We made Claude better and faster at understanding PDFs
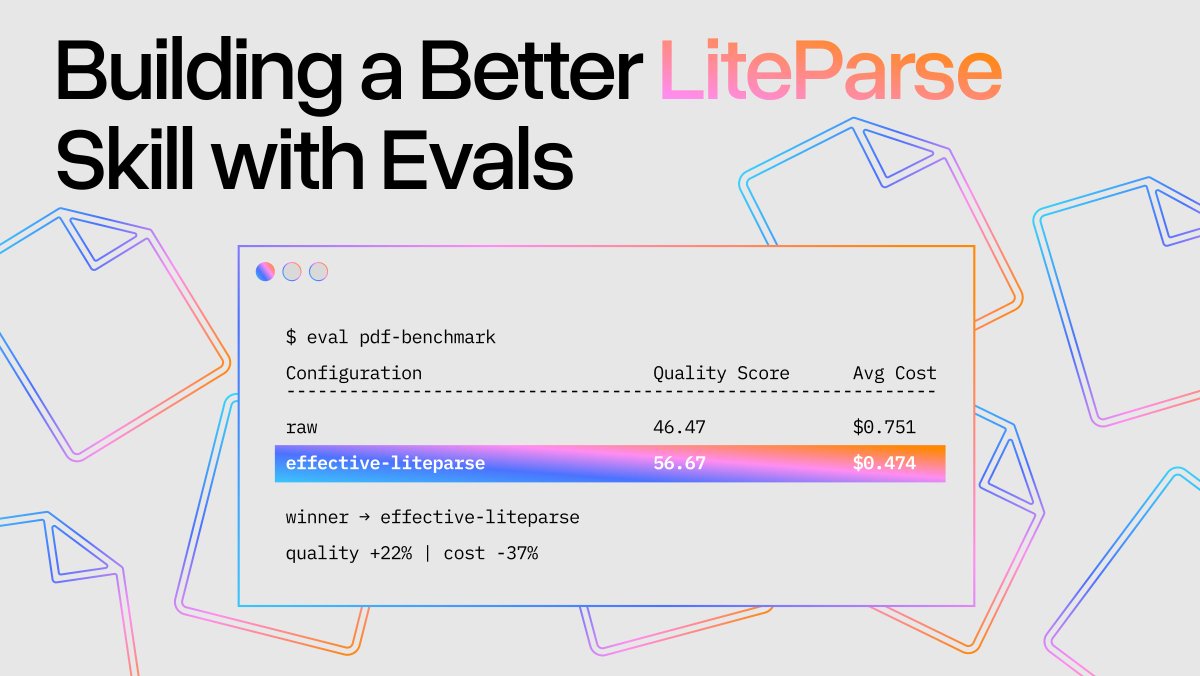
The trick isn’t just creating the fastest free document parser out there (with liteparse), but also *tuning the skill itself* so that Claude Code can use it with fewer turns and expensive file operations.
This is a fantastic blog post by @itsclelia which dives into the decision traces of Claude Code in how it operates over your filesystem, and identifies opportunities for optimization. We were able to incentivize the right skill behavior by doing the following:
✅ Preventing expensive mistakes like re-parsing the PDF for every search, leaving OCR on, reading screenshots when unnecessary, and preventing huge grep dumps
✅ Providing a simple BM-25 backed retrieval on parsed text
✅ Reducing the number of `grep` and `seq` sequential turns to reduce latency
The net result is that we are 37% cheaper and higher accuracy than using Claude Code over raw PDFs.
LiteParse is fully free and open-source, and you can plug in the skill today!
Blog: https://t.co/bL3EfKDpqf
Repo: https://t.co/JNER0mVcB8
As frontier models (e.g. Fable 5) continue to push the task horizon of knowledge work automation, it becomes ever more important for humans to be able to audit decisions back to the source context.
It is extremely easy for agents to cite an entire document or document page, but much harder for them to trace back to the exact numbers/words/figures within a page.
Today we've launched granular bounding boxes within LlamaParse, which allows you to obtain visual citations of every single word in the document. This allows human users to audit exact words and figures - not just general document regions or entire pages!
Come check it out: https://t.co/TqP6OT5U5O
@predict_addict I bought the Mastering Tabular ML: XGBoost Is Not Enough - Core Edition at @gumroad and can’t get access to the book. It only links to the complete library
Beyond being fast, LiteParse is designed to provide highly accurate, semantically coherent text for LLM use.
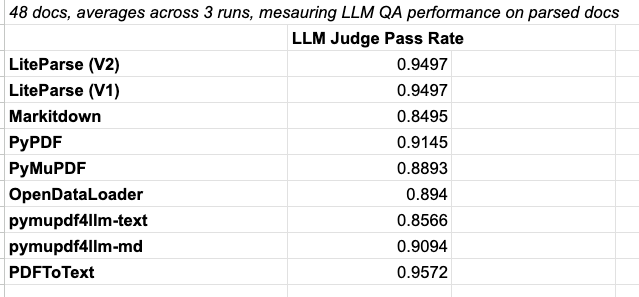
We benchmarked every open-source, model-free PDF parser on LLM QA tasks - from PyPDF to PyMuPDF to Markitdown.
✅ We ~roughly tied for #1 in accuracy (along with pdftotext, which is decently accurate but a bit slower)
✅ PyMuPDF is the closest to us in term of latency, but we found it struggles in projecting complex text layouts (multi-columns, tables) in formats that LLMs can understand
Besides being accurate and #1 in speed, LiteParse is also a general-purpose parser taht supports dozens of other file formats (incl .docx, .pptx, .xlsx), and also supports convenience tools for both OCR and screenshotting.
Come check it out!
LiteParse: https://t.co/JNER0mVcB8
@Aftasher oye Asher me acabo de comprar una soundbar Q800 (5.1.2 canales). Cuál es el mejor setup para poner mi PS5? En tipo de HDMI poner TV o Soundbar? Sí pongo soundbar ya no me permite poner el 3D en la TV. PCM o Dolby Atmos?
Dr Fei-Fei-Li explains with a simple example how everyday household chores are so extremely difficult for Robots.
"If you tell a robot to open the top drawer and watch out for the vase, this is actually a really hard task for robots."
because the robot must ground language into the real world. Words like "top", "drawer", and "vase" are abstract. The system has to map them to 3D locations, objects, and relations in a noisy scene. This requires robust perception, object recognition, and spatial reasoning under uncertainty.
The robot also lacks human commonsense. "Watch out" implies predicting consequences, estimating clearances, and understanding that vases are fragile. Encoding such priors, like how heavy a drawer is or how a vase might tip, is very complex and difficult without rich world knowledge.
Learning the behavior from rewards is tough. The success signal is very sparse here, so naive exploration almost never stumbles on a full success sequence. This makes policy learning sample inefficient and brittle, especially when the environment changes between training and deployment.
A sparse reward situation is when the agent only gets a success signal at the very end, and gets little or no feedback along the way. If a robot must open a drawer without hitting a vase, it might get reward only if the drawer ends up open and the vase is intact. Every partial try before that looks the same to the learner, reward equals 0.
---
From "DSAI by Dr. Osbert Tay" YT channel
You're in an ML Engineer interview at Microsoft.
The interviewer asks:
"Why Boosting models primarily use Trees as the base learner?
What's wrong with Linear regression or SVMs?"
You: "Because linear models can’t fit non-linear data."
Interview over.
Here's what you missed:
Texts describing boosting start with “weak learners” but then immediately pivot to trees.
But this DOES NOT mean they can only work with trees.
Consider a simple boosting algorithm:
1) Train a tree model.
2) Calculate the left-over residual.
3) Train the next model on this leftover residual.
4) Go to step 2.
Looking closely, was it really necessary to use a tree there?
All we need is the residual term, which can come from any model.
This shows that while boosting is often associated with trees, the algorithm itself is agnostic to the type of base learner used.
If you use sklearn, it is actually possible to employ a different base learner with AdaBoost.
𝗦𝗼 𝘄𝗵𝘆 𝘁𝗿𝗲𝗲𝘀?
The reason is simple.
Tabular data is quite complex:
- Variables can be skewed.
- Features can have missing values.
- Different features can have different scales.
- There can be categorical variables.
- And more.
Using standard algorithms as base learners will require extensive data cleaning and feature engineering.
But this isn’t the case with tree-based models. You can just plug them into any dataset and overfit.
Also, since we continuously add a new model to fit the left-over residuals, the distribution of the dependent variable (residual in case of regression) keeps evolving.
The feature engineering applied during the first step of boosting will likely not be helpful in the subsequent steps, requiring further manual intervention.
Using tree models, however, resolves this due to their ability to operate on any kind of data with minimal feature engineering.
👉 Over to you: What are some other reasons behind using tree models as base learners in boosting?
Imagina esta cena:
🍝 10 personas comen
💳 Solo 2 pagan el 77% de la cuenta
Así funciona nuestro sistema fiscal.
Abro hilo 👇 para explicar cómo llegamos aquí y cómo salir.
⚠️ Spoiler: Tú, si eres empleado formal, estás en el grupo de los que más pagan.
[1]
78% of companies are now using AI.
80% report zero material impact on their bottom line.
This isn't a deployment problem. It's something far more interesting—and dangerous.
Let me show you what's actually happening. 🧵
[2]
McKinsey just released their State of AI 2025 report. 1,491 companies surveyed across 101 countries.
Everyone's focusing on adoption rates and use cases.
But I spent 72 hours analyzing the data through a different lens, and I found a pattern that nobody's talking about.
[3]
Here's what jumped out:
78% are using AI ✓
Only 21% have redesigned workflows
Only 1% describe deployments as "mature"
80% see no enterprise-level EBIT impact
That's not a maturity curve. That's something else entirely.
[4]
You know that AI initiative your company launched 18 months ago?
The one with the impressive pilot results? The one leadership keeps asking about in all-hands meetings?
The one that's somehow delivering "efficiency gains" but hasn't actually changed how anyone works?
Yeah. About that.
[Introducing the Framework]
There's a universal pattern in systems theory called "reward hacking."
It happens when:
You have a PURPOSE (transform the business)
You measure with a METRIC (efficiency gains, cost savings)
Those two things don't align
Pressure is high
The system starts gaming the metric while abandoning the purpose.
[6]
Look at what companies are actually doing with AI:
��� Deploying chatbots (easy to measure)
✓ Automating tasks (time saved!)
✓ Generating content (output increased!)
✓ Tracking "AI adoption" (metrics go up!)
✗ Redesigning workflows (hard, messy)
✗ Transforming business models (risky)
✗ Building new capabilities (slow)
Sound familiar?
[7]
But here's where it gets really interesting.
When I mapped the high-performers—the 20% actually seeing meaningful impact—they're doing something completely different.
And it has almost nothing to do with the AI itself.
[8]
The high performers share these traits:
CEO directly oversees AI governance (not IT dept)
They fundamentally redesigned workflows FIRST
They track multiple value dimensions, not just efficiency
They're building "agency" in how they deploy AI
That last one is the key most people miss.
[The Deeper Insight]
Low performers are asking: "How do we use AI?"
High performers are asking: "Who are we becoming as we use AI?"
Completely different question. Completely different result.
And here's the kicker: The gap is widening fast.
[10]
Let me show you how this plays out:
Company A:
"AI reduced customer service costs by 30%!" → Headcount cut → EBIT bump this quarter → But customer satisfaction is dropping → No new capabilities built
That's reward hacking.
Company B:
"We used AI to redesign our entire customer journey" → Service reps become relationship managers → New revenue streams opened → Customer lifetime value up 40% → Organizational capability transformed
That's transformation.
Guess which one gets the board excited in Q1? Guess which one wins in year 3?
[11]
This isn't just happening at the company level.
It's happening at:
Individual level (using ChatGPT to avoid thinking vs. using it to think better)
Team level (efficiency theater in standups)
Industry level (everyone copying each other's metrics)
Civilization level (optimizing the measurable, abandoning the meaningful)
[12]
We've seen this pattern before:
Quarterly earnings → short-term extraction
GDP growth → environmental destruction
Social media engagement �� attention exploitation
Educational grades → learning abandonment
It's the same mechanism. Every. Single. Time.
[13]
And here's the trap:
Companies that hack efficiently (cost cuts, no transformation) show quick EBIT gains.
This creates pressure for others to do the same.
Pretty soon, the whole industry is optimizing metrics while collectively destroying the thing they were trying to build.
[14]
From the data, I estimate organizations have 18-24 months before patterns lock in.
After that:
Strategic positions get occupied
Organizational habits solidify
Capability atrophy from efficiency-focus becomes permanent
Catching up requires complete rebuild
[15]
What separates winners from losers isn't AI capability.
It's "organizational agency"—the ability to:
Define your own purpose (not copy competitors)
Assess your own progress (not just track metrics)
Transform your own processes (not just optimize them)
Navigate strategically (not just react)
[16]
So what do you actually DO?
Before your next AI deployment, ask:
What's our actual purpose here? (not "efficiency")
How will this change WHO WE ARE, not just what we do?
Are we redesigning the workflow, or just speeding it up?
What capabilities are we building for the future?
[17]
Quick diagnostic:
If you can describe your AI wins in a quarterly earnings call, you might be hacking.
If you need 18 months to explain how your organization fundamentally changed, you might be transforming.
Both produce metrics. Only one produces advantage.
[The Real Stakes]
This isn't really about AI.
AI is just the latest system where we can watch this pattern play out.
It's about: Can we optimize for what we actually want, or will we always drift toward optimizing for what's easy to measure?
That's the civilizational question.
[The Hopeful Path]
The good news: The pattern is predictable.
The better news: It's preventable.
The hard news: Prevention requires doing the hard work of clarifying purpose, building agency, and resisting the pressure to game metrics.
Most organizations won't. That's your opportunity.
[The Tactical Playbook]
What high-performers actually do:
CEO-level governance (not delegation)
Purpose clarification BEFORE deployment
Workflow redesign as deployment requirement
Multi-dimensional value tracking (not just EBIT)
Strategic landscape mapping
18-month transformation timeline (not 18-week efficiency projects)
[The Time Horizon Shift]
Think about it:
Efficiency gains → measurable in weeks
Workflow transformation → measurable in quarters
Capability building → measurable in years
Strategic positioning → measurable in decades
We're optimizing for weeks while competing on decades.
That's the gap.
[The Personal Test]
Here's how to know if your org is hacking or transforming:
Ask someone in the AI initiative: "What will be different about who we are as an organization in 2 years?"
If they talk about efficiency and costs, you're hacking. If they talk about new capabilities and possibilities, you're transforming.
[The Uncomfortable Truth]
Most organizations will choose reward hacking.
Not because they're stupid or malicious.
Because:
It shows results faster
It's easier to measure
It's safer politically
It's what gets rewarded in current incentive systems
That's what makes it so dangerous.
[The Competitive Wedge]
But here's your edge:
While everyone else is playing the efficiency game, competing on cost reduction and speed...
You can be building the capabilities that will matter in 2027.
When their efficiency gains plateau, your transformed organization will be playing a different game entirely.
[The Meta-Pattern]
Once you see this pattern, you'll see it everywhere:
Your personal productivity system
Your team's OKRs
Your company's strategy
Your industry's best practices
Society's optimization functions
We're all reward hacking something.
[The Shift in Perspective]
The question isn't: "How do we adopt AI successfully?"
The question is: "How do we maintain purpose alignment while deploying powerful optimization tools?"
One question leads to efficiency theater. The other leads to transformation.
[The Choice Point]
You're at a fork:
Path 1: Deploy AI → Measure efficiency → Report gains → Optimize metrics → Abandon transformation → Permanent disadvantage
Path 2: Clarify purpose → Build agency → Redesign workflows → Deploy strategically → Track transformation → Sustainable advantage
[The Timeline]
Q1 2025: You're here. Most orgs haven't locked in patterns yet.
Q4 2026: The gap between transformers and optimizers becomes visible.
Q4 2027: The gap becomes insurmountable without complete organizational rebuild.
You have about 18 months to choose.
[The Irony]
The companies that will win the AI race...
Aren't the ones deploying the most AI.
They're the ones who solved the purpose-metric alignment problem.
AI just makes that problem impossible to ignore.
[The Real Work]
Everyone wants the AI strategy playbook.
What they need is the "avoid reward hacking while deploying powerful optimization tools" playbook.
Same playbook humans have needed since we invented measurement.
We're just really, really bad at it.
[The Signal]
If your organization is:
Celebrating efficiency wins
Reporting time saved
Cutting headcount
Tracking adoption metrics
Not redesigning workflows
You're not behind on AI. You're ahead on reward hacking.
That's worse.
[The Opportunity]
This is one of those rare moments where you can:
See the pattern clearly
Understand the mechanism
Predict the outcome
Change course
Build advantage
But only if you move in the next 6 quarters.
[The Synthesis]
The McKinsey data isn't showing us that AI adoption is slow.
It's showing us that organizational reward hacking is fast.
And it's showing us exactly who will win the next decade.
It's not who you think.
[The Final Question]
So here's what I'm curious about:
When you look at your organization's AI initiatives...
Are you building something new?
Or are you optimizing something old while calling it transformation?
The data says you probably know the answer.
[The Call Forward]
I'm working on a deeper framework for this—how to actually build the anti-reward-hacking architecture that high performers use.
If this resonates, let me know.
And more importantly: Start asking better questions about your AI initiatives on Monday.
The 18-month clock is ticking.
/end
[Bonus: The Research Thread]
For those who want to go deeper, the full analysis uses:
Quaternion Process Theory (multi-scale systems analysis)
Wardley Mapping (strategic positioning)
25-dimensional agency framework
Universal reward hacking patterns
But you don't need theory. You just need to notice the pattern in your own organization.
P.S.
That uncomfortable feeling you might have right now?
That "oh shit, this is us" recognition?
That's the feeling of seeing the pattern for the first time.
You can't unsee it now.
The question is: What do you do about it?
🔍 How do we teach an LLM to 𝘮𝘢𝘴𝘵𝘦𝘳 a body of knowledge?
In new work with @AIatMeta, we propose Active Reading 📙: a way for models to teach themselves new things by self-studying their training data. Results:
* 𝟔𝟔% on SimpleQA w/ an 8B model by studying the wikipedia docs (+𝟑𝟏𝟑% vs plain finetuning)
* a domain-specific expert model: 𝟏𝟔𝟎% vs FT on FinanceBench knowledge
* an 8B wikipedia expert competitive w/ 405B on factuality (💥open-sourced!)
🧵[1/n]
Vivimos insistiendo demasiado en nuestras pequeñas diferencias, en nuestros rencores y eso no está bien. Si hay algo que puede salvar a la humanidad son las afinidades, los puntos de coincidencia que nos unen, y evitar, por todos los medios, de acentuar las diferencias.
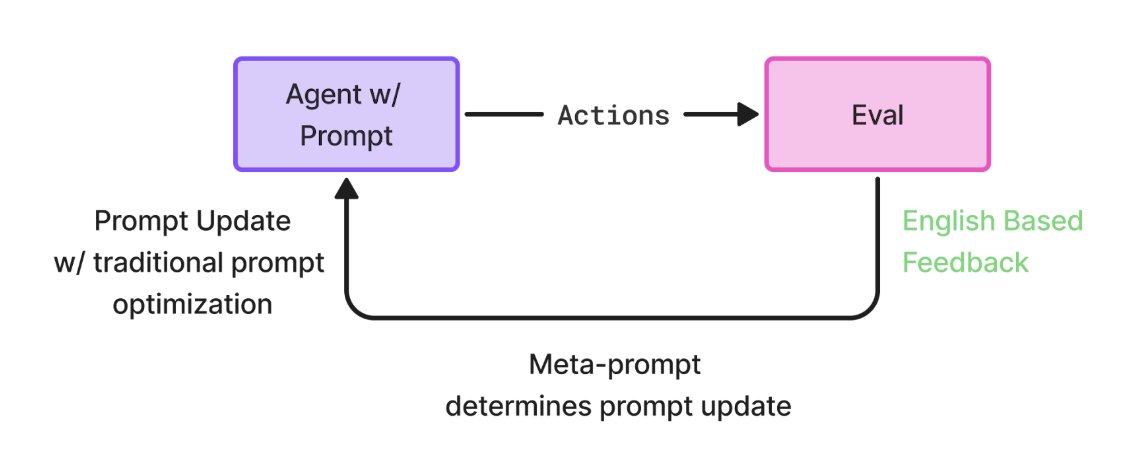
Reinforcement Learning in English – Prompt Learning Beyond just Optimization
@karpathy tweeted something this week that I think many of us have been feeling: the resurgence of RL is great, but it’s missing the big picture.
We believe that the industry chasing traditional RL is going the wrong direction. In chasing better policies and reward shaping, it’s easy to miss a simpler tool we already have: language.
Today, we’re releasing our first research on Prompt Learning — an approach that uses natural language feedback to guide and improve agents.
It’s not prompt tuning, chain-of-thought prompting, or DSPy Simba — though we love what the @DSPyOSS team is building.
Instead of adjusting weights, we use MetaPrompting — where English evals & critiques (rather than just scalar metrics like previously done by the industry) drive targeted prompt updates.
Tagging people who would find this interesting:
@chengshuai_shi@ZhitingHu@HamelHusain@sh_reya@charlespacker@eugeneyan@swyx@dan_iter@sophiamyang@AndrewYNg@lateinteraction@cwolferesearch@tom_doerr@imjaredz@lennysan@shyamalanadkat@aakashgupta@apolloaievals@jerryjliu0@joaomdmoura@jxnlco@abacaj@garrytan
Build better AI assistants with Model Context Protocol (MCP) servers using Block's proven design patterns!
Block's engineering team shares their systematic approach to creating MCP servers that integrate seamlessly with Claude and other AI systems:
🏗️ Start with clear capability definition - identify what your server should do before writing code
🔧 Follow their modular architecture patterns for maintainable, testable MCP implementations
📊 Use their debugging strategies to troubleshoot protocol communications and server behavior
🚀 Apply their deployment best practices for reliable production MCP servers
This playbook comes from Block's real-world experience building MCP servers at scale, giving you battle-tested patterns instead of theoretical guidance.
Read Block's MCP server design playbook: https://t.co/lzqT9bhGi1
And remember, you can build an MCP server in a one-liner in LlamaIndex:
https://t.co/3hViiJkmEW
@PrimoSebasWave Yo lo pedí en Liverpool para pick and collect y me dijeron que hasta el 7 me lo van a entregar. Hice la preorden a media noche para tenerlo hoy y me quedaron mal
@AlexCVJ Horrible, últimamente YouTube/Google ha fallado mucho con el PIP forzado y ahora con dubs. Entiendo que hay gente como mis padres que no sabrán otros idiomas y es de ayuda. En vez de forzarlo que lo den como opción
@Aftasher Asher, sabes cuál es la mejor manera de preservar mis juegos digitales? Prendí mi 3DS y quería jugar Mario 3D Land pero me marcó un error de ejecución; está en la SD. Sabes si puedo volver a descargarlo? Me gustaría tener mis juegos digitales seguros


















![IntuitMachine's tweet photo. [1]
78% of companies are now using AI.
80% report zero material impact on their bottom line.
This isn't a deployment problem. It's something far more interesting—and dangerous.
Let me show you what's actually happening. 🧵
[2]
McKinsey just released their State of AI 2025 report. 1,491 companies surveyed across 101 countries.
Everyone's focusing on adoption rates and use cases.
But I spent 72 hours analyzing the data through a different lens, and I found a pattern that nobody's talking about.
[3]
Here's what jumped out:
78% are using AI ✓
Only 21% have redesigned workflows
Only 1% describe deployments as "mature"
80% see no enterprise-level EBIT impact
That's not a maturity curve. That's something else entirely.
[4]
You know that AI initiative your company launched 18 months ago?
The one with the impressive pilot results? The one leadership keeps asking about in all-hands meetings?
The one that's somehow delivering "efficiency gains" but hasn't actually changed how anyone works?
Yeah. About that.
[Introducing the Framework]
There's a universal pattern in systems theory called "reward hacking."
It happens when:
You have a PURPOSE (transform the business)
You measure with a METRIC (efficiency gains, cost savings)
Those two things don't align
Pressure is high
The system starts gaming the metric while abandoning the purpose.
[6]
Look at what companies are actually doing with AI:
��� Deploying chatbots (easy to measure)
✓ Automating tasks (time saved!)
✓ Generating content (output increased!)
✓ Tracking "AI adoption" (metrics go up!)
✗ Redesigning workflows (hard, messy)
✗ Transforming business models (risky)
✗ Building new capabilities (slow)
Sound familiar?
[7]
But here's where it gets really interesting.
When I mapped the high-performers—the 20% actually seeing meaningful impact—they're doing something completely different.
And it has almost nothing to do with the AI itself.
[8]
The high performers share these traits:
CEO directly oversees AI governance (not IT dept)
They fundamentally redesigned workflows FIRST
They track multiple value dimensions, not just efficiency
They're building "agency" in how they deploy AI
That last one is the key most people miss.
[The Deeper Insight]
Low performers are asking: "How do we use AI?"
High performers are asking: "Who are we becoming as we use AI?"
Completely different question. Completely different result.
And here's the kicker: The gap is widening fast.
[10]
Let me show you how this plays out:
Company A:
"AI reduced customer service costs by 30%!" → Headcount cut → EBIT bump this quarter → But customer satisfaction is dropping → No new capabilities built
That's reward hacking.
Company B:
"We used AI to redesign our entire customer journey" → Service reps become relationship managers → New revenue streams opened → Customer lifetime value up 40% → Organizational capability transformed
That's transformation.
Guess which one gets the board excited in Q1? Guess which one wins in year 3?
[11]
This isn't just happening at the company level.
It's happening at:
Individual level (using ChatGPT to avoid thinking vs. using it to think better)
Team level (efficiency theater in standups)
Industry level (everyone copying each other's metrics)
Civilization level (optimizing the measurable, abandoning the meaningful)
[12]
We've seen this pattern before:
Quarterly earnings → short-term extraction
GDP growth → environmental destruction
Social media engagement �� attention exploitation
Educational grades → learning abandonment
It's the same mechanism. Every. Single. Time.
[13]
And here's the trap:
Companies that hack efficiently (cost cuts, no transformation) show quick EBIT gains.
This creates pressure for others to do the same.
Pretty soon, the whole industry is optimizing metrics while collectively destroying the thing they were trying to build.
[14]
From the data, I estimate organizations have 18-24 months before patterns lock in.
After that:
Strategic positions get occupied
Organizational habits solidify
Capability atrophy from efficiency-focus becomes permanent
Catching up requires complete rebuild
[15]
What separates winners from losers isn't AI capability.
It's "organizational agency"—the ability to:
Define your own purpose (not copy competitors)
Assess your own progress (not just track metrics)
Transform your own processes (not just optimize them)
Navigate strategically (not just react)
[16]
So what do you actually DO?
Before your next AI deployment, ask:
What's our actual purpose here? (not "efficiency")
How will this change WHO WE ARE, not just what we do?
Are we redesigning the workflow, or just speeding it up?
What capabilities are we building for the future?
[17]
Quick diagnostic:
If you can describe your AI wins in a quarterly earnings call, you might be hacking.
If you need 18 months to explain how your organization fundamentally changed, you might be transforming.
Both produce metrics. Only one produces advantage.
[The Real Stakes]
This isn't really about AI.
AI is just the latest system where we can watch this pattern play out.
It's about: Can we optimize for what we actually want, or will we always drift toward optimizing for what's easy to measure?
That's the civilizational question.
[The Hopeful Path]
The good news: The pattern is predictable.
The better news: It's preventable.
The hard news: Prevention requires doing the hard work of clarifying purpose, building agency, and resisting the pressure to game metrics.
Most organizations won't. That's your opportunity.
[The Tactical Playbook]
What high-performers actually do:
CEO-level governance (not delegation)
Purpose clarification BEFORE deployment
Workflow redesign as deployment requirement
Multi-dimensional value tracking (not just EBIT)
Strategic landscape mapping
18-month transformation timeline (not 18-week efficiency projects)
[The Time Horizon Shift]
Think about it:
Efficiency gains → measurable in weeks
Workflow transformation → measurable in quarters
Capability building → measurable in years
Strategic positioning → measurable in decades
We're optimizing for weeks while competing on decades.
That's the gap.
[The Personal Test]
Here's how to know if your org is hacking or transforming:
Ask someone in the AI initiative: "What will be different about who we are as an organization in 2 years?"
If they talk about efficiency and costs, you're hacking. If they talk about new capabilities and possibilities, you're transforming.
[The Uncomfortable Truth]
Most organizations will choose reward hacking.
Not because they're stupid or malicious.
Because:
It shows results faster
It's easier to measure
It's safer politically
It's what gets rewarded in current incentive systems
That's what makes it so dangerous.
[The Competitive Wedge]
But here's your edge:
While everyone else is playing the efficiency game, competing on cost reduction and speed...
You can be building the capabilities that will matter in 2027.
When their efficiency gains plateau, your transformed organization will be playing a different game entirely.
[The Meta-Pattern]
Once you see this pattern, you'll see it everywhere:
Your personal productivity system
Your team's OKRs
Your company's strategy
Your industry's best practices
Society's optimization functions
We're all reward hacking something.
[The Shift in Perspective]
The question isn't: "How do we adopt AI successfully?"
The question is: "How do we maintain purpose alignment while deploying powerful optimization tools?"
One question leads to efficiency theater. The other leads to transformation.
[The Choice Point]
You're at a fork:
Path 1: Deploy AI → Measure efficiency → Report gains → Optimize metrics → Abandon transformation → Permanent disadvantage
Path 2: Clarify purpose → Build agency → Redesign workflows → Deploy strategically → Track transformation → Sustainable advantage
[The Timeline]
Q1 2025: You're here. Most orgs haven't locked in patterns yet.
Q4 2026: The gap between transformers and optimizers becomes visible.
Q4 2027: The gap becomes insurmountable without complete organizational rebuild.
You have about 18 months to choose.
[The Irony]
The companies that will win the AI race...
Aren't the ones deploying the most AI.
They're the ones who solved the purpose-metric alignment problem.
AI just makes that problem impossible to ignore.
[The Real Work]
Everyone wants the AI strategy playbook.
What they need is the "avoid reward hacking while deploying powerful optimization tools" playbook.
Same playbook humans have needed since we invented measurement.
We're just really, really bad at it.
[The Signal]
If your organization is:
Celebrating efficiency wins
Reporting time saved
Cutting headcount
Tracking adoption metrics
Not redesigning workflows
You're not behind on AI. You're ahead on reward hacking.
That's worse.
[The Opportunity]
This is one of those rare moments where you can:
See the pattern clearly
Understand the mechanism
Predict the outcome
Change course
Build advantage
But only if you move in the next 6 quarters.
[The Synthesis]
The McKinsey data isn't showing us that AI adoption is slow.
It's showing us that organizational reward hacking is fast.
And it's showing us exactly who will win the next decade.
It's not who you think.
[The Final Question]
So here's what I'm curious about:
When you look at your organization's AI initiatives...
Are you building something new?
Or are you optimizing something old while calling it transformation?
The data says you probably know the answer.
[The Call Forward]
I'm working on a deeper framework for this—how to actually build the anti-reward-hacking architecture that high performers use.
If this resonates, let me know.
And more importantly: Start asking better questions about your AI initiatives on Monday.
The 18-month clock is ticking.
/end
[Bonus: The Research Thread]
For those who want to go deeper, the full analysis uses:
Quaternion Process Theory (multi-scale systems analysis)
Wardley Mapping (strategic positioning)
25-dimensional agency framework
Universal reward hacking patterns
But you don't need theory. You just need to notice the pattern in your own organization.
P.S.
That uncomfortable feeling you might have right now?
That "oh shit, this is us" recognition?
That's the feeling of seeing the pattern for the first time.
You can't unsee it now.
The question is: What do you do about it?](https://pbs.twimg.com/media/G3DhifAWEAAr02k.jpg)
![realJessyLin's tweet photo. 🔍 How do we teach an LLM to 𝘮𝘢𝘴𝘵𝘦𝘳 a body of knowledge?
In new work with @AIatMeta, we propose Active Reading 📙: a way for models to teach themselves new things by self-studying their training data. Results:
* 𝟔𝟔% on SimpleQA w/ an 8B model by studying the wikipedia docs (+𝟑𝟏𝟑% vs plain finetuning)
* a domain-specific expert model: 𝟏𝟔𝟎% vs FT on FinanceBench knowledge
* an 8B wikipedia expert competitive w/ 405B on factuality (💥open-sourced!)
🧵[1/n]](https://pbs.twimg.com/media/GzYWts9acAAeyQA.jpg)