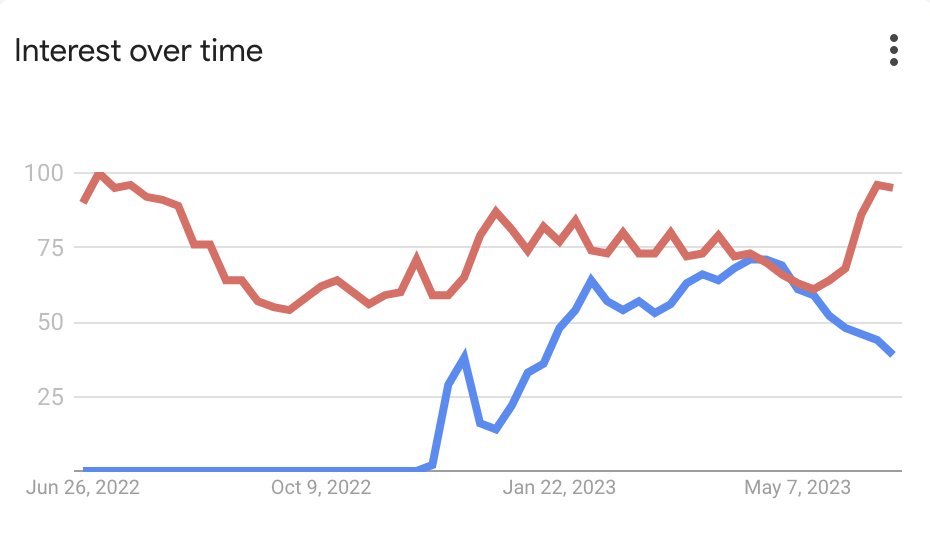
Search interest over time, ChatGPT (blue) vs Minecraft (red).
There's an obvious factor that might well underlie both trends (down for ChatGPT, up for Minecraft). Can you guess what it is?
As it happens, the answer matters for both the future of AI and the future of education.
huh? so when gpt4 was thought to be a really really big gpt3 people were like "WOW AMAZING" and now with the rumor of it being 8*220B mixture of experts with small inference trick they are like "Oh, Mixture of Experts? thats what you do when you are low on ideas"?
Screen sharing with a student today:
S: "I don't understand this function.."
Me: "<Explains>...change line 11"
S: "<Starts typing...>
Copilot: "<Offers suggestion, no explanation>"
S: "<Immediately accepts suggestion without reading, still doesn't understand, code is wrong>"
* People ask LLMs to write code
* LLMs recommend imports that don't actually exist
* Attackers work out what these imports' names are, and create & upload them with malicious payloads
* People using LLM-written code then auto-add malware themselves
https://t.co/Va9w18RpWu
Can Large Language Models Infer Causation from Correlation?
paper page: https://t.co/X2vsTN0RUP
dataset: https://t.co/xIQ7P2WlUu
Causal inference is one of the hallmarks of human intelligence. While the field of CausalNLP has attracted much interest in the recent years, existing causal inference datasets in NLP primarily rely on discovering causality from empirical knowledge (e.g., commonsense knowledge). In this work, we propose the first benchmark dataset to test the pure causal inference skills of large language models (LLMs). Specifically, we formulate a novel task Corr2Cause, which takes a set of correlational statements and determines the causal relationship between the variables. We curate a large-scale dataset of more than 400K samples, on which we evaluate seventeen existing LLMs. Through our experiments, we identify a key shortcoming of LLMs in terms of their causal inference skills, and show that these models achieve almost close to random performance on the task. This shortcoming is somewhat mitigated when we try to re-purpose LLMs for this skill via finetuning, but we find that these models still fail to generalize -- they can only perform causal inference in in-distribution settings when variable names and textual expressions used in the queries are similar to those in the training set, but fail in out-of-distribution settings generated by perturbing these queries. Corr2Cause is a challenging task for LLMs, and would be helpful in guiding future research on improving LLMs' pure reasoning skills and generalizability.
This is also great advice for any discipline, artistic or otherwise. Real, tangible career growth is as much about connecting with people who help motivate, mentor, and inspire as it is about honing the skills.
About 15 years ago, I stopped asking to work on specific films at ILM and instead started asking to work with specific PEOPLE.
Artists I knew I could learn from.
Nothing has boosted my career growth and job satisfaction more than that single conscious choice.
@paulg Remote work when well done is a superior management model.
Most of those companies never implemented key aspects of remote work like:
- async first communication
- documentation first approach
- proper feedback loops and performance review
@NickADobos@offtheblok There’s a great episode of Signals and Threads that seems to be the only serious treatment of this question I’ve seen on a podcast so far: https://t.co/PKB4rySoQw
@NickADobos@offtheblok GPT and similar models seem poor at understanding abstraction boundaries and how software systems should be designed at the level of modules or type theory. They’re going to push the human work into more of a kind of pair programming using rich specification languages (e.g. Agda)