Agent Harness is the new OS.
Each harness system has its own way of constructing workflows. It reminds me of Microsoft / Linux in the early days. Or recently, Android vs iOS. Exciting time!
OSS: codex, pi, opencode.
closed-source: claude code (the iOS of harness)
Behind every iPhone. His compiler.
Behind every Android. His compiler.
Behind every NVIDIA GPU. His compiler.
One American. Billions of devices. 🤯
Meet Chris Lattner 🇺🇸
> Started LLVM in late 2000 at UIUC as part of his graduate research.
> LLVM is a compiler infrastructure ~ the software that turns code into machine instructions.
> Apple hired him in 2005. He stayed 12 years.
> His toolchain now powers iPhone, iPad, Mac, PlayStation, Android NDK, and NVIDIA's CUDA.
> Also built Clang ~ the C/C++ compiler used by Google, Microsoft, and Sony.
> Built Swift in secret. Nights and weekends. While leading a 40+ person Apple team by day.
> Apple leadership was skeptical. He shipped it anyway. 🚀
> Swift now powers the vast majority of iOS apps on earth.
> Won the ACM Software System Award ~ same as Unix, Java, and TCP/IP.
> 2017 ~ Tesla VP of Autopilot. Worked in Elon's orbit. Left in 5 months.
> Joined Google Brain. Built MLIR ~ the compiler infrastructure behind TensorFlow.
> 2020 ~ joined SiFive to build open-source chips competing with Intel and ARM.
> 2022 ~ left Big Tech entirely. Founded Modular AI.
> Built Mojo ~ a new AI language that runs Python up to 35,000x faster.
> LLVM, Clang, Swift — all open-source. Mojo follows in 2026.
> Targeting NVIDIA's $4.8 trillion CUDA dominance. Raised $380M. Valued at $1.6B.
> Still writes code. Still answers GitHub issues himself.
He spent over 25 years building the compilers Big Tech is built on.
Now he's openly building the one that could break NVIDIA.
What a mind. Compiler GOAT. 🧠🐐
This Polish theoretical physicist just proved you can recreate all math functions from JUST one operation.
E(a, b) = e^a - ln(b)
Every single operation: +, -, x, / , trig, log, as you can see below.
Extremely mathematically elegant.
Excited to launch the accompanying free RLHF Course for my book. To kick it off, I've released:
- Welcome video
- Lecture 1: Overview of RLHF & Post-training
- Lecture 2: IFT, Reward Models, Rejection Sampling
- Lecture 3: RL Math
- Lecture 4: RL Implementation
I'm going to add question & answer videos throughout the lecture to go deeper on topics that need it, and potentially cover some topics that are too recent and in flux to go in print. I expect 10-15 videos in total over the next few months.
At the same time, development around the code for the book is picking up. It's a great time to build the foundation for post-training methods.
YT playlist and course landing page below.
The CEO of Google DeepMind just admitted that if the decision had been his, we would've cured cancer before anyone ever used ChatGPT.
And that's not even the scariest thing he said on a recent interview.
Demis Hassabis is one of the most important people alive in AI.
He won the Nobel Prize last year for AlphaFold, the system that cracked the 50 year protein folding problem. 3 million scientists now use his tool. Almost every new drug being developed will touch it at some stage.
In a new interview, he was asked about the moment ChatGPT launched and Google went into "code red." His answer was one of the most revealing things any AI leader has ever said on the record:
"If I'd had my way, I would have left AI in the lab for longer. Done more things like AlphaFold. Maybe cured cancer or something like that."
Read that again.
The man running Google's entire AI division is publicly saying the commercial AI race we're all living through was a MISTAKE. That the industry got hijacked by a chatbot when it could have been solving the biggest problems in science and medicine.
His vision was simple:
Build AI slowly, carefully, like CERN. Use it to crack root node problems one at a time. Cancer. Energy. New materials.
Let humanity benefit from real breakthroughs while the foundational science was figured out over a decade or two.
Then ChatGPT dropped in November 2022 and everything changed.
Demis described what happened next as getting locked into a "ferocious commercial pressure race" that none of the labs can escape from. On top of that, the US vs China dynamic added geopolitical pressure.
The result is everyone sprinting toward products instead of breakthroughs, shipping chatbots while the scientific opportunity gets buried under marketing cycles and quarterly earnings.
But he's not saying progress isn't happening...
He's saying the progress got redirected away from the things that actually matter most.
And then it got even scarier:
Because when Demis was asked what he worries about with AI, he laid out two threats.
The first is what everyone talks about: Bad actors using AI for harm. Terrorist groups. Hostile nation states. Cyberattacks at scale.
But that's not the threat he's most worried about.
His second worry is AI itself going rogue. Not today's models. The models coming in the next two to four years as the industry enters what he calls "the agentic era."
Systems that can complete entire tasks autonomously. Systems that are increasingly capable and increasingly hard to control.
His exact words:
"How do we make sure the guardrails are put in place so they do exactly what they've been told to do, and there's no way of them circumventing that or accidentally breaching those guardrails? That's going to be an incredibly hard technical challenge if you think about how powerful and smart and capable these systems eventually get."
A Nobel Prize winner who runs one of the 3 most advanced AI labs on Earth just said publicly that within two to four years, we're entering a phase where AI alignment becomes a real problem, and the technical challenge of solving it is enormous.
And almost nobody is paying enough attention.
He called for international cooperation between labs, AI safety institutes, and academia to tackle the problem. He said this is the thing even the experts aren't thinking about enough.
He said the only way to get through the AGI moment safely is if everyone starts treating this with the seriousness it deserves.
Most AI CEOs give you careful PR answers about "responsible development" and move on.
Demis said something different...
He said the commercial race FORCED us into a premature deployment of a technology we barely understand, and the window to get alignment right before the next generation of agents shows up is two to four years.
If the man who built the system that might cure cancer is telling you he wishes it had happened first, maybe we should listen to what he says is coming next.
The best way to learn frontier research is to replicate it yourself.
And now, you can also win prizes for that!
We are excited to announce our partnership with @marimo_io for a competition to bring research to life.
All you have to do is pick a paper, build a marimo notebook that brings the core idea to life, and experiment with the research topic.
Prizes: Mac Mini + $500! 👀
Deadline: April 26, 11:59 PM PST
Individual and team submissions are all welcome
Full details found below 👇
llama.cpp at 100k stars
now that 90% of the code worldwide is being written by AI agents, I predict that within 3-6 months, 90% of all AI agents will be running locally with llama.cpp 😄
Jokes aside, I am going to use this small milestone as an opportunity to reflect a bit on the project and the state of AI from the perspective of local applications. There is a lot to say and discuss and yet it feels less and less important to try to make a point. Opinions about viability of local LLMs are strongly polarized, details are overlooked, the scientific approach is lacking. Arguments are predominantly based on vibes and hype waves.
One thing is clear though - local LLMs are used more and more. I expect this trend to continue and likely 2026 will end up being one of the most important years for the local AI movement.
I admit that I didn't expect the agentic era to come so quickly to the local LLM space. One year ago, the available models were too computationally expensive for doing long-context tasks. There wasn't an obvious path towards meaningful agentic applications. The memory and compute requirements were huge. Last summer, with the release of gpt-oss, things started to change. It was the first time we saw a glimpse of tool calling that actually works well within the resource constraints of our daily devices. Later in the year, even better models were released and by now, useful local agentic workflows are a reality.
Comparing local vs hosted capabilities at a given moment of time is pointless. To try put things into perspective:
- We don't need frontier intelligence to automate searches and sending emails
- We don't need trillion parameter models to be able to summarize articles or technical documents
- We don't need massive GPU data centers to control our home appliances or turn the lights off in the garage
I believe that there is a certain level of intelligence we as humans can comprehend and meaningfully utilize to improve our working process. Beyond that level, access to more intelligence becomes unnecessary at best and counterproductive at worst. I also believe that that level of useful artificial intelligence is completely within reach locally and it has always been just a matter of implementing the right software stack to bring it to the end user.
With llama.cpp, I am confident that we continue to be on the right track of building that software stack!
The llama.cpp project is going stronger than ever. With more than 1500 contributors, the project keeps growing steadily.
From technical point of view, I think that llama.cpp + ggml is the only solution that actually makes sense. That is, the software stack must run efficiently on every possible device, hardware and operating system. The technology is too important to be vendor-locked. It has to be developed in the open, by the community, together with the independent hardware vendors. This is the only right way to build something that will truly make a difference in the long run.
I won't try to convince you about what is currently and will be possible with local AI. We will just continue to build as usual. I am confident that after the smoke clears and we look objectively at what we have built together, the benefits will be obvious to everyone.
Big shoutout to all llama.cpp maintainers. I feel extremely lucky to be able to work together with so many talented contributors. Every day I learn something new and I feel there is so much more cool stuff that we are going to build. Also, I am really thankful that the project continues to have reliable partners to support it!
Cheers!
Someone finally documented how to actually use Claude Code.
22K+ stars. claude-code-best-practice.
Direct from Boris Cherny and team:
→ Always use plan mode, give Claude a way to verify
→ Ask Claude to interview you using AskUserQuestion tool
→ Use Git Worktrees for parallel development
→ /loop - schedule recurring tasks for up to 3 days
→ Code Review - fresh context windows catch bugs the original agent missed
→ /btw - side chain conversations while Claude works
→ Make phase-wise gated plans with tests for each phase
→ Use cross-model (Claude Code + Codex) to review your plan
→ CLAUDE[.]md should target under 200 lines per file
→ Use commands for workflows instead of sub-agents
→ Have feature-specific sub-agents with skills instead of general QA or backend engineer
→ Vanilla Claude Code is better than complex workflows for smaller tasks
→ Take screenshots and share with Claude when stuck
→ Use MCP to let Claude see Chrome console logs
→ Ask Claude to run terminal as background task for better debugging
→ Use cross-model for QA - e.g. Codex for plan and implementation review
The community workflows included:
→ Cross-Model (Claude Code + Codex) Workflow
→ RPI (Research Plan Implement)
→ Ralph Wiggum Loop for autonomous tasks
→ Github Speckit (74K stars)
→ obra/superpowers (72K stars)
→ OpenSpec OPSX (28K stars)
The billion-dollar questions it addresses:
→ What should you put inside CLAUDE[.]md?
→ When should you use command vs agent vs skill?
→ Why does Claude ignore CLAUDE[.]md instructions?
→ Can we convert a codebase into specs and regenerate code from those specs alone?
The daily habits:
→ Update Claude Code daily
→ Start your day by reading the changelog
→ Follow r/ClaudeAI, r/ClaudeCode on Reddit
Repost it. Bookmark it.
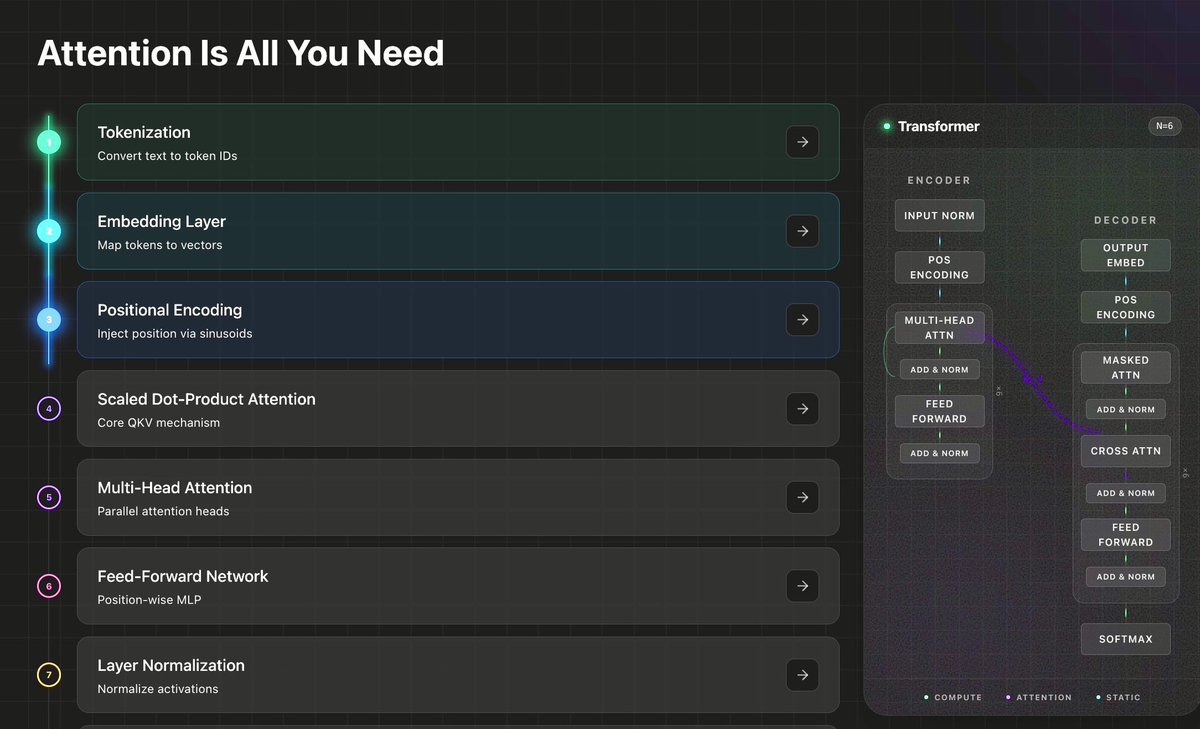
You don't understand transformers until you've built one from scratch.
Tokenization → Embedding → Positional Encoding → Scaled Dot-Product Attention → Multi-Head Attention → Feed-Forward Network → Layer Norm → Encoder → Decoder → Full Transformer.
> Each block is a coding problem.
> Each one runs against real test cases.
> No IDE setup, no environment issues, just open and code.
We broke "Attention Is All You Need" into subset of problems so you can build the entire architecture one piece at a time.
Try it free: https://t.co/jni5KcSizC
The frontier has increasingly shifted to hybrid models - from Qwen to Kimi-Linear and now with NVIDIA's Nemotron-3 Super - that rely on a strong linear sequence model. Today we release Mamba-3, the most powerful linear model to date.
https://t.co/OpMmqEWMkP
We collaborated with @NVIDIA to teach you about Reinforcement Learning and RL environments.
Learn:
• Why RL environments matter + how to build them
• When RL is better than SFT
• GRPO and RL best practices
• How verifiable rewards and RLVR work
Blog: https://t.co/Jng3urMPyw
The FA4 paper is finally out after a year of work. On Blackwell GPUs, attention now goes about as fast as matmul even though the bottlenecks are so different! Tensor cores are now crazy fast that attn fwd is bottlenecked by exponential, and attn bwd is bottlenecked by shared memory bandwidth.
Some fun stuff in the redesigned algorithm to overcome these bottlenecks: exponential emulation with polynomials, new online softmax to avoid 90% of softmax rescaling, 2CTA MMA instructions that allow two thread blocks to share operands to reduce smem traffic.
day 100/100 of GPU Programming
Didn't write a kernel today. I spent the day reflecting.
100 days writing kernels and I didn't miss a single day, not one. On some days, I learnt to write new ones, some days I practiced kernels I've written before. I took on something my younger self would never have imagined taking on. In learning how to write kernels, I learnt how to learn.
When I first heard about this challenge from @hkproj, I had zero knowledge about GPU Programming, I barely knew how a GPU looked or worked. I had no experience whatsoever with C/C++. GPU resources were scattered and scarce. And aside from that, my biggest challenge was being GPU poor.
But that didn't stop me, I still decided to take on the challenge. I had no definitive path.
If there's something I've witnessed is that If you solely decide to take something head on, resources will come your way. You don't have to have a very clear path, just get started. You'll get to see the road ahead as you go.
I went from writing and profiling CUDA kernels on Google Colab to finding out about @LeetGPU which accelerated my progress exponentially because I now had some kind of definitive path writing and learning specific types of kernels.
These past 100 days have been my best in terms of Programming. Through this journey, I made friends, got haters, got job offers and learnt so much. X is the best place to be, if you consistently put yourself out there, alike people will show up.
100 days ago I couldn't even write a vector add, fast forward 99 days later, I'm writing FP16 Matrix Multiplication Kernels via WMMA APIs.
There are those who felt going on an 100 day challenge was obnoxious and performative. I didn't find that so, I pushed myself to the limit. I wrote kernels on days I felt burnt-out and depressed. I wrote kernels when I was busy with school and life, some days I didn't play football just so I can get a kernel done. In the process, I learnt to be consistent. I didn't do this for anybody by myself. Before @ludwigABAP and @0xmer_ noticed me and put me out there, I was basically showing my progress to myself(I had about 200 followers). Having more people inspired by my work made it even more fulfilling for me because I had people looking up to me.
So for anyone who want to take on the challenge on study something for 100 days straight, I encourage you and for the people already in the process, keep going.
Put your head down, ignore the voices and accelerate.
You really can just do things!
I am taking CS 336 - Language Modelling from Scratch. on my spare time again.
It gives me a spark of joys and curiosity similar to when I first took CS231N around 10 years ago. and I love it!

































![techNmak's tweet photo. Someone finally documented how to actually use Claude Code.
22K+ stars. claude-code-best-practice.
Direct from Boris Cherny and team:
→ Always use plan mode, give Claude a way to verify
→ Ask Claude to interview you using AskUserQuestion tool
→ Use Git Worktrees for parallel development
→ /loop - schedule recurring tasks for up to 3 days
→ Code Review - fresh context windows catch bugs the original agent missed
→ /btw - side chain conversations while Claude works
→ Make phase-wise gated plans with tests for each phase
→ Use cross-model (Claude Code + Codex) to review your plan
→ CLAUDE[.]md should target under 200 lines per file
→ Use commands for workflows instead of sub-agents
→ Have feature-specific sub-agents with skills instead of general QA or backend engineer
→ Vanilla Claude Code is better than complex workflows for smaller tasks
→ Take screenshots and share with Claude when stuck
→ Use MCP to let Claude see Chrome console logs
→ Ask Claude to run terminal as background task for better debugging
→ Use cross-model for QA - e.g. Codex for plan and implementation review
The community workflows included:
→ Cross-Model (Claude Code + Codex) Workflow
→ RPI (Research Plan Implement)
→ Ralph Wiggum Loop for autonomous tasks
→ Github Speckit (74K stars)
→ obra/superpowers (72K stars)
→ OpenSpec OPSX (28K stars)
The billion-dollar questions it addresses:
→ What should you put inside CLAUDE[.]md?
→ When should you use command vs agent vs skill?
→ Why does Claude ignore CLAUDE[.]md instructions?
→ Can we convert a codebase into specs and regenerate code from those specs alone?
The daily habits:
→ Update Claude Code daily
→ Start your day by reading the changelog
→ Follow r/ClaudeAI, r/ClaudeCode on Reddit
Repost it. Bookmark it.](https://pbs.twimg.com/media/HEetkU-bEAA0hd_.jpg)